
[reinvent 2025] 멀티 웨어하우스를 사용한 Amazon Redshift 확장
Summary
엔터프라이즈 분석 플랫폼이 중앙 집중식 데이터 웨어하우스에서 연합형 다중 웨어하우스 아키텍처로 전환되고 있습니다. 비즈니스 요구사항에 맞춰 확장 가능한 아키텍처를 설계하는 방법과, 모놀리식 Redshift에서 현대적 구조로의 진화 및 비용 효율적 배포 사례를 다룹니다.
리인벤트 2025 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
Redshift의 다중 웨어하우스 아키텍처를 통한 확장
세션 개요
이번 re:Invent에서 참석한 “Scaling with Redshift’s Multilayer Health Architecture” 세션은 데이터가 폭발적으로 증가하면서 발생하는 워크로드 간 간섭과 확장성 문제를 어떻게 해결할 수 있는지 보여주는 세션이었습니다. 핵심은 모놀리식 아키텍처에서 다중 웨어하우스 아키텍처로의 전환이며, Hub-and-Spoke와 Data Mesh라는 두 가지 디자인 패턴과 Redshift의 신기술들이 주요 내용이었습니다.
기존 문제점: 모놀리식 아키텍처의 한계
전통적인 방식에서는 하나의 큰 컴퓨팅 클러스터에서 스트리밍 수집, 배치 작업, 데이터 분석, 대시보드 등 모든 작업을 처리했습니다. 문제는 워크로드 간 간섭이 발생한다는 점입니다. 배치 작업이 분석 쿼리 성능에 영향을 미치고, 리소스 경합으로 SLA를 맞추기 어려워집니다. 확장하려면 클러스터 전체를 키워야 해서 비용도 많이 들고, 필요한 워크로드만 따로 확장하기도 어렵습니다.
해결책: 다중 웨어하우스 디자인 패턴

1. Hub-and-Spoke 패턴
하나의 큰 클러스터를 여러 개의 작은 컴퓨팅 엔드 포인트로 분할합니다. 각 워크로드가 자기들만의 엔드 포인트를 가지고 완전히 격리되어 서로 영향을 주지 않습니다. 중요한 건 컴퓨팅은 분리했지만 데이터는 하나라는 점입니다. 모든 엔드 포인트가 Redshift 관리형 스토리지의 동일한 데이터를 바라봅니다. 데이터를 복사할 필요가 없으니 거버넌스 문제도 없고, 몇 분 안에 엔 드포인트를 추가할 수 있으며, 각 엔드 포인트의 비용을 특정 팀에 독립적으로 청구할 수 있습니다.

2. Data Mesh 패턴
재무팀, 마케팅팀, HR팀 등 여러 부서가 데이터를 공유할 때 발생하는 복잡한 조정 문제를 해결합니다. 각 부서가 자기들 데이터에 대한 소유권을 가지고, 자기들만의 컴퓨팅 엔드 포인트를 사용하며, 데이터베이스, 스키마, 테이블은 물론 행이나 열 수준까지 세밀하게 공유 대상을 결정할 수 있습니다.
Redshift의 핵심 기술

1. 스토리지: Iceberg 통합
Redshift 관리형 스토리지는 고성능 칼럼형 스토리지로, 대규모 고객의 절반 이상이 데이터 레이크도 함께 사용합니다. Redshift는 Iceberg를 지원해서 Redshift 데이터와 Iceberg 데이터를 하나의 쿼리에서 조인할 수 있습니다. 올해 Serverless Redshift의 Iceberg 쿼리 성능이 2배 이상 향상되었고, Iceberg 쓰기 기능도 출시되었습니다.
2. 컴퓨팅: Provisioned와 Serverless 하이브리드
안정적인 워크로드에는 Redshift Provisioned를, 산발적인 부하에는 자동 확장 기능이 있는 Redshift Serverless를 사용합니다. 컴퓨팅 클러스터가 여러 계정이나 리전에 분산될 수 있어 데이터 주권 규제도 만족시킬 수 있습니다.
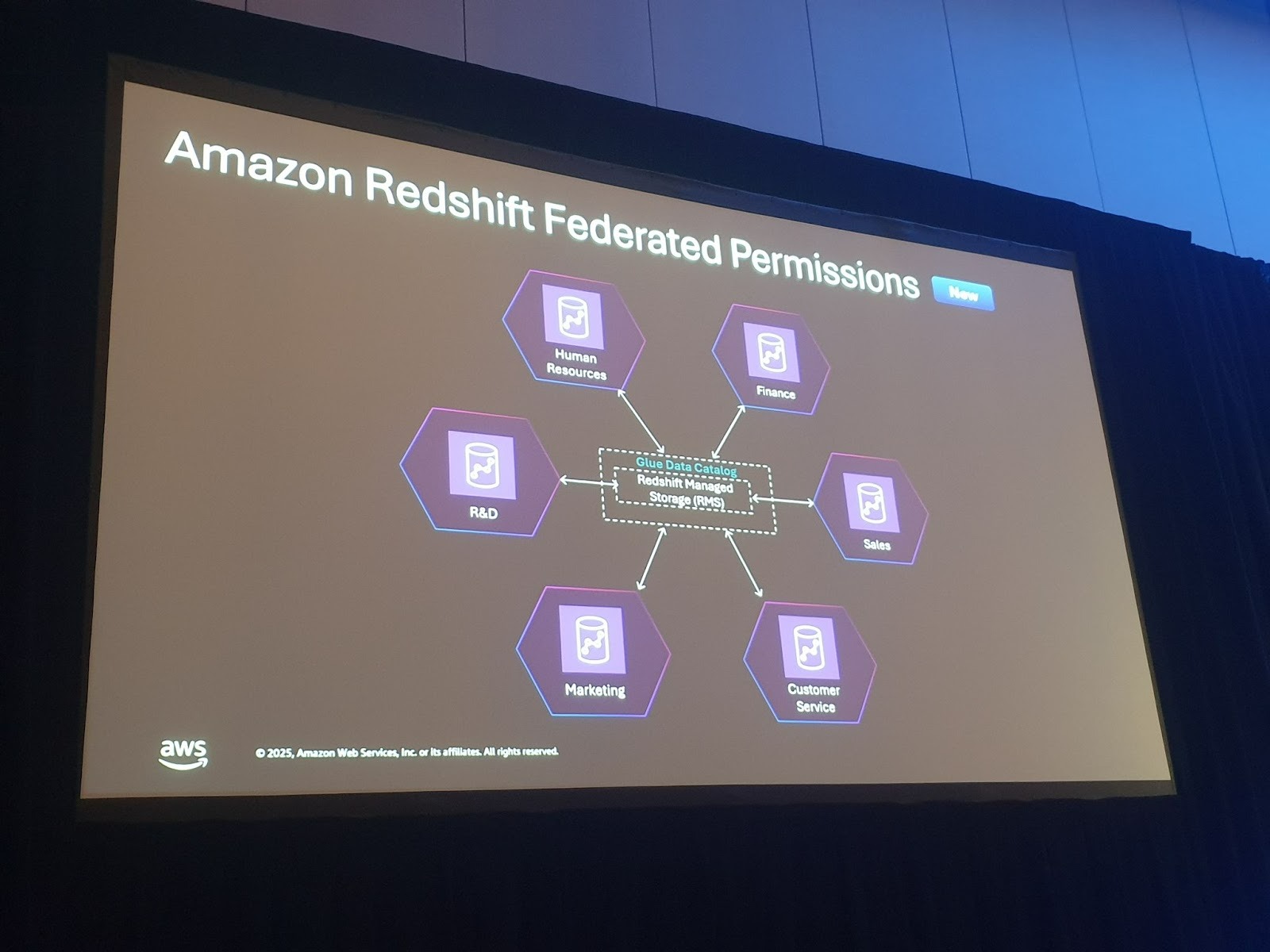
3. 거버넌스: Federated Permissions
개인적으로 가장 인상 깊었던 신규 기능입니다. 다중 웨어하우스 환경에서 각 클러스터마다 권한을 일일이 설정하는 게 아니라, 데이터 소유자가 하나의 중앙화된 장소에서 보안 정책을 만들고 Identity Center의 역할에 할당하면 자동으로 적용됩니다. 예를 들어 재무팀이 “로그인 리전에 따라 접근 제한” 정책을 만들면, 분석가가 쿼리할 때 정책이 허용하는 리전의 데이터만 보게 됩니다. 데이터를 단일 복사본으로 관리하듯 권한도 단일 복사본으로 관리하는 것입니다.
결론 및 소감
Redshift의 다중 웨어하우스 아키텍처는 워크로드 간 간섭과 확장성 제약 문제에 대한 명확한 해답이 될 수 있습니다. Hub-and-Spoke와 Data Mesh 패턴으로 컴퓨팅을 독립적으로 확장하고 격리하면서도, Redshift 관리형 스토리지로 데이터의 단일 소스를 유지하는 것이 핵심입니다.
Federated Permissions는 대규모 환경의 거버넌스 복잡성을 획기적으로 낮췄고, Iceberg 통합은 데이터 과학과 AI 애플리케이션의 유연성을 극대화하였습니다. 다중 웨어하우스 아키텍처가 단순한 최적화가 아니라 비즈니스 지속성을 위한 필수적인 발전 단계임을 확인했습니다.
이 아키텍처는 워크로드 격리와 독립적인 비용 청구가 필수적인 대규모 엔터프라이즈나, 차별화된 서비스 품질을 제공해야 하는 다중 테넌트 서비스 제공업체에게 실질적인 도움이 될 것입니다.
Federated Permissions는 대규모 환경의 거버넌스 복잡성을 획기적으로 낮췄고, Iceberg 통합은 데이터 과학과 AI 애플리케이션의 유연성을 극대화하였습니다. 다중 웨어하우스 아키텍처가 단순한 최적화가 아니라 비즈니스 지속성을 위한 필수적인 발전 단계임을 확인했습니다.
이 아키텍처는 워크로드 격리와 독립적인 비용 청구가 필수적인 대규모 엔터프라이즈나, 차별화된 서비스 품질을 제공해야 하는 다중 테넌트 서비스 제공업체에게 실질적인 도움이 될 것입니다.
글 │메가존클라우드, AIR Ops, 박창훈 DBA
게시물 주소가 복사되었습니다.
