
[reinvent 2025] Amazon S3 Glacier 스토리지 클래스를 통한 콜드 데이터의 가치 극대화
Summary
이 세션은 자주 액세스하지 않지만 장기간 보관해야 하는 ‘콜드 데이터(Cold Data)’를 단순한 저장 대상이 아닌 비즈니스 혁신의 자산으로 활용하는 방법을 다룹니다. 데이터의 무결성을 검증하는 새로운 기능과 자연어 쿼리가 가능한 기능을 통해, 아카이브 데이터를 효율적으로 관리하고 AI/ML 모델 학습 등에 활용하여 가치를 극대화하는 전략을 소개합니다.
리인벤트 2025 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며

아카이브 데이터 무결성 검증의 혁신: S3 Batch Operations – Compute Checksum

미디어, 생명 과학, 공공 기록물 등 규제 준수가 중요한 산업에서는 장기간 보관된 데이터가 변조되지 않았음을 증명하는 ‘무결성 검증(Fixity Check)’이 필수적입니다. 기존에는 S3 Glacier에 저장된 객체의 체크섬(Checksum)을 확인하기 위해 데이터를 복원(Restore) 하고 다운로드한 뒤, 별도의 컴퓨팅 인스턴스에서 계산해야 했습니다. 이는 막대한 전송 비용과 시간이 소요되는 작업이었습니다.
대규모 아카이브 데이터의 가시성 확보: Amazon S3 Metadata & Tables

이를 해결하기 위해 AWS는 Amazon S3 Tables를 활용한 새로운 메타데이터 관리 기능을 소개했습니다. 위 이미지에서 볼 수 있듯이, S3 버킷 내의 모든 변경 사항(PUT, DELETE, 메타데이터 업데이트 등)은 ‘Journal table’에 실시간으로 기록되고, ‘Live inventory table’을 통해 현재 상태를 즉시 파악할 수 있습니다. 이는 아카이브 데이터에 대한 기록 시스템(System of Record) 역할을 하여 관리의 편의성을 대폭 향상시켰습니다.
자연어와 SQL을 통한 손쉬운 데이터 쿼리 및 인사이트 도출
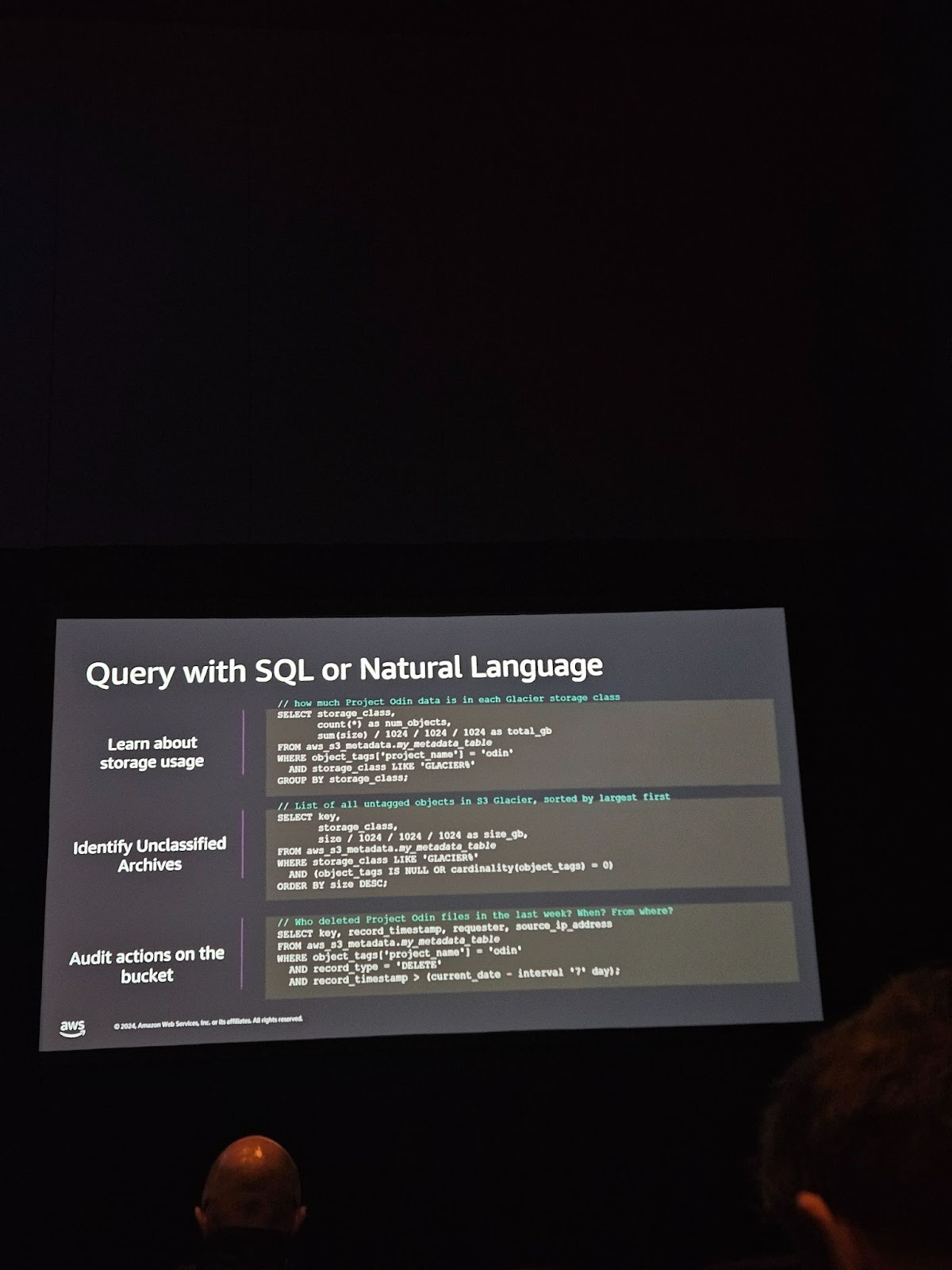
단순히 메타데이터를 저장하는 것을 넘어, 이를 얼마나 쉽게 활용할 수 있는지가 관건입니다. 이번 발표에서는 S3 Metadata에 대해 SQL 쿼리를 실행하거나, Amazon Q와 같은 AI 어시스턴트를 통해 자연어(Natural Language)로 질문하는 기능이 시연되었습니다.
예를 들어, 데이터 엔지니어가 아니더라도 “지난주에 프로젝트 오딘(Odin) 파일을 삭제한 사람이 누구야?” 또는 “태그가 없는 아카이브 파일 목록을 보여줘”라고 평범한 영어로 질문하면, 시스템이 자동으로 이를 해석하여 결과를 제공합니다. 이를 통해 운영 팀이나 컴플라이언스 팀은 복잡한 코딩 없이도 아카이브 데이터에 대한 즉각적인 인사이트를 얻고 의사결정을 내릴 수 있습니다.
결론

- 경쟁 우위 확보: 아카이브 된 데이터는 AI/ML 모델을 학습시키거나 튜닝하는 데 있어 독보적인 경쟁 우위가 됩니다.
- 비용 및 액세스 최적화: S3의 다양한 Glacier 스토리지 클래스(S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval, S3 Glacier Deep Archive)와 Intelligent-Tiering을 통해 액세스 패턴에 맞는 최적의 비용 구조를 만들 수 있습니다.
- 내장 기능 활용: 새롭게 추가된 Compute Checksum과 S3 Metadata 기능을 통해 데이터를 꺼내지 않고도 관리하고 가치를 추출할 수 있습니다.
과거에는 수십 년 된 데이터를 관리하는 것이 부담이었지만, 이제는 AWS의 도구들을 활용해 그 안에서 새로운 비즈니스 기회를 발굴할 수 있게 되었습니다. 특히 다운로드 없는 무결성 검증 기능은 미디어 및 금융권 고객들에게 즉각적인 비용 절감 효과를 줄 것으로 기대됩니다. 콜드 데이터 전략을 고민하는 분들께 유익한 세션이었습니다.
