본 인터랙티브 세션에서는 참가자들과 협력하여 AWS Trainium 및 Inferentia 칩에서 vLLM을 사용하여 LLM 서빙을 최적화하는 방법을 탐구합니다. 화이트보드와 실습 토론을 통해 효율적인 배포 패턴을 설계하고, 일반적인 성능 병목 현상을 해결하며, 확장 가능한 서빙 구성을 함께 디자인합니다. 실제 시나리오를 바탕으로 코드 예시와 구성 모범 사례를 검토하며, AWS AI 칩에서 vLLM의 기능을 깊이 있게 이해하고 질문과 과제를 해결합니다.
AWS re:Invent 2025 Tech Blog written by MegazoneCloud
Overview
Title: Deploying LLMs at scale with vLLM on AWS AI chips
Date: 2025년 12월 2일 (화)
Venue: MGM | Level 3 | Room 353
Speaker:
Yahav Biran (Principal Architect, AWS)
Pinak Panigrahi (Annapurna ML, AWS)
Industry: Software and Internet
vLLM과 AWS Tranium을 활용한 대규모 LLM 배포 전략
세션 개요
이번에 참석한 “How to Deploy LLMs at Scales with vLLM and Trinium AWS/Inferentia chips” 세션은 2024년이 PoC에서 생산 환경으로 전환되는 해가 되면서, LLM 배포 시 예측 가능한 성능, 레이턴시, 가용성, 그리고 비용 효율성을 확보하는 방법을 다뤘습니다. AWS의 맞춤형 실리콘인 Tranium 및 Inferentia 칩에서 vLLM 같은 최신 서빙 프레임워크를 사용하여 LLM을 대규모로 배포하고 최적화하는 방법을 심층적으로 다룬 세션이었습니다.
이기종 하드웨어 환경에서의 일관된 배포 경험
LLM을 생산 환경에 배포할 때 가장 중요한 목표는 하드웨어 플랫폼에 관계없이 예측 가능한 성능과 운영의 일관성을 확보하는 것입니다.
하드웨어 추상화 및 소프트웨어 스택의 일관성
AWS는 고객이 GPU(L4t, G6e 인스턴스)와 AWS Inferentia/Tranium 인스턴스 등 이기종 하드웨어에 동일한 LLM 애플리케이션을 배포하고 실행할 수 있는 능력을 강조했습니다. 동일한 vLLM 프레임워크와 소프트웨어 스택을 사용하며, 코드 변경이나 추가 구성 없이 바로 작동하도록 설계되었습니다.
vLLM은 높은 처리량, 낮은 레이턴시, 효율적인 KV 캐시 관리를 지원하는 인기 있는 LLM 서빙 프레임워크인데, Neuron Distributed Inference Library를 통한 플러그인 방식으로 Tranium 및 Inferentia를 지원합니다.
성능 최적화 기술
LLM 배포에서 성능 지표(TTFT, Time-To-First-Token 및 스루풋)와 비용은 항상 상충하는 트레이드오프 관계입니다. AWS는 다양한 병렬화 기법과 혁신적인 디코딩 기술을 통해 이 문제를 해결합니다.
텐서 병렬 처리(Tensor Parallelism, TP)
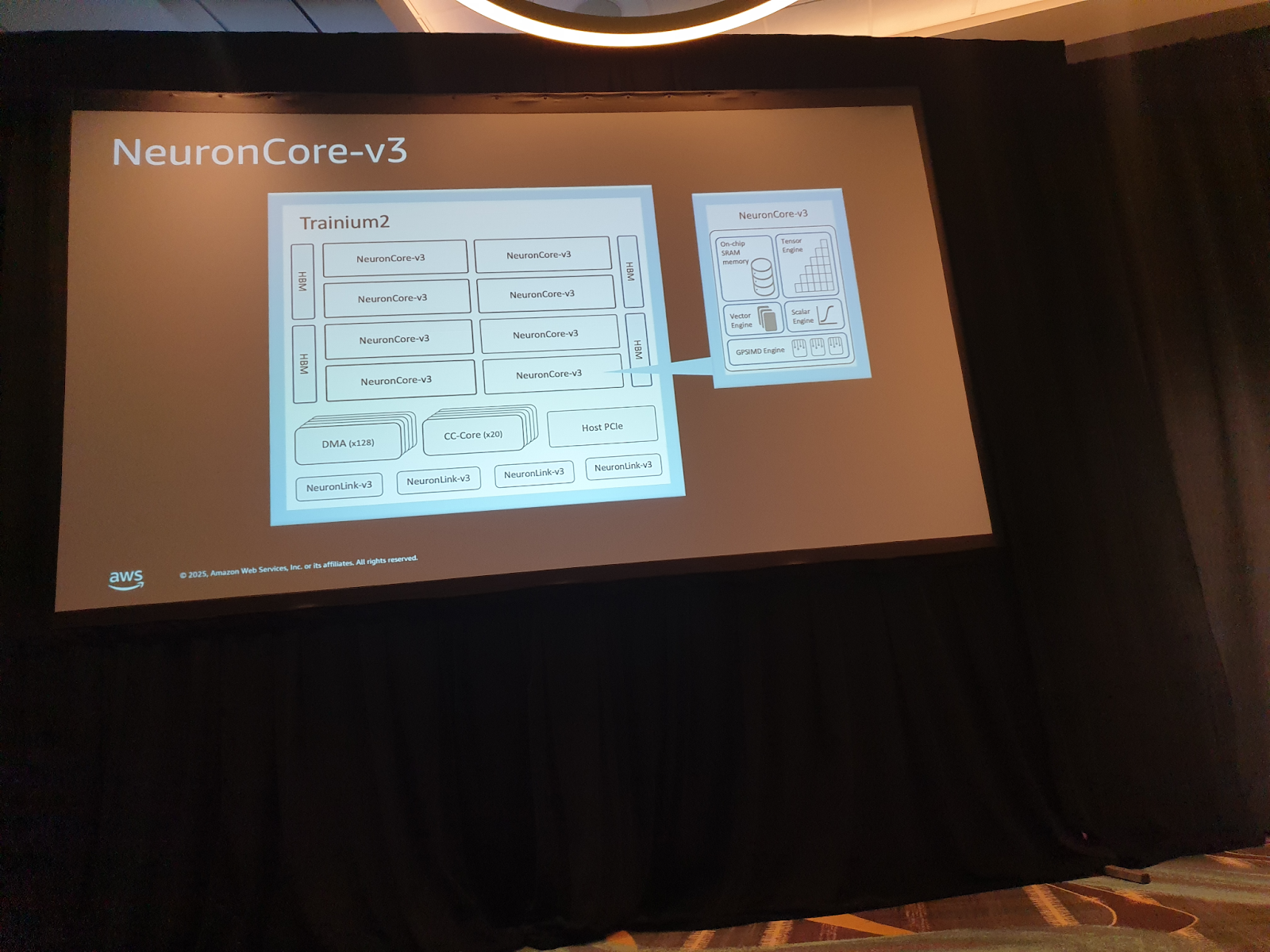
모델 레이어를 여러 장치(Neuron Core)에 분할하여 배치합니다. TP Degree를 증가시키면 처리할 수 있는 모델 용량이 늘어나지만, 코어 간의 통신 오버헤드로 인해 특정 지점부터는 성능 개선 효과가 병목 현상으로 상쇄될 수 있습니다. 최적의 TP 수준은 모델 크기, 시퀀스 길이 등에 따라 달라지므로 직접 실험이 필요합니다. Tranium 칩은 여러 개의 뉴런 코어로 구성되며, 각 코어는 다양한 연산을 수행하는 전문화된 엔진을 갖추고 있습니다.
향상된 관측성(Observability)과 로컬 부트(Local Boot)
분리형 추론(DI)은 prefill과 decode 두 단계로 나뉘며, 각각 요구사항이 다릅니다. prefill은 질문을 이해하는 단계로 컴퓨팅 바운드이며, decode는 답변을 생성하는 단계로 메모리 대역폭 바운드입니다. DI는 이 두 단계를 별도의 서버로 분리하여 각 부분을 독립적으로 최적화함으로써 전체 스루풋을 증가시킵니다.
AWS의 DI가 가지는 이점은 EFA(Elastic Fabric Adapter)를 적극 활용한다는 점입니다. 고속 네트워킹을 사용하여 prefill 서버에서 decode 서버로 KV 캐시를 전송할 때 발생하는 네트워킹 병목 현상을 해결합니다. EFA는 가용 영역 내에서 사용 시 무료이며 빠릅니다. 또한 Zero Copy 기술로 KV 캐시를 CPU를 거치지 않고 디바이스에서 디바이스로 직접 복사하여 전송 속도를 더욱 향상시킵니다.
추측성 디코딩(Speculative Decoding, SD)
더 작고 빠른 Draft Model을 사용하여 메인 모델이 생성할 토큰을 예측하게 하고, 메인 모델은 이를 검증하는 방식으로 속도를 높입니다. 예측이 메인 모델과 일치할 경우 높은 스루풋을 얻지만, 예측이 자주 실패할 경우 성능 개선이 미미하거나 오히려 낮아질 수 있습니다.
LLM 배포의 운영 유연성 및 Kubernetes 통합
Kubernetes와의 통합 및 Artifact 관리
LLM을 대규모로 배포하고 관리하는 데 있어 Kubernetes와의 통합은 필수적입니다. 그래프 모드에서는 모델 컴파일이 필수적이며, 컴파일된 아티팩트는 S3에 저장되고, CSI 드라이버를 통해 이 S3 버킷이 마치 파일 시스템처럼 마운트됩니다. Pod를 시작할 때 이미 컴파일된 아티팩트가 있으면 캐시에서 로드하고, 없으면 컴파일을 수행합니다. 이는 스케일링 시 컴파일 시간에 의존하지 않도록 합니다.
결론 및 소감
AWS는 Tranium 및 Inferentia를 통해 LLM 배포의 성능과 비용 효율성이라는 두 마리 토끼를 잡고자 합니다. vLLM과의 깊은 통합은 GPU를 사용하던 고객들에게 코드 변경 없는 마이그레이션 경로를 제공하며, 운영상의 복잡성을 크게 줄입니다.
가장 중요한 인사이트는 “하나의 솔루션이 모든 것에 최적인 것은 없다”는 점입니다. LLM 워크로드는 매우 역동적이므로, TTFT를 개선할 때는 DI를, 결정론적 작업의 스루풋을 높일 때는 SD를 고려하는 등, 워크로드 특성에 따라 다양한 최적화 기법을 실험하고 조합해야 합니다.
이러한 접근 방식은 예측 가능한 낮은 레이턴시와 높은 스루풋을 저렴한 비용으로 요구하는 대규모 LLM 서비스 제공업체나, 특정 GPU 공급업체에 묶이지 않고 다양한 하드웨어에서 동일한 소프트웨어 스택을 사용하고자 하는 조직에게 큰 도움이 될 것입니다.