
[reinvent 2025] Amazon SageMaker AI에서 파운데이션 모델 추론 확장하기
Summary
이 세션은 Amazon SageMaker AI를 사용하여 Qwen3, GPT-OSS, Llama4 등 인기 있는 오픈 소스 모델의 추론을 최적화하고 배포하는 방법을 소개합니다.
특히 높은 처리량, 낮은 지연 시간, 빠른 오토스케일링을 달성하기 위한 KV 캐싱, 지능형 라우팅 등 입증된 최적화 기술들을 중점적으로 다룹니다.
나아가, SageMaker AI와 LangChain, Amazon Bedrock AgentCore를 통합하여 Agentic 워크플로우를 구축하는 솔루션과 모범 사례를 공유하여 프로토타입을 신뢰할 수 있는 AI 경험으로 전환할 수 있도록 돕습니다.
리인벤트 2025 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며
이번 칼럼에서는 “Scaling foundation model inference on Amazon SageMaker AI (AIM424-SC)” 세션을 통해 LLM 및 생성형 AI 워크로드의 효율적이고 효과적인 배포 및 관리에 대한 신규 기술 및 업데이트된 정보를 공유하고자 합니다.
2025년 주요 트렌드는 단순히 응답을 생성하는 것을 넘어 행동을 취하고 목표를 달성하는 Agentic AI 워크플로우의 부상과 추론 시간 컴퓨팅(Test-time compute) 수요의 증가입니다. 프로토타입(POC) 단계에서 생산(Production) 단계로 나아갈 때 기업들은 성능, 확장성, 비용, 복잡성이라는 네 가지 주요 장애물에 직면하게 되는데, 이번 세션에서는 SageMaker AI 추론이 이러한 문제를 어떻게 해결하고 최적의 가격 성능, 유연성 및 사용 편의성을 제공하는지 중점적으로 살펴보겠습니다.

Agentic AI 시대의 도전과 SageMaker AI Inference의 핵심 기둥
2025년에는 Agentic 워크플로우가 기업들의 핵심 관심사가 되었습니다. Agentic AI는 사용자로부터 목표를 부여받으면, 이를 달성하기 위해 문제를 분해하고, 도구를 활용하며, 사용자 대신 행동을 취할 수 있습니다.

가트너는 2028년까지 기업 소프트웨어 애플리케이션의 33%가 Agentic AI를 포함하게 될 것이며, 이는 2024년 1% 미만에서 크게 증가한 수치라고 예측했습니다.
이러한 Agentic 시스템은 추론 컴퓨팅 수요를 급격히 증가시키고 있습니다.
최신 고성능 LLM들은 단순히 즉각적인 응답을 주는 대신, Chain-of-Thought (CoT) 추론 방식을 활용하여 답변의 정확도를 높입니다.
CoT 추론은 모델이 지식을 활용하는 것 외에도 논리적인 중간 단계를 거쳐 답변을 생성하게 하지만, 이 과정에서 더 많은 토큰을 생성하게 되어 결과적으로 컴퓨팅 리소스 수요를 높입니다.
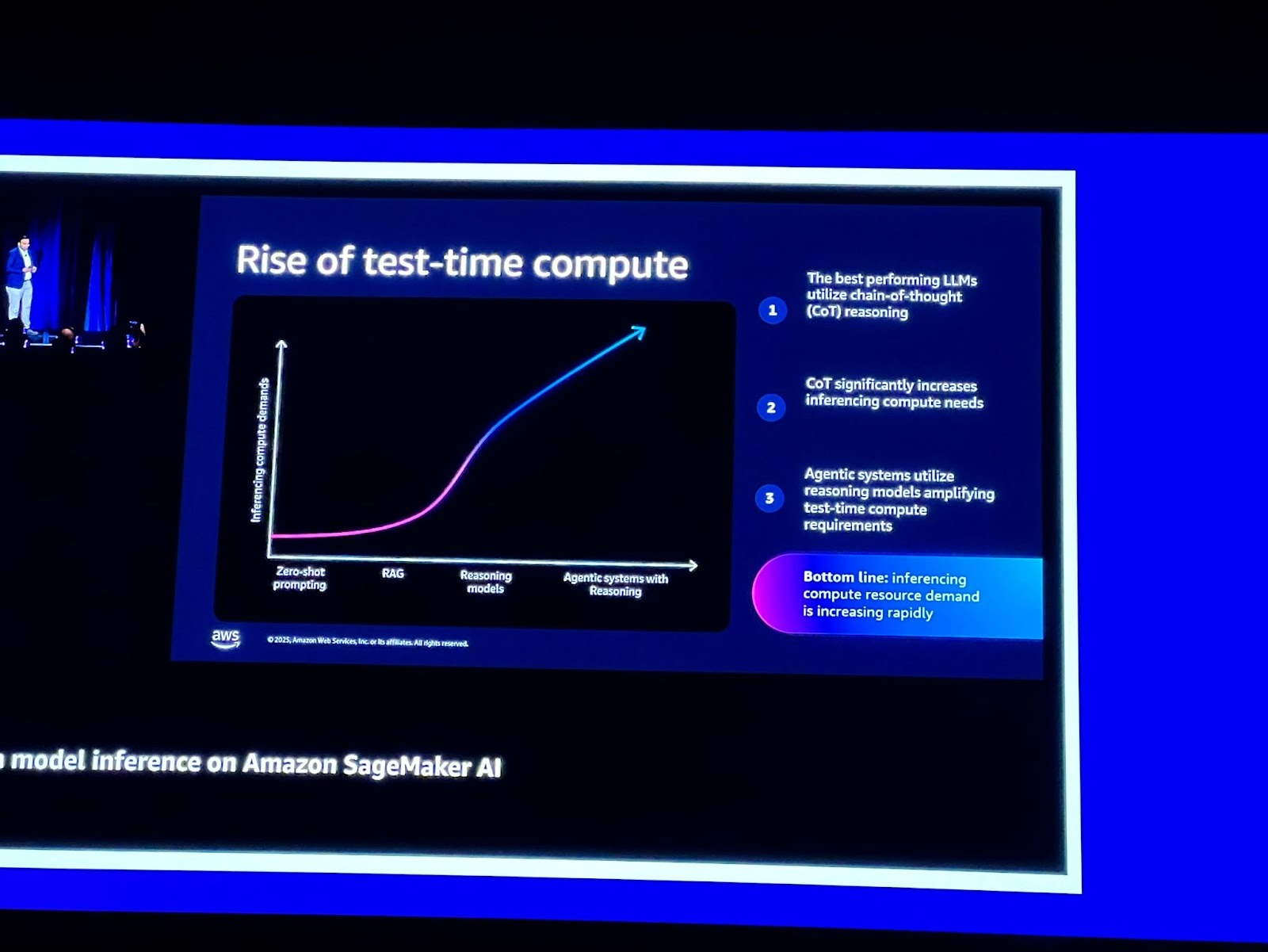
따라서 프로덕션 단계에서 AI 에이전트의 ROI(투자 수익률)를 확보하기 위해서는 성능(Performance), 확장성(Scalability), 비용(Costs), 복잡성(Complexity)이라는 실제적인 문제들을 해결해야 합니다.
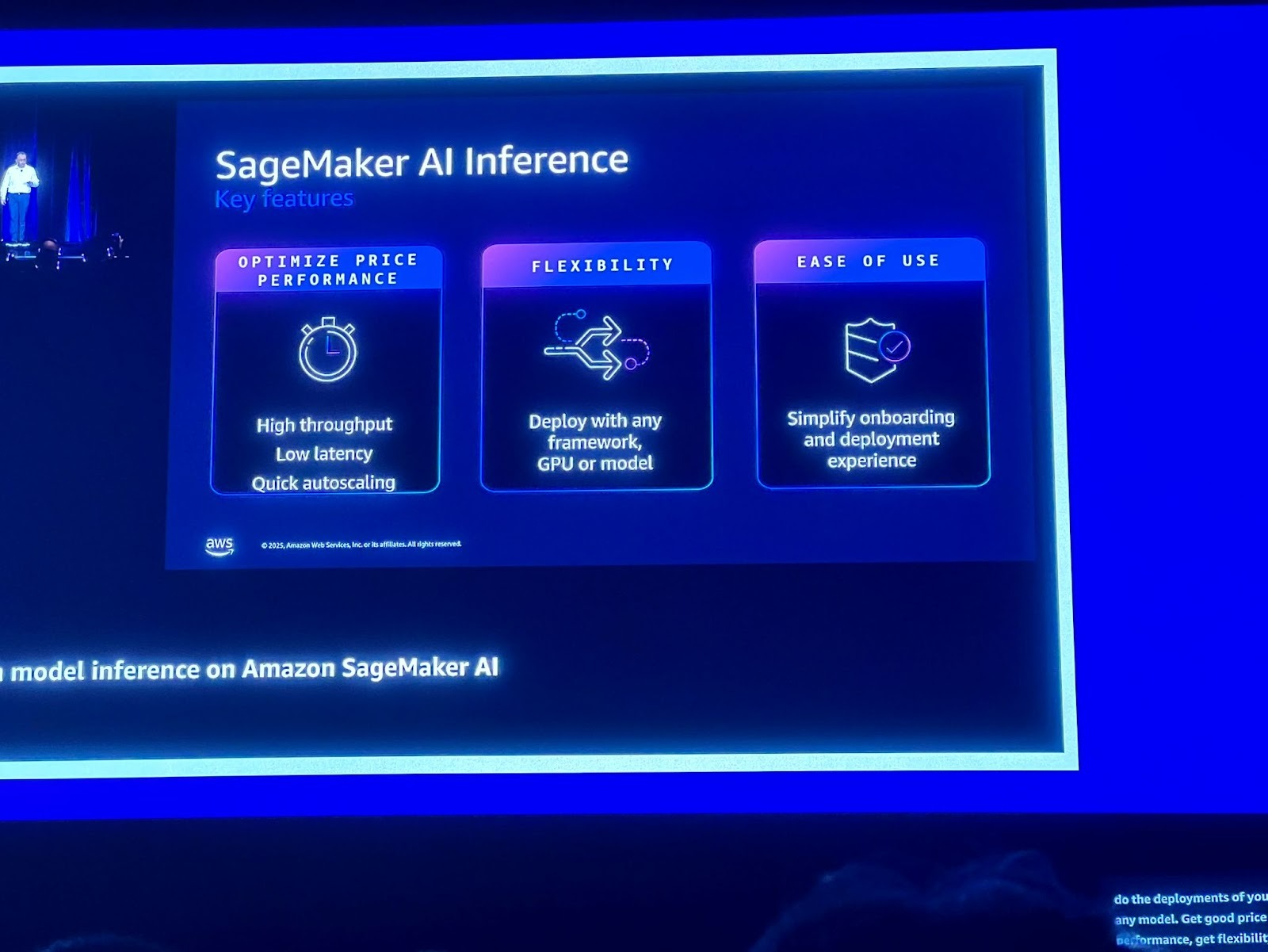
SageMaker AI Inference는 이 문제를 해결하기 위해 가격 성능 최적화(Optimize Price Performance), 유연성(Flexibility), 사용 편의성(Ease of Use)의 세 가지 핵심 기둥을 제공합니다.
가격 성능 최적화 및 레이턴시 개선 기능
SageMaker AI Inference는 높은 처리량(High throughput), 낮은 지연 시간(Low latency), 빠른 오토스케일링(Quick autoscaling)을 통해 가격 성능을 최적화하는 다양한 기능을 제공합니다.
1. EAGLE Heads를 활용한 Speculative Decoding (신규 기능): 고객들은 빠른 추론 속도를 원하지만, 일반적인 LLM은 한 번에 하나의 토큰만 생성하여 속도가 느립니다.
EAGLE heads는 이러한 추론 속도를 타협 없이 높이는 방법으로, Draft model이 다음 N개의 연속 토큰을 한 번에 생성하면, Foundation model이 이 토큰들을 병렬로 평가하여 수락/거부함으로써 처리 속도를 가속화합니다.

테스트 결과, EAGLE heads는 지연 시간을 줄이고 처리량(throughput)을 2.5배 증가시키며 정확도 손실은 0%를 유지했습니다.
이 기능은 BYO 데이터셋 또는 제공된 데이터셋을 사용하여 최적화 작업으로 실행되며, 검증 후 엔드포인트에 배포됩니다.
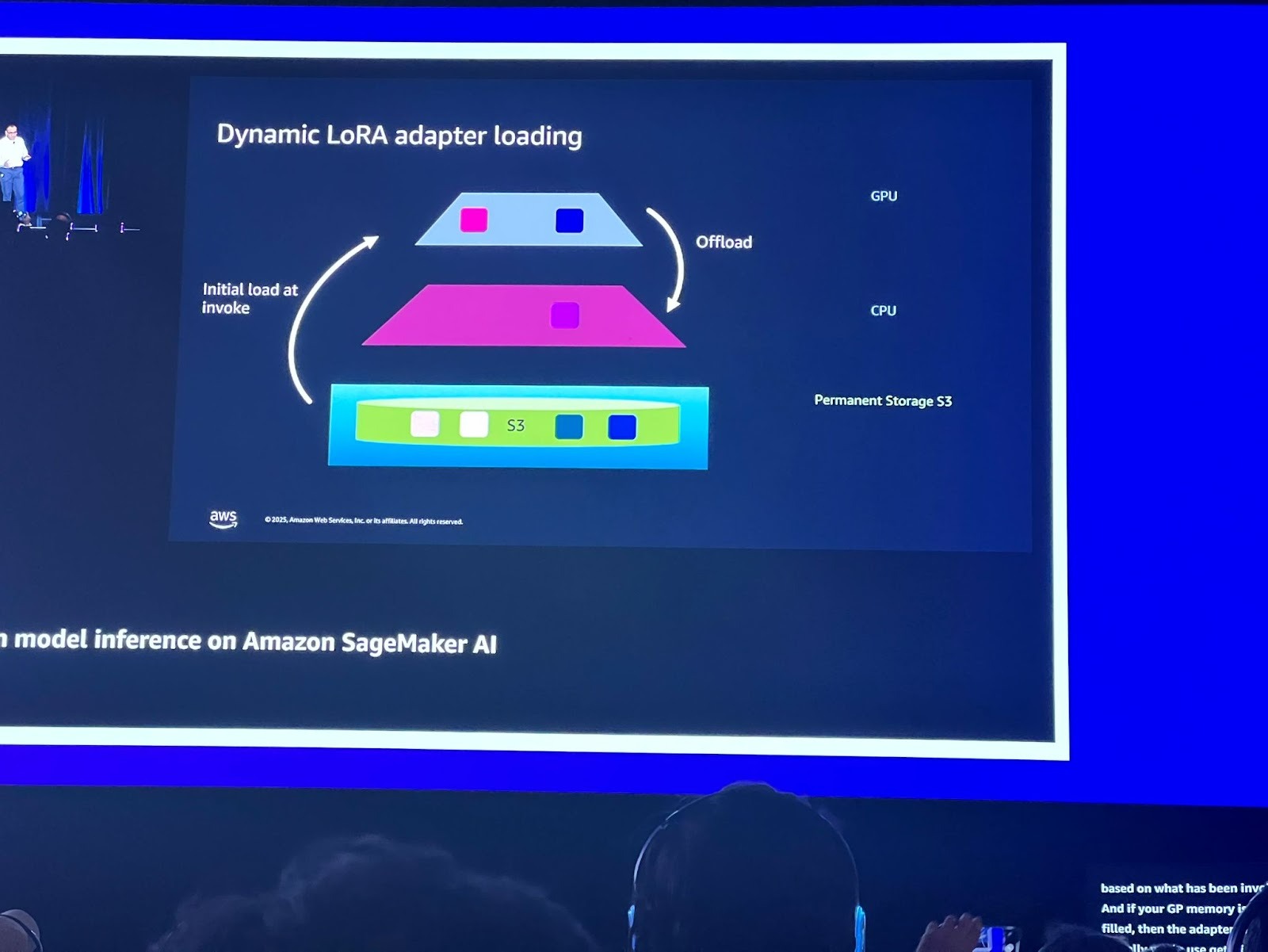
2. 동적 LoRA 어댑터 로딩 (Dynamic LoRA adapter loading): 사용자는 하나의 베이스 모델에 여러 LoRA 어댑터를 배포할 수 있는데, Dynamic LoRA 어댑터 로딩은 모든 어댑터가 S3와 같은 영구 스토리지에 저장되어 있다가, 호출(invoke) 시에만 GPU로 로드되고, GPU 메모리가 가득 차면 사용되지 않는 어댑터는 CPU로 오프로드(Offload)됩니다.
이는 GPU 메모리를 효율적으로 사용하여 다양한 LoRA 어댑터를 효과적으로 서빙할 수 있게 합니다.
3. 라우팅 개선을 통한 레이턴시 향상: 추론 지연 시간을 개선하기 위해 두 가지 라우팅 개선이 도입되었습니다.
◦ 부하 인식 라우팅 (Load aware routing): 응답을 받을 수 있는 모든 가용 액셀러레이터 중에서 트래픽이 적은 곳으로 프롬프트를 보내 지연 시간을 최소 20% 줄입니다. (Stateless)
◦ 세션 인식 라우팅 (Session aware routing): 멀티 턴 채팅(Multi-turn chat)처럼 과거 기록과의 컨텍스트(Stateful)가 필요할 때, 해당 세션의 요청을 동일한 모델 복제본으로 라우팅하여 지연 시간을 최소 20% 줄입니다.
4. 캐싱을 통한 오토스케일링 가속화 (신규 기능): Amazon SageMaker는 NVMe 볼륨에 모델 가중치(Model weights) 캐싱 기능을 통합하여 오토스케일링 속도를 최대 50% 빠르게 개선했습니다.

유연성, 사용 편의성, 그리고 Agentic 워크플로우 구축
SageMaker AI Inference는 사용자가 원하는 대로 모델과 환경을 커스터마이징하고 손쉽게 프로덕션 환경을 관리할 수 있도록 지원합니다.
1. 스택 전반의 유연성 및 오픈 소스 지원
SageMaker는 관리형 컨테이너(Managed Containers)를 제공할 뿐만 아니라, 고객이 자체적으로 컨테이너를 가져와 사용할 수 있는 BYOC(Bring Your Own Container)도 지원합니다.
또한 고객은 추론 전후 처리 스크립트(pre/post-processing scripts)를 사용자 정의할 수 있으며, 텍스트 생성, 시각 언어 모델, 오디오 전사 및 번역, 이미지 생성 등 다양한 멀티모달 사용 사례를 지원합니다.

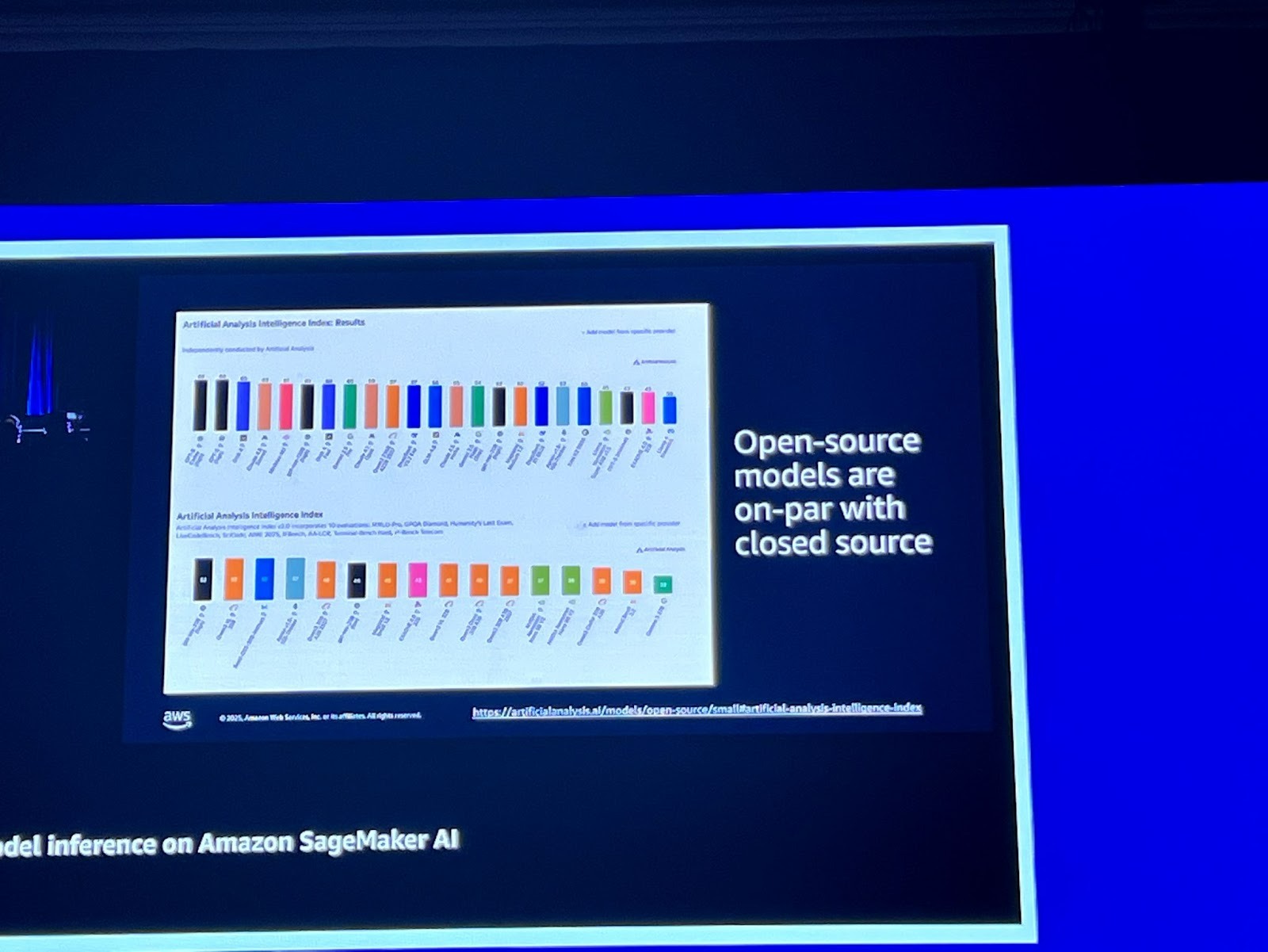
특히, 오픈 소스 모델은 클로즈드 소스 모델과 대등한 성능을 보여주고 있으며, SageMaker는 GPT-OSS와 같은 비용 효율적인 오픈 소스 모델을 쉽게 배포할 수 있도록 지원합니다.
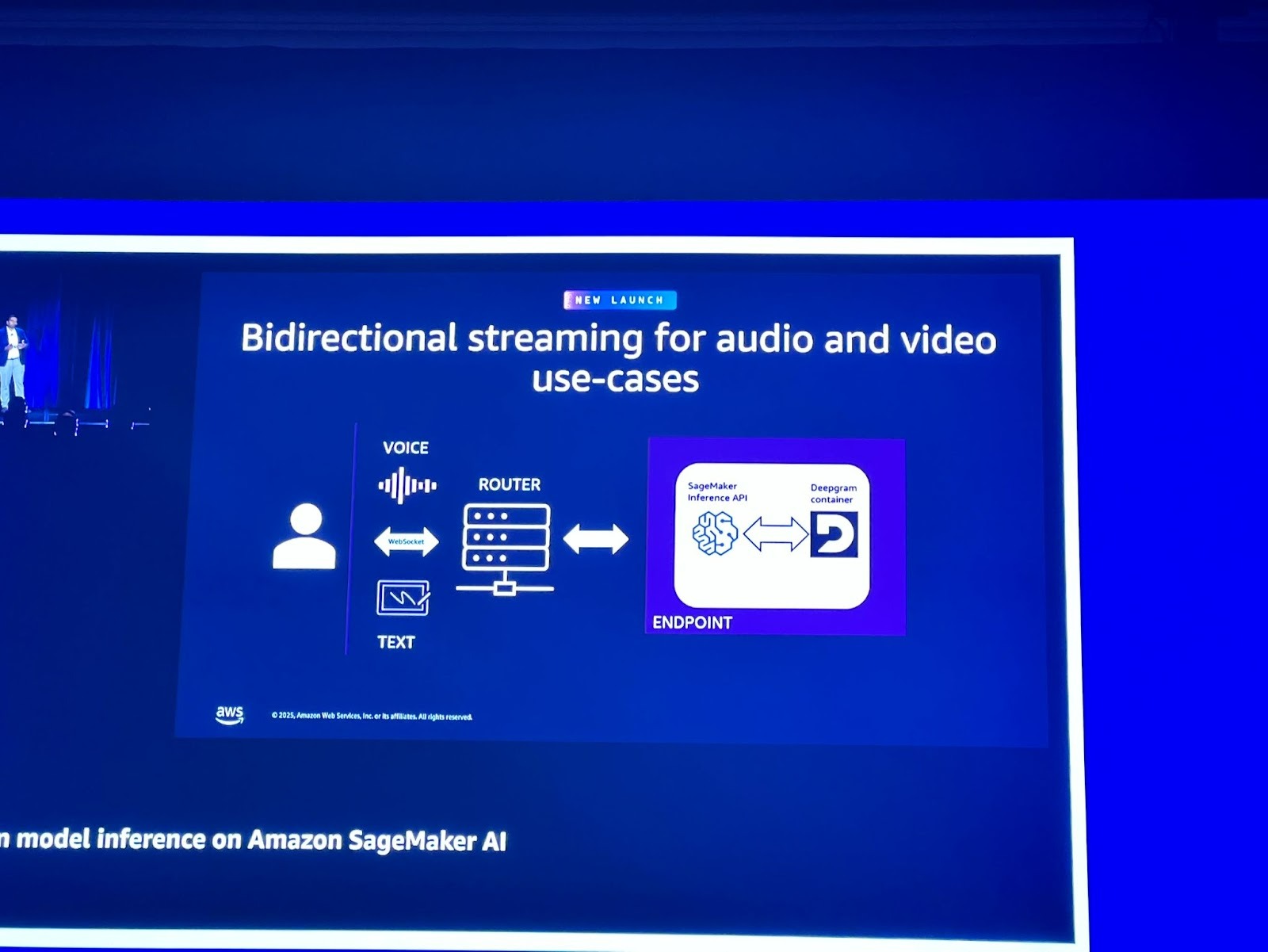
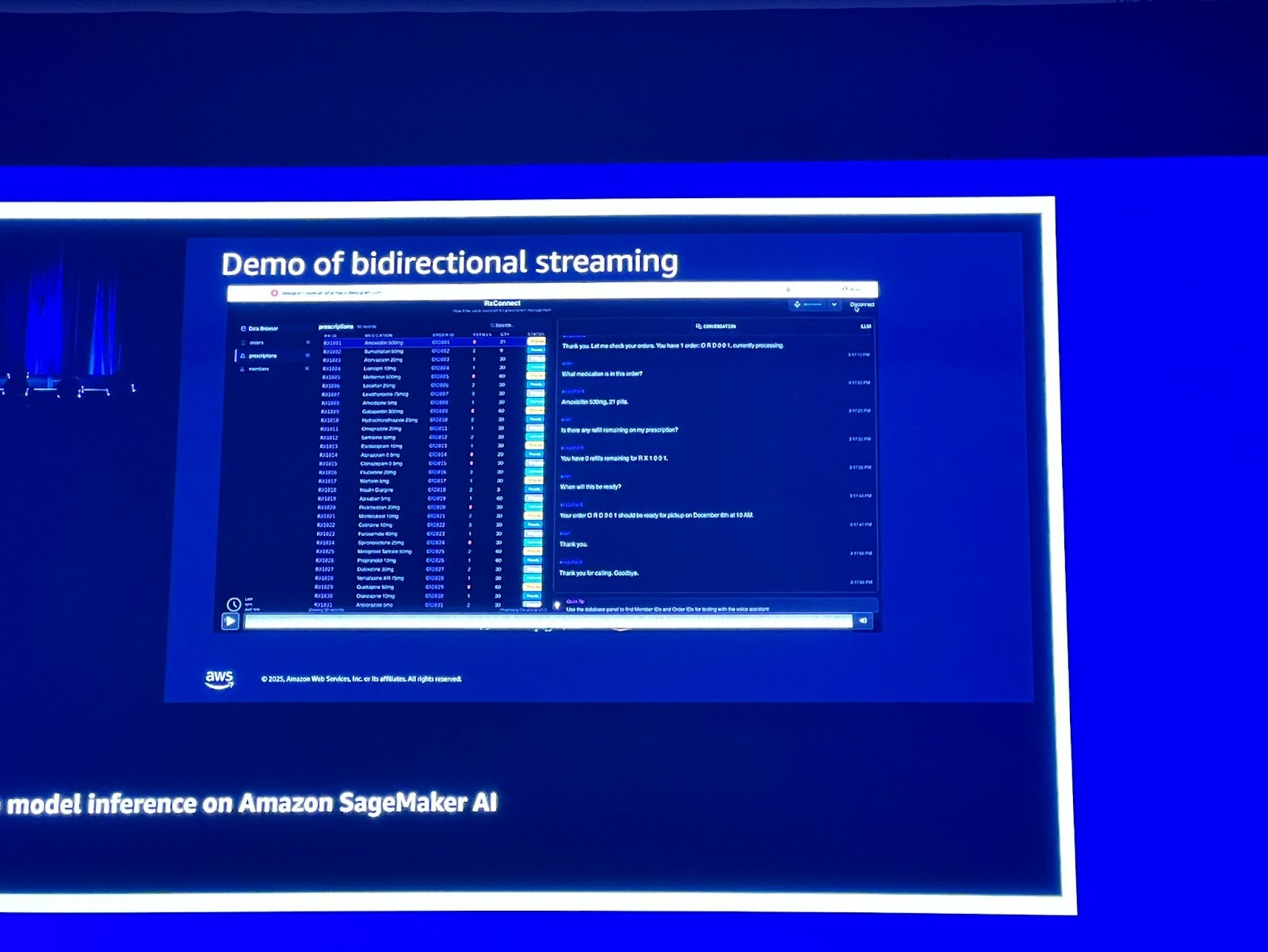
2. 양방향 스트리밍 (Bidirectional Streaming) 지원 (신규 기능)
오디오 및 비디오 사용 사례를 위한 양방향 스트리밍 기능이 새로 출시되었습니다.
이는 실시간 음성 전사나 고객 서비스 에이전트와 같이 클라이언트가 스트리밍 요청을 보내고 모델이 스트리밍 응답을 기대하는 상황에서 매우 중요합니다.
이 기능은 클라이언트와 SageMaker 라우터 간에 HTTP2 프로토콜을 사용하며, 라우터와 모델 간의 연결에는 WebSocket을 사용하여 동일한 연결을 통해 양방향으로 응답을 효율적으로 스트리밍합니다.
Deepgram과 같은 보이스 에이전트(Voice Agents) 모델과의 통합도 지원됩니다.
3. 유연한 용량 계획 (Flexible Capacity Plans) (신규 기능)
고성능 컴퓨팅 리소스(GPU)가 부족하고 확장하기 어렵다는 문제를 해결하기 위해, 이제 SageMaker Inference에서 Flexible Capacity Plans를 지원합니다.
고객은 AWS SageMaker 콘솔에서 직접 인스턴스 유형(p5e, p5en, p4d 등), 인스턴스 개수(1~64개), 기간(1~182일, 최대 6개월)을 선택하여 용량을 자체적으로 예약할 수 있습니다.
이는 벤치마킹, 테스트 또는 계획된 대규모 출시를 위해 용량을 확보하는 과정을 간소화합니다.

4. Agentic 워크플로우 구축
SageMaker에 모델을 배포한 후, 고객은 LangGraph, LlamaIndex와 같은 프레임워크의 SageMaker 커넥터를 사용하여 Agentic 워크플로우를 구축할 수 있습니다.
이 워크플로우는 Python 스크립트 형태로 작성된 다음, Agent Core 런타임에 배포되어 메모리 게이트웨이, 인증 등의 기능을 갖춘 확장 가능한 플랫폼을 통해 실행됩니다.
결론
Amazon SageMaker AI Inference는 LLM 추론 환경에서 발생하는 성능, 비용, 복잡성 문제를 해결하기 위해 광범위한 기능을 제공합니다. 특히, EAGLE Heads를 통한 처리량 극대화, Dynamic LoRA adapter loading을 통한 메모리 효율성 향상, 그리고 Flexible Capacity Plans를 통한 GPU 용량 확보 간소화는 Agentic AI 시대에 맞춰 생산 환경으로의 전환을 자신 있게 지원합니다. 이러한 최적화 기능을 통해 고객들은 GPU 활용도를 최대화하고(Multiple models to a single endpoint), 사용자에게 고성능의 Agentic AI 경험을 제공할 수 있는 견고한 기반을 마련할 수 있습니다.
