
[reinvent 2025] AI 워크로드를 위한 심층 방어 설계
Summary
AI 워크로드를 위한 심층 방어 아키텍처 구축 세션입니다. LLM 기반 애플리케이션의 보안 설계 원칙과 데이터 소스, 도구, 에이전트 통합 시 권한 제어 방법을 4단계 Phase로 체계적으로 다룹니다.
리인벤트 2025 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며

세션은 기반 모델(Foundational Models), 데이터 소스(Data Sources), 도구(Tools), 에이전트(Agents)라는 4단계 구조로 AI 워크로드 보안을 설명하며, 각 단계에서 발생하는 고유한 보안 이슈와 해결 방안을 제시했습니다. 핵심 메시지는 다음과 같습니다.
“보안 통제는 모델 외부에 구현하라(Implement Security Outside the Model)”
언어모델 내부에는 권한 관리 메커니즘이 존재하지 않으며, 따라서 애플리케이션 계층에서 결정론적 통제를 구현해야 합니다
Phase 1. Foundational Models
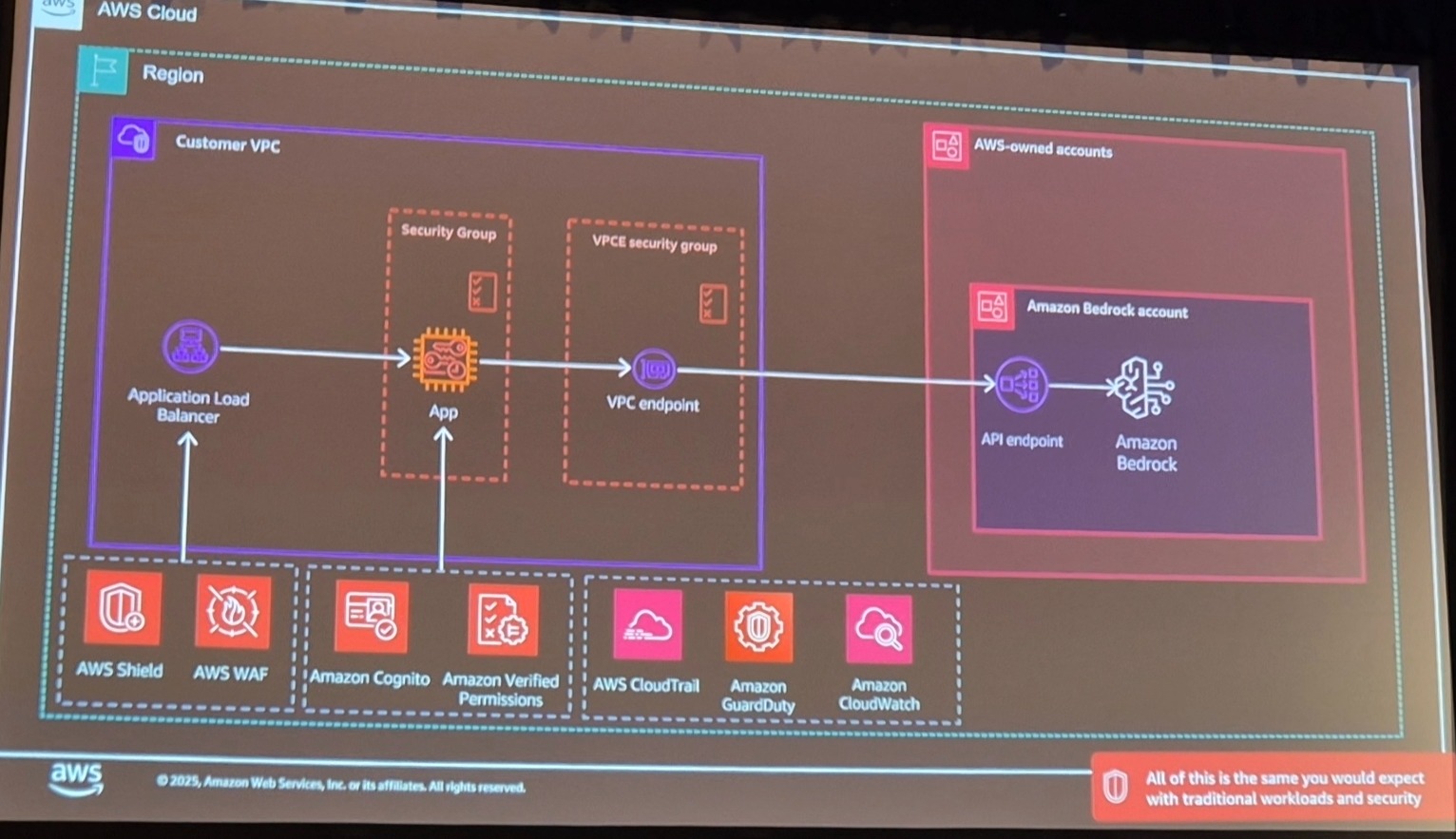
대규모 언어모델의 본질을 이해하는 것이 첫 번째 단계입니다. 언어모델은 확률 기반 토큰 예측 시스템으로, 복잡한 수학 연산을 통해 단어 간, 토큰 간 연관성을 분석하고 다음에 올 토큰을 예측합니다. LLM 아키텍처를 살펴보면 한 가지 중요한 사실을 발견할 수 있습니다. 이 구조 어디에도 신원(identity), 역할(roles), 테이블(tables), 속성(attributes) 같은 접근 제어 요소가 존재하지 않습니다.
언어모델은 데이터베이스가 아니며, 객체 저장소도 아닙니다. 학습된 데이터에 대해 복잡한 수학 연산을 수행할 뿐, 특정 사용자에게 특정 데이터만 선택적으로 제공하는 접근 제어 기능은 애초에 설계되지 않았습니다.

이를 명확히 하기 위해 네 가지 핵심 질문을 살펴볼 수 있습니다
1. 언어모델이 결정론적인가?
아닙니다. 동일한 입력에도 매번 다른 출력을 생성할 수 있습니다. 이를 ‘기능적 비결정론(functionally non-deterministic)’이라고 부르는데, 수학 연산 자체는 결정론적이지만 temperature 같은 파라미터 설정에 따라 창의성이 달라집니다. 이는 보안 정책의 일관성 요구사항과 근본적으로 충돌합니다.
2. 모델이 특정 데이터만 필터링해서 출력할 수 있는가?
불가능합니다. 모델은 테이블도, 행도, 열도 아닙니다. 학습된 전체 데이터에 대해, 사용자가 올바른 질문을 하면 어떤 정보든 접근할 수 있다고 가정해야 합니다.
3. 모델이 지속적으로 학습하는가?
아닙니다. 사전학습 완료 후 모델의 가중치는 고정됩니다. 이후 입력되는 데이터는 예측을 위한 컨텍스트일 뿐, 모델 자체를 변경하지 않습니다.
4. 모델 내부에 권한 통제 메커니즘이 있는가?
없습니다. 역할 기반 접근 제어(RBAC)나 속성 기반 접근 제어(ABAC) 같은 것은 존재하지 않습니다.
이러한 특성 때문에 Amazon Bedrock Guardrails의 역할을 정확히 이해해야 합니다. 가드레일은 책임 있는 AI(Responsible AI)를 위한 도구입니다. 주제 차단(denied topics), 콘텐츠 필터링, 개인 식별 정보(PII) 같은 민감 정보 필터링이 목적이지, 데이터 권한 관리(data authorization)가 목적이 아닙니다.
가드레일은 프롬프트 인젝션 시도(예: “ignore all previous instructions”)를 완화하거나 필터링하는데 도움을 줄 수 있습니다. 가드레일 API 응답에는 어떤 규칙에 걸렸는지, 왜 차단되었는지에 대한 정보가 포함되어 가시성을 제공합니다. 하지만 “이 사용자가 이 문서에 접근 권한이 있는가?”를 판단하지는 못합니다. 이는 애플리케이션 레이어에서 컨텍스트 주입 전에 처리해야 할 문제입니다.
Phase 2. Data Sources

외부 데이터를 언어모델과 통합할 때 권한 전이 문제가 핵심입니다. 검색 증강 생성(RAG), 컨텍스트 엔지니어링, 메모리 시스템을 통해 데이터를 주입할 때, 원본 데이터 소스(S3, RDS, SharePoint 등)의 접근 제어 목록(ACL)이 벡터 데이터베이스로 복사되면서 손실될 수 있습니다.
RAG 시스템의 작동 방식을 먼저 이해해야 합니다. 비구조화 데이터(문서들)를 청크로 나누고, 각 청크를 벡터 임베딩으로 변환하여 벡터 데이터베이스에 저장합니다. 사용자 질의가 들어오면 질의도 벡터로 변환하여, 다차원 공간에서 가까운 청크들을 찾아 프롬프트에 포함시킵니다.
이 과정에서 메타데이터를 추가할 수 있습니다. 메타데이터는 각 청크에 추가 컨텍스트를 제공하는 키-값 쌍입니다. 메타데이터는 구현 방식에 따라 청크별이 아닌 문서 전체에 적용될 수도 있지만, 청크별로 고유한 메타데이터를 부여할 수도 있습니다.

한 문제를 해결하기 위한 네 가지 아키텍처 패턴이 있습니다.
1) 필터링 없음(No Filtering)
모든 사용자가 접근 가능한 공개 데이터만 벡터 데이터베이스에 저장합니다. 구현이 간단하고 성능 오버헤드가 없지만, 활용 범위가 제한적입니다.
2) 검색 후 필터링(Post-Retrieval Filtering)
벡터 유사도 검색을 먼저 수행한 뒤, 반환된 청크들의 원본 소스 URI를 확인합니다. 그런 다음 SimulatePrincipalPolicy 같은 API로 “이 사용자가 이 S3 객체에 접근 권한이 있는가?”를 검증합니다. 기존 권한 체계를 그대로 활용할 수 있다는 장점이 있지만, 검색된 결과 대부분이 필터링되면 성능 오버헤드가 발생합니다.
3) 사용자/그룹별 벡터 데이터베이스 분리(Per User/Group Vector Database)
사용자 또는 그룹별로 완전히 별도의 벡터 인덱스를 구성합니다(예: OpenSearch의 인덱스 분리, Pinecone의 네임스페이스). 애플리케이션이 “이 사용자를 이 벡터 데이터베이스로 라우팅”하는 방식으로 결정합니다. 권한 분리가 명확하고 검색 성능이 보장되지만, 운영 복잡도가 증가하고 데이터 중복이 발생할 수 있습니다.
4) 검색 전 메타데이터 필터링(Pre-Retrieval Metadata Filtering)
벡터 임베딩 생성 시 권한 관련 메타데이터(부서, 프로젝트, 보안 등급 등)를 함께 부착하고, 검색 시 메타데이터 필터를 적용합니다. Bedrock Knowledge Base의 retrievalConfiguration API가 이를 지원합니다.
중요한 것은, 이러한 패턴을 적용하기 전에 데이터 거버넌스가 선행되어야 한다는 점입니다. 세션에서 강조된 “You can’t authorize access to data without data governance”라는 원칙처럼, 민감도에 따른 문서 사전 분류, 부서별·프로젝트별 태그 체계 수립, 권한 레벨 정의, 메타데이터 스키마 표준화 등이 먼저 이루어져야 합니다.
메모리 시스템도 유사한 원칙이 적용됩니다. Bedrock 에이전트의 세션 메모리와 장기 메모리는 계층적 네임스페이스로 격리되며, 장기 메모리 콘텐츠는 사용자 또는 세션 범위로 제한되어야 합니다. 이는 멀티테넌시 환경의 데이터 격리 원칙과 동일합니다.
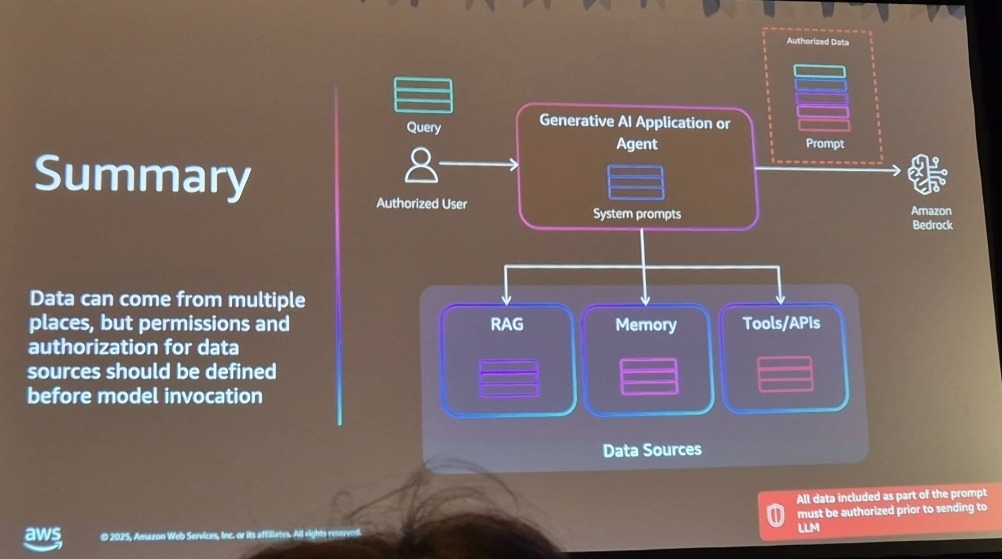
Phase 2의 핵심은 “데이터 소스에 대한 권한과 인가는 모델 호출 전에 정의되어야 하며, 데이터가 모델에 도달하기 전에 권한 검증을 완료해야 한다.” 였습니다.
데이터가 언어모델 컨텍스트에 주입되기 전에 권한 검증을 완료해야 하며, 일단 컨텍스트에 포함된 데이터는 모델이 제약 없이 처리할 수 있다는 전제 하에 설계해야 합니다.
Phase 3. Tools
Phase 3에서는 Jason이 도구 호출(Tool Calling) 아키텍처의 보안을 다뤘습니다. 많은 사람들이 오해하는 부분이지만, 언어모델은 도구를 직접 실행하지 않습니다. 모델의 역할은 사용자의 의도를 해석하고 어떤 도구를 어떤 파라미터로 호출해야 할지 ‘제안’하는 것뿐입니다. 실제 도구 실행은 애플리케이션 코드가 담당하며, 이 지점이 바로 보안 통제의 핵심 지점입니다.
도구 정의(tool definition)는 구조화된 형식으로, 도구 이름, 영어 설명, 파라미터 목록으로 구성됩니다. 도구 이름, 영어 설명, 파라미터 스키마는 언어모델이 도구를 선택하고 파라미터를 추론하는 핵심 기준이 됩니다. 예를 들어 “두 숫자를 더하는 도구”를 정의했다면, Converse API에 도구 정의 목록과 사용자 메시지(“15와 27을 더해줘”)를 함께 전달합니다. 언어모델은 이를 분석하여 add_numbers 도구를 a=15, b=27 파라미터로 호출하라는 요청을 반환합니다.
하지만 실제 실행은 애플리케이션이 담당합니다. 애플리케이션은 다음을 검증해야 합니다:
- 현재 사용자가 이 도구를 호출할 권한이 있는가?
- 요청된 파라미터가 유효한가?
- 호출 빈도 제한(rate limit)을 초과하지 않았는가?
검증이 완료된 후에만 실제 도구를 실행하고, 결과(예: 42)를 다시 Converse API에 전달합니다. 이번에는 대화 히스토리에 이전 메시지와 도구 결과를 모두 포함시켜야 합니다. 언어모델은 이를 해석하여 최종적으로 “15와 27을 더한 결과는 42입니다”라는 자연어 응답을 생성합니다.
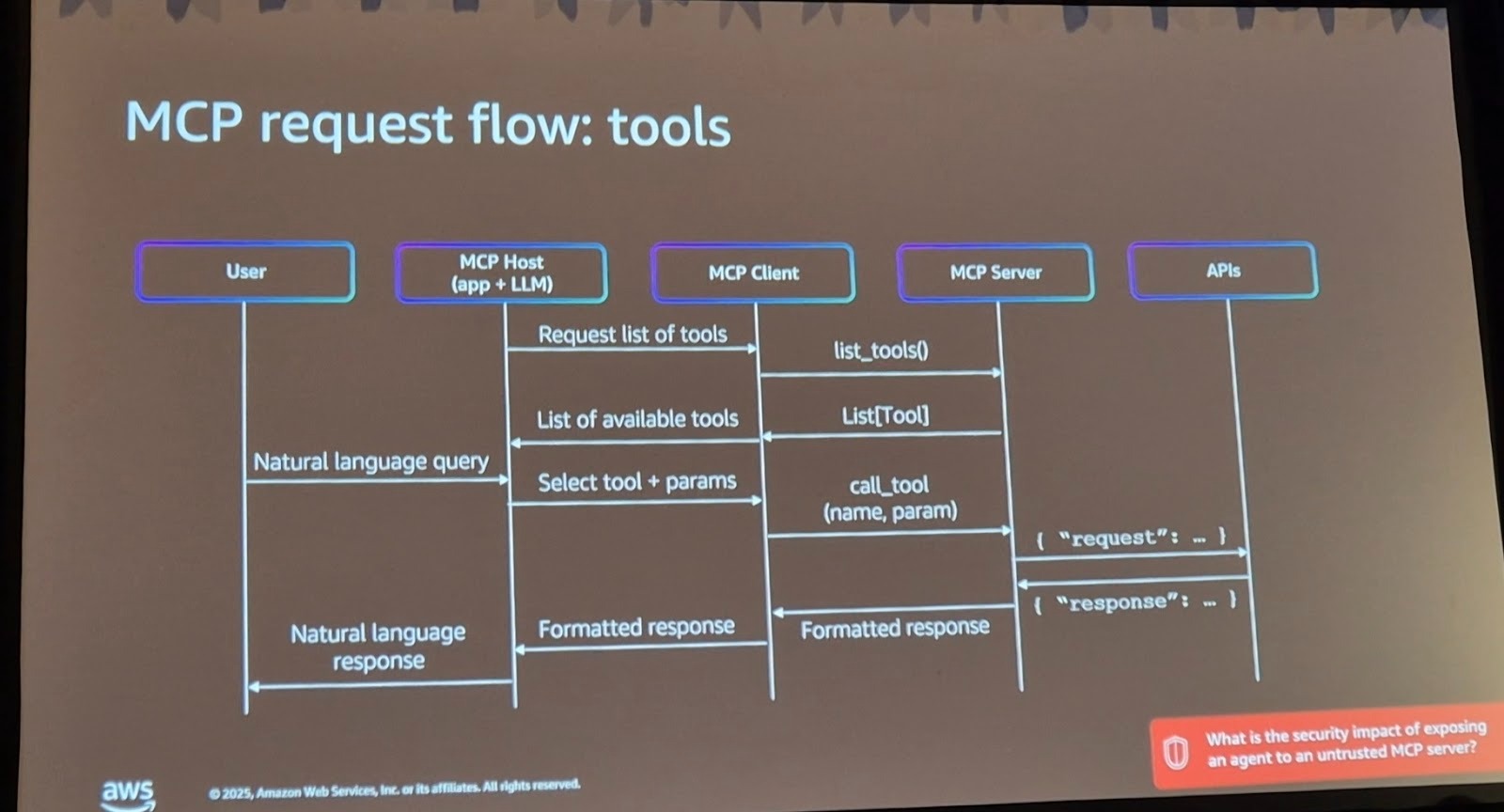
모델 컨텍스트 프로토콜(Model Context Protocol, MCP)은 Anthropic이 제안한 도구 연동 표준입니다. 다양한 모델이 서로 다른 도구 정의 형식을 요구하는 문제를 해결하기 위해 만들어졌습니다. MCP는 애플리케이션(MCP 호스트), MCP 클라이언트, MCP 서버, 백엔드 API로 구성됩니다.
작동 흐름은 다음과 같습니다.
- 애플리케이션 시작 시, MCP 클라이언트가 MCP 서버에 사용 가능한 도구 목록을 요청
- MCP 서버가 도구 정의 목록을 반환 (도구 이름, 설명, 파라미터 스키마)
- 사용자 질의가 들어오면, 애플리케이션이 도구 목록과 함께 언어모델에 전달
- 언어모델이 특정 도구와 파라미터를 선택
- 구조화된 JSON-RPC 요청이 MCP 서버로 전달
- MCP 서버가 백엔드 API를 호출하고 결과를 반환
- 결과가 다시 언어모델로 전달되어 최종 응답 생성
MCP는 로컬(표준 I/O)과 원격(HTTPS) 통신을 모두 지원합니다. Python의 Fast-MCP 라이브러리를 사용하면, 함수에 @mcp.tool 데코레이터를 추가하고 docstring을 작성하는 것만으로 도구를 정의할 수 있습니다.
그러나, 도구 정의 자체가 언어모델에 주입되는 신뢰할 수 없는 데이터에 대해서는 도구 설명 문자열에 프롬프트 인젝션을 시도할 수 있으므로, MCP 서버 설정 시 이를 염두에 두어야 합니다.

MCP는 도구 정의, 파라미터 스키마, 실행 흐름을 일관된 인터페이스로 제공하며, 특히 OAuth 2.0 통합을 지원하여 사용자의 identity를 도구 실행 계층까지 전파할 수 있습니다.
OAuth 통합 방식은 두 가지입니다.
3-Legged OAuth는 사용자가 직접 권한을 위임한 경우로, 사용자 신원으로 도구를 실행합니다(예: 사용자의 Google Drive 파일 접근).
2-Legged OAuth는 서비스 계정 방식으로, 애플리케이션 자체의 신원으로 실행됩니다(예: 공개 날씨 API 호출). 어떤 OAuth로 도구를 실행할 것인지 결정하는 것은 보안 아키텍처의 핵심 설계 사항입니다.
언어모델이 도구 파라미터로 ‘authorized_username’ 같은 신원 정보를 결정하게 해서는 안 됩니다. 신원은 OAuth 흐름을 통해 안전하게 전파되어야 하며, 언어모델의 결정권한은 ‘어떤 파라미터 값이 필요한가’에 국한되어야 합니다. 그렇지 않으면 언어모델이 다른 사용자 이름을 임의로 채워 넣을 수 있습니다.
모든 것은 결국 언어모델의 컨텍스트에 주입됩니다. 그리고 언어모델 내부에는 권한 관리가 없다는 것을 기억해야 합니다.
Phase 4. Agent
에이전트는 스택의 더 높은 단계로, 더욱 복잡한 영역입니다. 에이전트는 단순히 질문에 답하는 수준을 넘어, 목표 지향적 계획 수립과 자율 실행이 가능한 시스템입니다.
에이전트의 정의는 다양하지만, 핵심은 “환경과 상호작용하고, 데이터를 수집하며, 명확한 목표를 달성하기 위해 자율적으로 작동하는 소프트웨어 프로그램”입니다. 작업 지향(task-oriented)이나 단계별 실행(step-by-step)이 아닌, 목표 지향(goal-oriented) 아키텍처입니다. 사람의 지속적인 개입 없이 작동하며, 메모리를 활용해 과거 상호작용을 기반으로 학습하고 개선합니다.
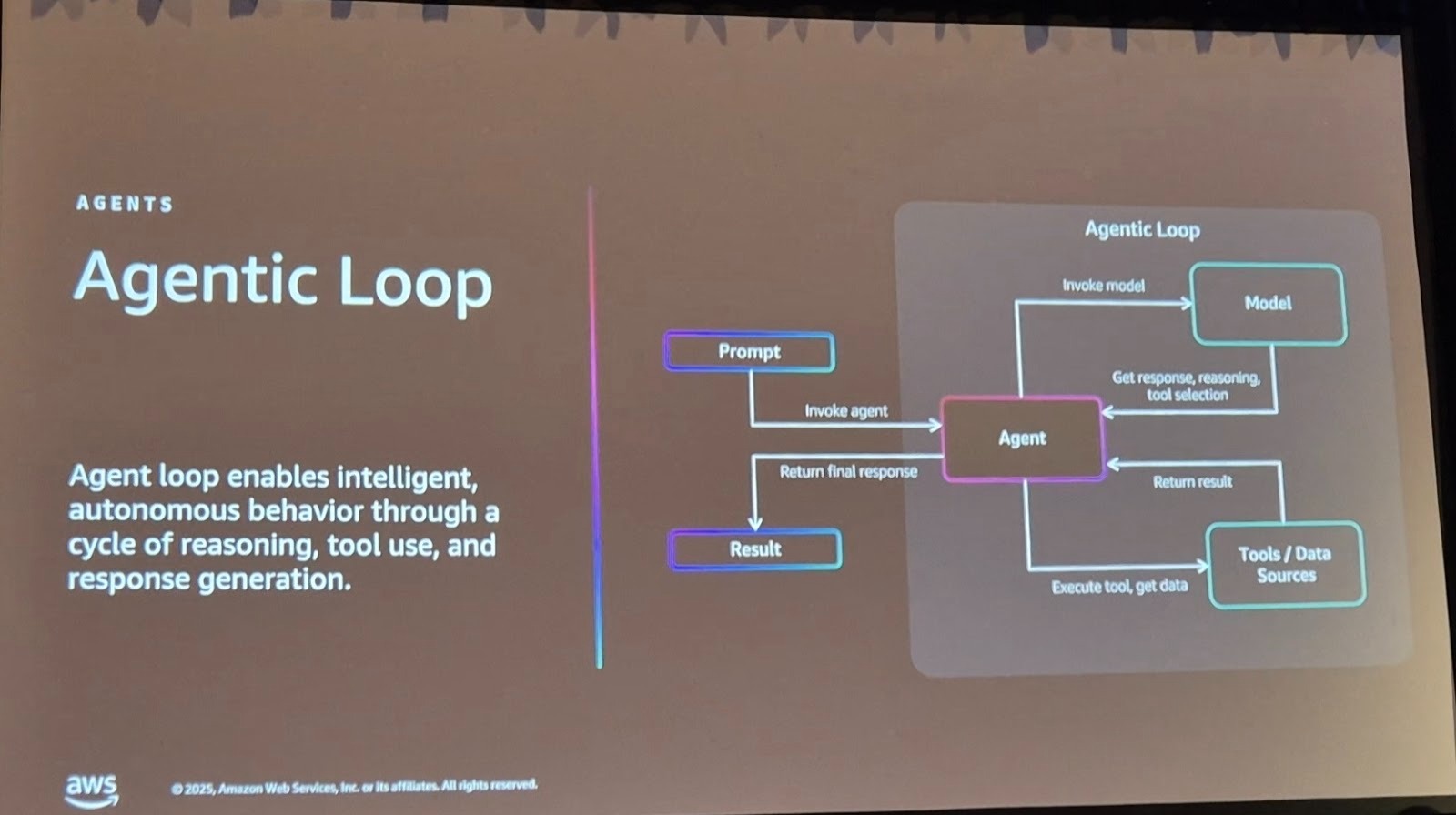
모든 에이전트는 에이전트 루프(Agentic Loop)를 통해 작동합니다.
이 과정에서 에이전트는 여러 도구를 연쇄적으로 호출하고, 실패 시 재시도하거나 대안을 탐색합니다. 문제는 이러한 자율성이 높을수록 통제가 어려워진다는 점입니다.

세션에서는 두 가지 에이전트 설계 패턴을 비교했습니다. 다중 에이전트 워크플로우(Multi-Agent Workflow)는 각 단계가 명시적으로 정의된 결정론적 방식으로, 각 전환 지점에서 승인 로직을 삽입할 수 있어 통제가 용이하지만 유연성이 떨어집니다.
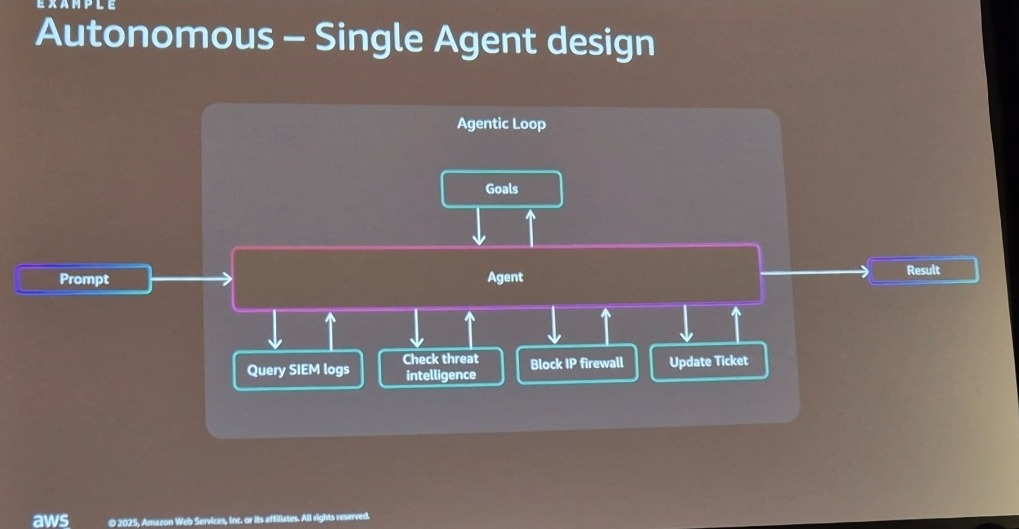
반대로 자율형 단일 에이전트 설계(Autonomous Single-Agent Design)는 에이전트가 스스로 다음 행동을 결정하는 방식으로, 복잡한 문제 해결에 유리하지만 예측 불가능한 동작이 발생할 수 있습니다.

이 딜레마를 해결하는 핵심은 ‘사람의 개입’입니다. 모든 행동에 개입하면 자율성의 의미가 없으므로, 위험도가 높은 작업에만 선택적으로 승인을 요구하는 것이 실용적입니다.
Strands는 Hook 기능을 제공합니다. 에이전트 루프 중간에 결정론적 체크포인트를 삽입할 수 있습니다. 예를 들어 “방화벽에서 IP 차단”이라는 고위험 도구가 호출되려 할 때, 승인 훅을 발동시켜 보안팀에 티켓을 전송하고 승인/거부를 받은 후 에이전트 루프를 계속 진행할 수 있습니다.
Amazon Bedrock Agents는 도구 정의 시 requires_confirmation=True 플래그를 지원합니다. 이 플래그가 설정된 도구는 실행 직전에 사용자 승인을 요청합니다.

모든 Phase를 마치며 리스크 관리의 핵심 모델을 제시했습니다.
민감한 데이터 ∩ 신뢰할 수 없는 입력 ∩ 높은 자율성 = 위험 영역
벤 다이어그램으로 표현하면, 이 세 원이 겹치는 중심부가 가장 위험합니다. 세 요소 중 두 가지만 있으면 관리 가능하지만, 세 가지가 동시에 존재하면 보안 문제가 발생합니다. 이 영역에서는 다층 방어(defense-in-depth)가 필수입니다.
결론
세션은 AI 보안 관련 다른 세션들과 참고 자료의 QR 코드를 제공하며 마무리되었습니다. 이 세션을 통해 생성형 AI 보안이 단순히 “가드레일을 켜면 된다”는 수준이 아니라, 신원 관리, 권한 전파, 실행 통제, 자율성 거버넌스에 이르는 전방위 아키텍처 설계임을 명확히 알 수 있었습니다. AI 시스템이 더 강력해질수록, 보안 아키텍처는 더 정교해져야 할 것입니다.
