
[reinvent 2025] Amazon S3 Vectors를 통한 AI 스토리지 비용 구조의 혁신
Summary
Amazon S3 Vectors는 S3에서 벡터를 저장하고, 조회하고, 쿼리할 수 있도록 기본 지원을 제공합니다.
이 세션에서는 S3 Vectors가 고성능 벡터 데이터베이스를 어떻게 보완하며, 스토리지 및 쿼리 비용을 최대 90%까지 절감하는지 살펴봅니다. 또한 S3 Vectors를 Amazon Bedrock Knowledge Bases 및 OpenSearch Service와 연동하여 더 낮은 비용과 복잡성으로 RAG 및 시맨틱 검색을 구현하는 방법을 알아봅니다.
리인벤트 2025 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며
Amazon S3 Vectors (Preview)


Public Preview 기간 동안 공개된 성능 지표는 다음과 같습니다.
장기 보관하면서도 기존 벡터 데이터베이스 대비 최대 90%의 비용 절감이 가능했고, 수억~수십억 개의 벡터를 저장하면서도 안정적인 서브초 검색 속도를 유지했습니다. 또한 출시 직후 불과 4개월 만에 고객들은 25만 개 이상의 인덱스를 생성하고, 40억 개 이상의 벡터를 저장, 10억 건이 넘는 검색 요청을 처리하며 서비스의 확장성과 신뢰성을 증명했습니다.
아래는 고객들이 S3 Vectors를 실제 서비스에 적용하면서 요청한 4가지 주요 기능입니다.

1. 더 낮은 지연 시간
사용자 대상 검색, 추천, 카탈로그 같은 인터랙티브 서비스에는 1ms도 중요하기 때문에 더 빠른 응답속도를 요청했습니다.
2. 더 큰 인덱스 크기
벡터 기반 애플리케이션이 커질수록 인덱스 자체도 훨씬 더 큰 규모를 요구했습니다.
3. 벡터의 빠른 ingestion 속도
소량의 벡터라도 높은 동시성으로 S3 Vectors에 빠르게 업로드되기를 원했습니다.
4. 더 많은 리전 지원 및 데이터, 사용자와의 근접성
규제 요구 사항 충족, 지리적 지연시간 감소 등을 위해 더 가까운 리전에 S3 Vectors가 필요했습니다.
Amazon S3 Vectors (GA)

Preview 이후 4개월 동안 지속적으로 기능을 개선해 최근 GA를 발표했습니다. 주요 구성 요소는 다음과 같습니다.

1. Vector Buckets
벡터 워크로드 전용으로 설계된 새로운 형태의 S3 버킷입니다. 기존 오브젝트 버킷과 다르게 대규모 벡터 저장, 검색, 업로드 요구를 충족하도록 최적화되었습니다.
2. Vector Index
벡터 버킷 안의 데이터 구조이며, 벡터와 해당 메타데이터(ID, timestamp, 장르 등)를 함께 저장합니다. 유사도 검색을 위한 벡터 간 관계를 관리하며, 메타데이터 기반 필터링도 함께 지원합니다.
3. Vector API
업로드, 조회, 삭제, 인덱스 관리 등 벡터 전용 API 세트를 제공함으로써 벡터 기반 애플리케이션을 빠르게 구축할 수 있도록 완전 신규 설계된 API입니다.
S3 Vectors 내부 구조
S3 Vectors 가격

S3 Vectors의 비용 구조는 매우 단순하고 효율적으로 설계되어 있습니다. 먼저 Pay-per-PUT 모델을 기반으로 하기 때문에 벡터 데이터를 업로드할 때만 비용이 발생하며, 사용하지 않는 동안에는 별도의 요금이 청구되지 않습니다. 또한 저장 비용 측면에서는 S3의 저렴한 스토리지 단가를 그대로 활용할 수 있어 매우 높은 비용 효율성을 제공합니다. 마지막으로 쿼리 비용은 쿼리를 실제로 실행할 때만 발생하며 별도의 컴퓨팅 노드를 유지하거나 관리할 필요가 없습니다. 특히 인덱스 규모가 커질수록 더 저렴한 단가(Tier)가 적용되어 대규모 벡터 데이터에서도 비용 최적화를 가능하게 합니다.
S3 Vectors 주요 Integration
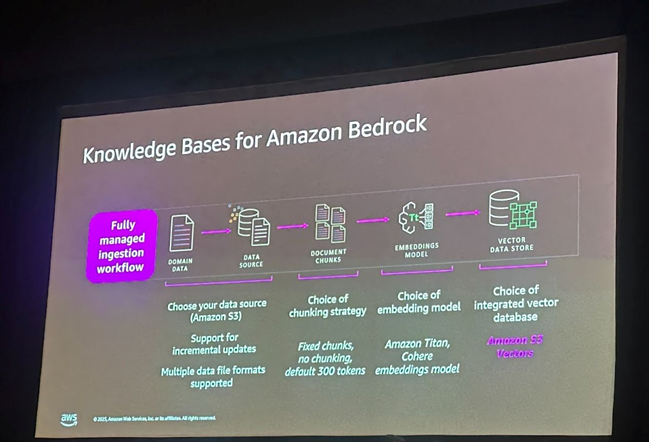
1. Bedrock Knowledge Bases 통합
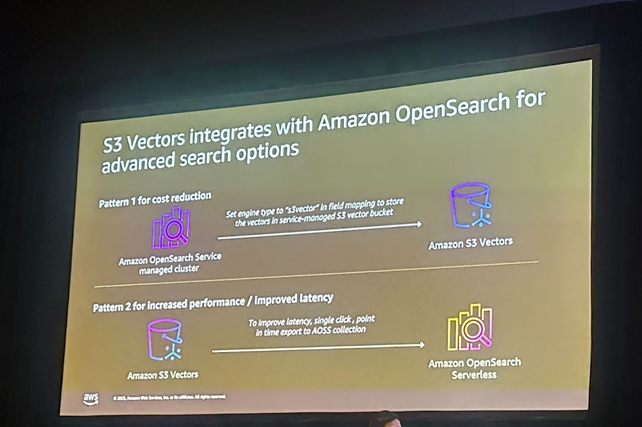
2. Amazon OpenSearch 통합
Amazon OpenSearch와의 통합을 통해 더 낮은 지연 시간과 강력한 하이브리드 검색 애플리케이션을 구축할 수 있습니다. 두 가지 패턴이 있는데, 첫 번째는 S3 Vectors를 백엔드 벡터 스토어로 사용해 비용을 절감하면서 OpenSearch의 하이브리드 검색 기능은 그대로 유지하는 방식이고 두 번째는 성능 중심 패턴으로 벡터를 S3 Vector 버킷에 저장한 뒤 OpenSearch Serverless로 내보내어 하이브리드 검색 기능을 활용하는 구조입니다
