
[reinvent 2025] Apache Spark를 위한 엔터프라이즈 규모 ETL 최적화
Summary
AWS Glue, EMR, SageMaker에서 Apache Spark 최적화 기법을 마스터하여 ETL 워크플로우의 잠재력을 극대화하세요. Spark 구성 튜닝, 파티션 관리, 메모리 최적화 등 데이터 처리를 가속화하는 고급 전략을 다룹니다. 병렬 처리, 캐싱 전략, 효율적인 데이터 셔플링 기법을 배우고, 성능 메트릭 모니터링 및 병목 현상 식별 방법을 익혀 실무에 적용할 수 있습니다.
리인벤트 2025 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
엔터프라이즈 스케일 ETL 최적화를 위한 Apache Spark on AWS

세션 개요
보안 및 거버넌스
기존 문제점
기존 Spark 환경은 보안 정책이 흩어져 있고 거버넌스가 일관되지 않아 데이터 유출 위험이 있었습니다. 사용자들은 데이터 접근 요청을 반복해야 했고, 데이터 엔지니어들은 EMR, Glue, Athena 각각에 대해 따로 정책을 관리해야 했습니다.
Lake Formation 통합 진화
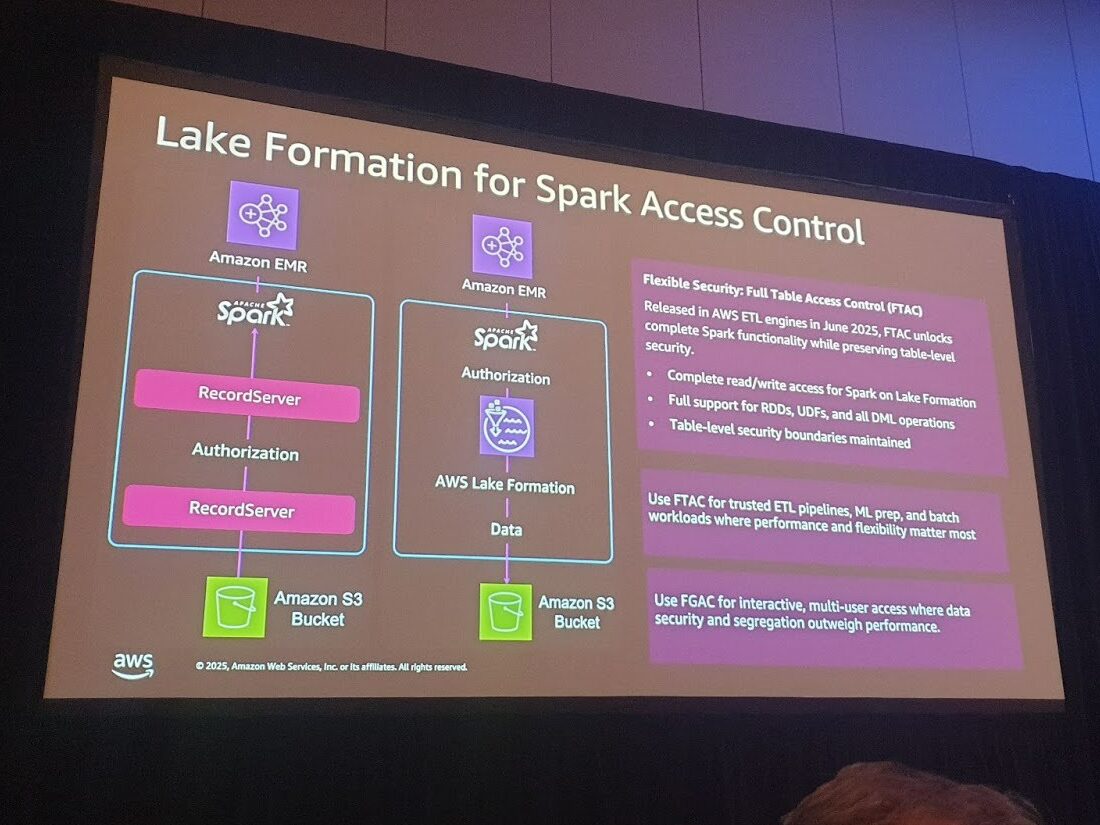
접근 제어 방식은 두 가지가 있습니다. FGAC는 행과 열 수준에서 세밀하게 제어할 수 있어서 다중 사용자 분석 환경에 적합하지만 최적화에 제약이 있습니다. FTAC는 완전한 가시성으로 성능이 우수하고 DML 작업이 가능해서 ETL 파이프라인에 더 적합합니다.
Data Catalog Views
이전에는 여러 분석 엔진에서 동일한 비즈니스 로직을 각각 작성해야 했습니다. Data Catalog Views는 하나의 중앙 집중식 정의로 여러 SQL 방언과 엔진에서 작동하며, Lake Formation이 권한을 일관되게 적용합니다. 데이터 복제 없이 대상별 공유가 가능하고, 통합된 CloudTrail 감사로 규제 보고도 용이해집니다.
통합된 Spark 런타임

사일로 문제 해결
EMR, Glue, Athena에 걸쳐 서로 다른 Spark 버전과 라이브러리가 존재하면서 환경마다 기능이 다르게 작동하거나 설정을 각각 관리해야 하는 문제가 있었습니다.
지난주 출시된 EMR 7.12와 Glue 5.1, Athena가 동일한 Spark 런타임을 공유하게 되었습니다. Spark 3.5.6, Iceberg 1.1.0, Hudi 1.0.2 버전으로 통일되었고, 이제 고객은 일관된 성능과 기능을 바탕으로 파이프라인을 어디서 실행할지만 결정하면 됩니다.
S3A 기본 커넥터 채택
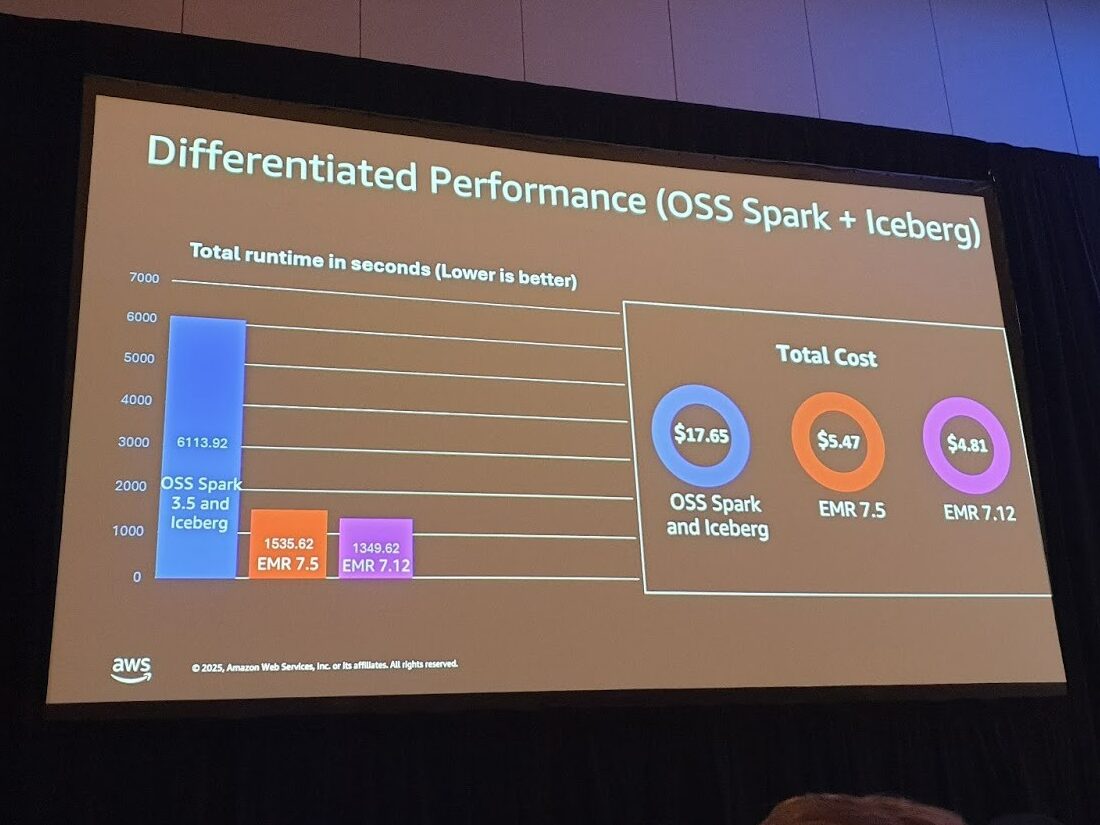
성능도 뛰어납니다. TPC-DS 벤치마크에서 가장 빠르고 비용 효율적이었고, 동적 쓰기는 EMRFS보다 최대 15.8배 빠르며, 정적 삽입은 약 10% 빠릅니다.
성능 최적화
Spark Materialized View
AWS Spark는 제출된 쿼리가 기존 MV의 이점을 얻을 수 있는지 파악하고 쿼리를 재작성하여 성능을 최대 8배 향상시킵니다. MV는 Parquet 형식으로 구축되어 다른 엔진에서도 Iceberg 테이블로 사용 가능합니다.
ETL 패턴 성능 개선
JSON 처리는 유사 기술 대비 20% 향상되었고, 암호화 오버헤드를 85% 감소시켜 전체 벤치마킹 속도를 20% 향상시켰습니다. 문자열 조작 함수는 정말 인상적인데, upper와 lower가 10배에서 12배, trim이 3배에서 4.5배, length는 최대 96배, reverse는 최대 56배 향상되었습니다.
결론 및 소감
개인적으로 가장 인상 깊었던 점은 Spark 런타임 자체의 최적화와 거버넌스 통합을 통해 사용자가 코드를 변경하지 않고도 성능과 보안 혜택을 즉시 누릴 수 있게 되었다는 점입니다. EMR 7.12로 업그레이드만 하면 Iceberg가 4.5배 빨라지고 문자열 함수가 수십 배 빠릅니다.
이는 AI와 데이터 과학의 고속 처리 요구사항이 증가하는 지금, AWS가 인프라뿐만 아니라 핵심 데이터 처리 엔진의 기본에 충실하며 시장 요구사항 이상을 맞추려는 노력을 보여줍니다. ETL 파이프라인의 안정성과 속도 개선이 필요한 모든 기업, 특히 대규모 데이터 처리와 엄격한 규정 준수가 필요한 금융, 통신, 공공 부문에 큰 도움이 될 것입니다.
