Amazon SageMaker의 Zero-ETL 통합 및 쿼리 페더레이션(Query Federation) 기능을 통해 중요하지 않은 운영 부담(Undifferentiated Heavy Lifting)에 소요되는 시간을 줄이고 데이터 제품 구축에 더 많은 시간을 할애할 수 있습니다. 본 실습 워크숍은 SageMaker Catalog를 사용하여 Zero-ETL 파이프라인 및 페더레이션 쿼리를 구축하는 방법을 탐색하고, Amazon SageMaker를 통한 레이크하우스 아키텍처의 강력한 기능을 시연합니다. 데이터 수집 및 외부 데이터 소스 쿼리 과정을 간소화하는 실질적인 경험을 제공하여, 이러한 기술이 통찰력 확보 시간을 어떻게 가속화하는지 보여줄 것입니다.
AWS re:Invent 2025 Tech Blog written by MegazoneCloud
Overview
Title: Getting hands on with zero-ETL and data federation
Date: 2025년 12월 1일 (월)
Venue: MGM | Level 3 | Room 304
Speaker:
Nidhi Nayak (Senior Technical Account Manager, Amazon Web Services)
Industry: Software and Internet
Amazon SageMaker Generation AI 시대의 Zero ETL 및 데이터 통합
워크숍 개요
이번에 참석한 “Zero ETL and Data Integration in the Age of Generation AI with Amazon SageMaker” 워크숍은 전통적인 ETL 프로세스의 한계를 극복하고 SageMaker Unified Studio를 활용한 새로운 데이터 통합 방식을 실습하는 세션이었습니다. 데이터 파이프라인 구축 시 직면하는 어려움들을 해결하고, AI/ML 애플리케이션 개발을 가속화하는 방법을 다뤘습니다.
전통적인 ETL의 한계
전통적인 조직들은 운영 데이터베이스에서 분석 시스템으로 데이터를 옮기기 위해 ETL 프로세스에 의존해 왔습니다. 문제는 ETL이 시간이 많이 소요되고 구축 및 유지 관리가 복잡하다는 점입니다. 파이프라인 실패 시 데이터 지연으로 통찰력 확보가 늦어지고, 데이터 볼륨이 빠르게 증가하면서 파이프라인을 구축하는 시점에는 데이터가 이미 오래된 상태가 되어 생생한 인사이트를 생성할 수 없게 됩니다.
차세대 Amazon SageMaker
차세대 SageMaker는 분석과 AI를 위한 통합된 경험을 제공합니다. Redshift, EMR, Glue, Athena 등 다양한 AWS 서비스의 데이터를 통합하고, Amazon Bedrock과 통합되어 GenAI 애플리케이션 작업에 활용됩니다. SageMaker Catalog는 데이터 디스커버리, 거버넌스, AI/ML 애플리케이션을 위한 데이터 협업을 단순화합니다.
Zero ETL 및 Data Lake 아키텍처
Zero ETL의 개념
Zero ETL은 데이터 소스에서 분석 시스템으로 데이터를 이동하는 노력을 최소화하거나 제거하는 접근 방식입니다. ETL 파이프라인 구축에 몇 주가 걸리던 작업을 노코드 또는 로우코드 방식으로 단순화하고, 준실시간 분석을 제공합니다.
예를 들어 추천 엔진에서 고객 행동 데이터, 구매 기록, 프로필 데이터가 S3, Redshift, RDS에 분산되어 있을 때, Zero ETL을 통해 데이터를 오픈 데이터 레이크로 가져옵니다. 이후 Lake Formation으로 세분화된 접근 제어를 제공하고, 이 데이터를 AI/ML 애플리케이션에 바로 사용할 수 있습니다.
데이터 레이크 아키텍처
SageMaker는 Apache Iceberg를 사용하는 오픈 데이터 레이크 아키텍처를 기반으로 합니다. S3 데이터 레이크 전반의 모든 데이터를 통합하고, 구조화된 테이블 데이터를 위한 S3 테이블 및 Redshift 데이터 웨어하우스와도 통합됩니다.
레이크하우스 카탈로그 및 Federated Query
레이크하우스 카탈로그
레이크하우스 아키텍처는 스토리지와 카탈로그 두 가지 핵심 구성 요소로 이루어져 있습니다. 스토리지는 Redshift 관리형 스토리지 또는 S3에 저장되고, 카탈로그는 Federated Catalog(기존 데이터 소스를 마운트)와 Managed Catalog(새로운 카탈로그 생성)로 구분됩니다.
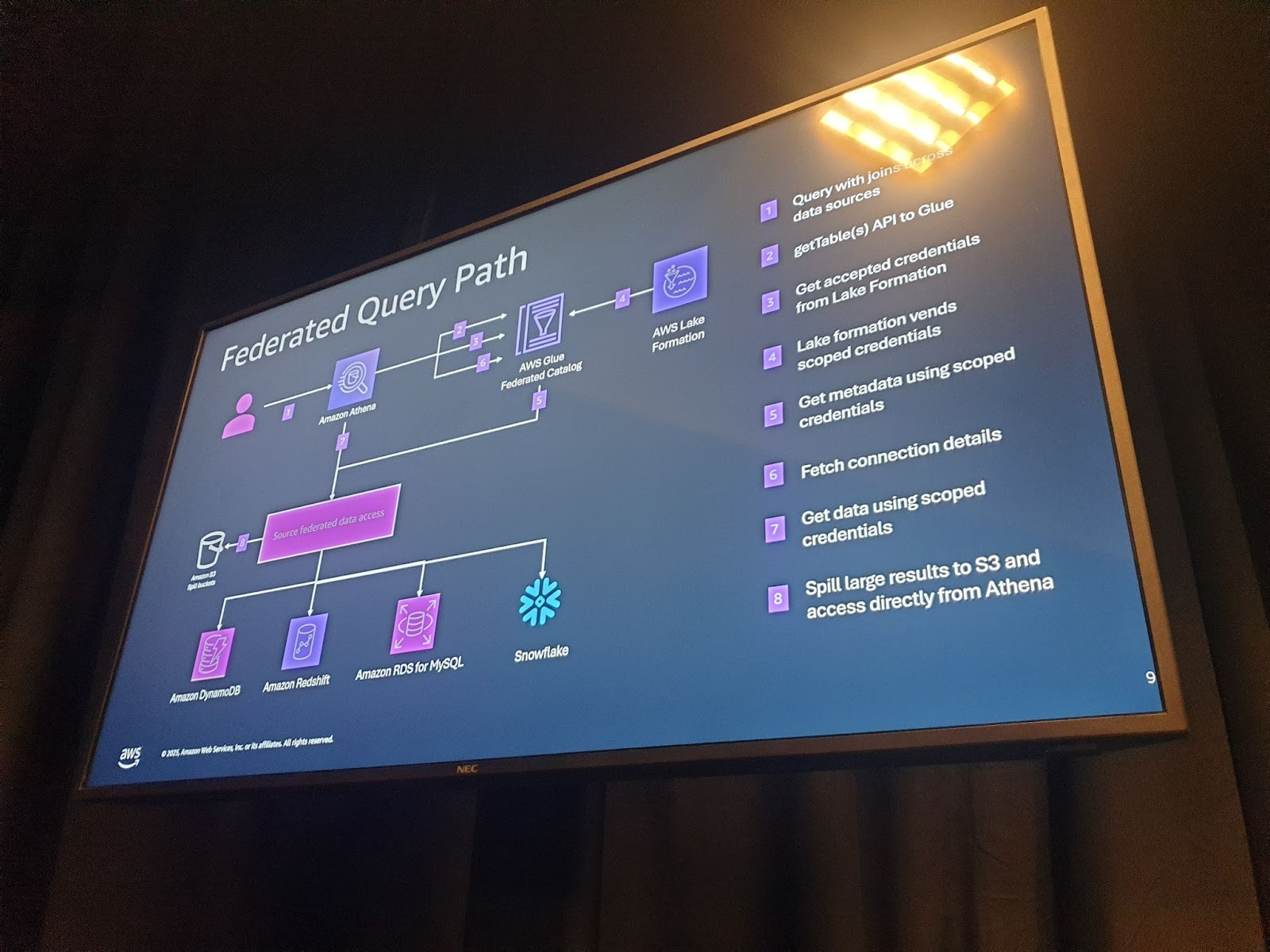
Federated Query의 작동 원리
페더레이션 쿼리는 SageMaker Unified Studio 내에서 S3 데이터와 Redshift 데이터를 조인하는 등 여러 소스에 걸쳐 쿼리를 실행할 수 있게 합니다. 쿼리가 제출되면 Athena는 페더레이션 카탈로그를 사용하여 메타데이터를 가져오고 Lake Formation에서 권한을 확인합니다. 대규모 데이터 세트의 경우 임시 결과는 S3 버킷에 기록되며, Athena는 이를 직접 연결하여 읽습니다.
실습 시나리오
워크숍에서는 소매 사용 사례를 바탕으로 S3 카탈로그와 Redshift 카탈로그를 생성하고, Aurora MySQL과의 연결을 생성했습니다. Zero ETL 통합을 통해 Aurora MySQL 데이터를 Redshift로 가져오고, Athena와 Redshift 두 시스템에 걸쳐 페더레이션 쿼리를 실행했으며, 변경 데이터 캡처(CDC) 시나리오도 다뤘습니다.
결론 및 소감
전통적인 ETL 방식이 데이터 볼륨 증가와 실시간 분석 요구를 따라가지 못하는 시대에, SageMaker Unified Studio는 Zero ETL 통합, Data Lake 아키텍처, Federated Query를 통해 데이터 접근 및 분석의 패러다임을 변화시키고 있습니다.
ETL 파이프라인 구축에 소요되던 시간을 크게 절약하고, 데이터의 신선도를 높이며, 여러 소스에 분산된 데이터를 단일 환경에서 쉽게 통합하고 분석할 수 있게 되었습니다. 특히 Lake Formation을 활용한 세분화된 접근 제어와 Iceberg 기반의 오픈 데이터 레이크 아키텍처는 AI/ML 시대에 필수적인 보안과 유연성을 동시에 제공합니다.
이러한 접근 방식은 데이터 과학자와 분석가들이 데이터 이동 및 관리에 시간을 낭비하지 않고, 인사이트 생성과 GenAI 애플리케이션 개발이라는 핵심 업무에 집중할 수 있도록 돕는 실질적이고 혁신적인 방법이 될 수 있습니다.