
PoC를 넘어서, 금융권에서 ‘운영되는 생성형 AI’는 어떻게 만들어지는가

들어가며
최근 몇 년 사이, 금융권에서도 생성형 AI는 더 이상 낯선 기술이 아닙니다.
사규 요약, 규정 검색, 보고서 초안 작성, 질의응답 챗봇까지— “어디에 AI를 적용할 수 있을까”라는 질문은 이미 여러 차례 검토되었습니다.
실제로 많은 조직이 PoC 형태로 생성형 AI를 시험해 보았습니다. 짧은 시간 안에 그럴듯한 답변을 내놓는 AI를 보며, “이 정도면 충분히 쓸 수 있겠다”는 반응도 적지 않았습니다.
그러나 시간이 조금만 지나면, 분위기는 달라집니다.
- 시범적으로 사용되던 AI는 점점 활용 빈도가 줄어들고
- “이 답변을 그대로 써도 되는지”에 대한 불안이 남으며
- 결국 PoC는 조용히 종료됩니다.
흥미로운 점은, 실패의 원인이 모델 성능이나 기술 부족인 경우는 거의 없다는 것입니다.
대부분의 PoC는 이미 충분히 똑똑한 모델을 사용하고 있습니다. 문제는 전혀 다른 곳에서 발생합니다.
“이걸 실제 업무에 써도 되는가?”
“틀린 답이 나오면 누가 책임지는가?”
“감사나 준법 점검에서 이 결과를 어떻게 설명할 것인가?”
“데이터가 외부로 나가지 않는다는 걸 어떻게 보장하는가?”
이 질문들에 답하지 못하는 순간, 생성형 AI는 더 이상 ‘혁신’이 아니라 리스크로 인식되기 시작합니다.
그래서 금융권에서 생성형 AI의 성공 여부는 “얼마나 자연스럽게 말하는가”가 아니라, “얼마나 설명 가능하고, 통제 가능하며, 운영 가능한가”에 달려 있습니다.
이 글은 바로 그 지점에서 출발합니다.
- 왜 내부 문서 기반 AI는 생각보다 어려운지
- 왜 단순한 챗봇이 아닌 ‘지식 플랫폼’이어야 하는지
- 그리고 무엇이 갖춰져야 PoC를 넘어 실제 업무에 정착하는지
이번 사례는 생성형 AI를 새로운 기술로 소개하는 이야기가 아닙니다.
대신, 금융사 내부에서 사람에게 묻던 질문을 조직의 지식에게 묻게 되기까지, 그 과정에서 어떤 고민과 선택이 있었는지를 차분히 풀어보려 합니다.
이제부터 살펴볼 내용은 “AI를 도입했다”는 홍보 사례가 아니라, “AI가 업무의 일부가 되기 위해 무엇이 달라져야 했는가”에 대한 기록입니다.
그리고 그 변화의 출발점은, 의외로 단순한 한 문장에서 시작됩니다.
“문서는 많은데, 왜 우리는 여전히 사람에게 묻고 있을까?”
1) 고객 Pain Point : “검색은 되는데, 업무가 빨라지지 않는다”
① 문서가 너무 많고, 너무 흩어져 있다
금융사는 구조적으로 문서 중심 조직입니다.
사규, 인사/복지 규정, 리스크 기준, 심사 기준, 상품/가격 산정 기준, IFRS17 관련 기준과 보고서… 문서가 많다는 것은 문제가 아닙니다.
문서가 ‘업무 흐름과 연결되어 있지 않다’는 게 문제입니다.
- 어떤 문서는 DB에, 어떤 문서는 파일 서버에, 어떤 문서는 개인 폴더에 있습니다.
- 시스템은 여러 개고, 검색 창도 여러 개입니다.
- 그래서 사람들은 결국 “문서를 찾는 것”보다 “아는 사람을 찾는 것”이 더 빠릅니다.
② 키워드 검색은 “의도”를 못 따라온다
기존 검색은 대부분 키워드 기반입니다. 하지만 현업 질문은 키워드가 아니라 상황과 맥락으로 구성됩니다.
예를 들어 이런 질문입니다.
- “이 케이스는 예외 적용 가능한가요?”
- “이 조항이 다른 규정과 충돌하진 않나요?”
- “이 기준이 개정된 이후 적용 방식이 어떻게 바뀌었죠?”
키워드를 넣으면 ‘문서 목록’은 나오지만, 판단에 필요한 답은 여전히 사람이 읽고 정리해야 합니다.
③ “답변의 신뢰성”이 확보되지 않으면 운영에 못 올린다
생성형 AI가 아무리 자연스럽게 말해도, 금융권에서는 다음 한 줄이 없으면 사용할 수 없습니다.
“근거가 무엇입니까?”
- 어떤 조항을 근거로 했는지
- 어떤 문서를 참조했는지
- 문서에 없는 내용은 생성하지 않았는지
이게 담보되지 않으면 현업은 물론이고, 준법/감사/보안 조직도 동의하지 않습니다.
2) Solution
“사람에게 묻던 질문을, 내부 지식에게 묻는 구조로 바꾸다” 여기서 핵심은 “챗봇을 만든다”가 아닙니다.
정확히 말하면, 사내 지식을 ‘검색 가능한 형태로 재구조화’하고, 답변을 ‘근거 기반으로만 생성’하도록 강제하는 것입니다.
이를 위해 일반적인 “LLM 단독” 방식이 아니라, 금융권에서 운영 가능한 RAG(Retrieval-Augmented Generation) 구조를 채택합니다.
2-1. RAG가 왜 중요한가: “문서가 답변의 원천이 되게 만드는 방식”
RAG는 간단히 말해 다음 순서로 동작합니다.
- 사용자의 질문을 받는다
- 질문과 관련된 문서를 먼저 찾는다(검색)
- 찾은 문서를 근거로 답변을 생성한다(생성)
- 답변과 함께 “출처”를 제시한다
이 구조의 강점은 명확합니다.
- LLM이 “아는 척”할 여지가 줄어듭니다.
- 문서가 업데이트되면, 모델을 다시 학습하지 않아도 검색 결과가 바뀌면서 답이 바뀝니다.
- 무엇보다 “근거 제시”가 가능해져, 운영/감사/준법 관점에서 설명이 됩니다.
2-2. 기술 구성: 내부망에 맞춘 “완전 통제형” 구조
실제로는 다음 구성으로 설계됩니다.
- 문서 저장: Amazon S3
- ETL/정제/카탈로그: AWS Glue, Catalog
- 분석/연계(기존 데이터 기반): Redshift, Athena
- 검색/벡터 DB: OpenSearch (벡터 검색 포함)
- LLM 호출: Amazon Bedrock
- 운영/감사: CloudTrail, CloudWatch, 접근통제, Secrets Manager 등
특히 금융권에서 중요한 것은 “기술 스택”이 아니라 통제 지점입니다.
- 누가 어떤 문서에 접근했는지
- 누가 어떤 질문을 했는지
- 어떤 답이 생성되었는지
- 사용량과 비용이 어떻게 변하는지
이것들이 운영 레벨에서 관리되어야 “PoC가 아닌 시스템”이 됩니다.
2-3. 문서 전처리(청킹/임베딩)가 품질의 80%를 결정한다
현장에서 RAG 성능은 “모델 선택”보다 문서를 어떻게 쪼개고(청킹), 어떤 방식으로 벡터화(임베딩)했는가에 좌우되는 경우가 많습니다.
- 규정/사규: 조항 단위(목차 기반) 청킹이 유리
- 보고서/산출물: 페이지 단위 + 문맥 오버랩 필요
- 표/그림 포함 문서: 레이아웃 인식 옵션 적용 필요
여기서 중요한 운영 포인트는 하나입니다.
“문서가 늘어날 때마다 품질이 무너지지 않는 파이프라인”을 만들어야 한다.
즉, 전처리는 일회성 작업이 아니라 지속 운영되는 ‘지식 적재 파이프라인’이어야 합니다.
3) 실제 사용 시나리오
“확인하고 공유드릴게요”가 “조항 기준으로 가능합니다”로 바뀌는 과정, 이제 실제 사용 장면을 하나의 흐름으로 풀어보겠습니다.
시나리오 A: 사규/인사 규정 질의
과거
- 담당자가 규정집 PDF를 연다
- 검색 기능으로 키워드를 넣는다
- 여러 조항을 비교해 “아마 이 조항”을 찾는다
- 메신저/메일로 공유한다
→ 소요 시간은 짧아도 10~30분, 애매하면 더 길어집니다.
도입 후
- 사용자가 챗봇에 자연어로 질문
- 시스템이 관련 조항을 검색해 “근거 문서”를 붙여서 답변
- 답변에 “사규 ○○조, ○○페이지” 같이 출처가 함께 제공
- 사용자는 그 근거 링크를 그대로 공유
→ 질문-답변-공유까지가 “하나의 문장”으로 끝납니다.
핵심은 답변이 빨라졌다가 아니라, 근거가 함께 제공되어 커뮤니케이션 비용이 줄었다는 점입니다.
시나리오 B: IFRS17/프라이싱 기준 검토
IFRS17이나 가격 산정 기준은 단순 검색이 더 어렵습니다. 키워드가 맞아도 해석이 필요한 문장이 많고, 문서 간 연관도 큽니다. 도입 후에는 다음 변화가 큽니다.
- “관련 문서가 어디 있지?”가 아니라 “관련 문서들 중 어떤 조합이 답이 되는지”로 시선이 이동합니다.
즉, 문서 탐색 시간이 줄어들면서 사람은 더 상위의 판단(검토/승인/리스크 판단)에 시간을 쓰게 됩니다.
4) 결과 및 기대효과
“업무 효율”을 넘어, ‘조직 지식이 작동하는 방식’이 바뀐다, 성과를 숫자만으로 단정하기는 어렵지만(업무마다 기준이 다르기 때문), 현업에서 반복적으로 나타나는 변화는 꽤 일관됩니다.
4-1. 반복 질의/확인 업무가 줄어든다
- “어느 규정이 맞는지 다시 확인” 같은 재작업 감소
- 질문 자체가 줄어드는 경우도 많습니다.
(AI가 답을 주기 때문이 아니라, 근거가 남아서 같은 질문이 반복되지 않기 때문)
4-2. 특정 인력 의존도가 구조적으로 완화된다
기존에는 “문서를 잘 아는 사람”이 병목이었습니다.
도입 후에는 “문서를 찾고 근거를 공유하는 방식”이 표준화되면서 지식이 개인에게 묶이지 않습니다.
4-3. 준법/감사/보안 조직과의 대화가 쉬워진다
운영 가능한 AI에서 가장 중요한 것은 “설득 가능성”입니다.
- 답변 출처 제시(문서/조항/링크)
- 접근통제(사용자/그룹 단위)
- 로그/감사 대응(누가 무엇을 했는지)
- 비용/사용량 관리(폭증 방지)
이 요소가 갖춰지면, 현업뿐 아니라 통제 조직도 “이제 전사 확산을 논의할 수 있다”는 상태로 들어갑니다.
왜 AWS였는가: 기술 선택의 기준
금융권 내부망 환경에서 생성형 AI를 운영하기 위해서는 다음 조건이 필수였습니다.
- 내부 데이터가 모델 학습에 사용되지 않을 것
- 네트워크·보안·접근통제가 명확할 것
- 감사 시 설명 가능한 로그와 추적성이 확보될 것
- 비용과 사용량이 통제 가능할 것
이 조건을 충족하기 위해 AWS의 생성형 AI 스택이 선택되었습니다.
핵심 기술 구성
- LLM 서비스: Amazon Bedrock
- 문서 저장: Amazon S3
- 데이터 정제/적재: AWS Glue, Data Catalog
- 검색·벡터 DB: Amazon OpenSearch Service
- 접근 통제·감사: IAM, CloudTrail, CloudWatch, KMS
- 네트워크: VPC, VPC Endpoint, PrivateLink
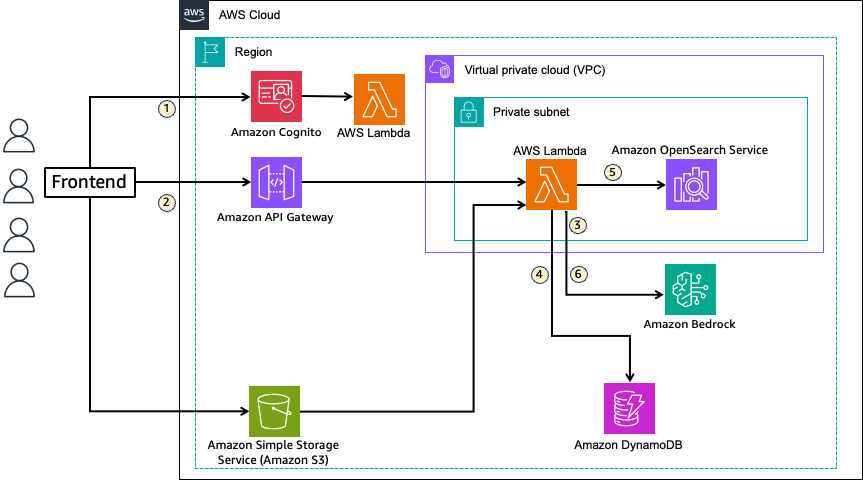
AWS를 선택한 이유는 단순히 “서비스가 많아서”가 아닙니다. 보안·감사·운영을 하나의 체계로 묶어 설명할 수 있었기 때문입니다.
도입 전 / 후, 실제 변화
| 항목 | 도입 전 | 도입 후 |
| 지식 탐색 | 사람에게 질문 | 시스템에 질의 |
| 답변 근거 | 경험·해석 | 문서·조항 기반 |
| 반복 업무 | 지속 발생 | 구조적으로 감소 |
| 인력 의존 | 특정 인력 집중 | 조직 자산화 |
| 감사 대응 | 설명 곤란 | 재현·추적 가능 |
| AI 인식 | 실험적 PoC | 운영 시스템 |
마무리: 내부망 생성형 AI의 목적은 “대체”가 아니라 “표준화”다
금융권에서 생성형 AI는 사람을 대체하는 도구가 되기 어렵습니다. 대신, 더 현실적으로 유효한 목표는 다음입니다.
- 조직 기준을 누구나 같은 방식으로 참조하게 만들기
- 근거 기반 답변을 표준화하여, 커뮤니케이션 비용을 줄이기
- PoC가 아닌 운영 가능한 시스템으로 만들기
문서가 많은 조직일수록, AI의 가치는 “말을 잘하는 능력”이 아니라 지식을 ‘작동 가능한 형태’로 바꾸는 능력에서 드러납니다.
※ This project was executed by MegazoneCloud as a member of the Partner Innovation Alliance within the AWS Generative AI Innovation Center (GenAI IC), with strategic funding and support provided by the GenAI IC PLD funding program.
