Apache Iceberg v3를 활용하면 대규모 데이터 레이크에서 저장 비용을 줄이고, 데이터 처리 속도를 높이면서도 감사 추적을 쉽게 관리할 수 있습니다. 이번 세션에서는 3가지 핵심 기능 Variant Data Type, Deletion Vectors, Row Lineage 및 기타 기능과 함께 v4에서 기대되는 기능도 함께 살펴봅니다.
AWS re:Invent 2025 Tech Blog written by MegazoneCloud
Overview
Title: [NEW LAUNCH] What’s new in Apache Iceberg v3 and beyond
Date: 2025년 12월 1일 (월)
Venue: Mandalay Bay
Speaker:
Yuri Zarubin
Ron Ortloff
Industry: Software and Internet
들어가며
이번 세션은 Apache Iceberg v3의 기능 업데이트와 아키텍처 변화, 그리고 향후 v4 로드맵을 중심으로 진행되었습니다. 대규모 데이터 레이크 환경에서 Iceberg가 어떤 문제를 해결하고자 하는지, 그리고 사용자가 늘어나는 상황에서 어떤 기술적 개선이 이루어졌는지를 알 수 있습니다. v3의 핵심 변화인 Variant 타입, Deletion Vectors ,Row Lineage 소개와 함께 v3의 기타 업데이트 사항 및 Iceberg v4 방향성에 대해서 소개합니다. 해당 내용을 통해 사내 데이터 레이크/웨어하우스 아키텍처 검토 시 참고할 수 있는 정보를 제공하고자 합니다.
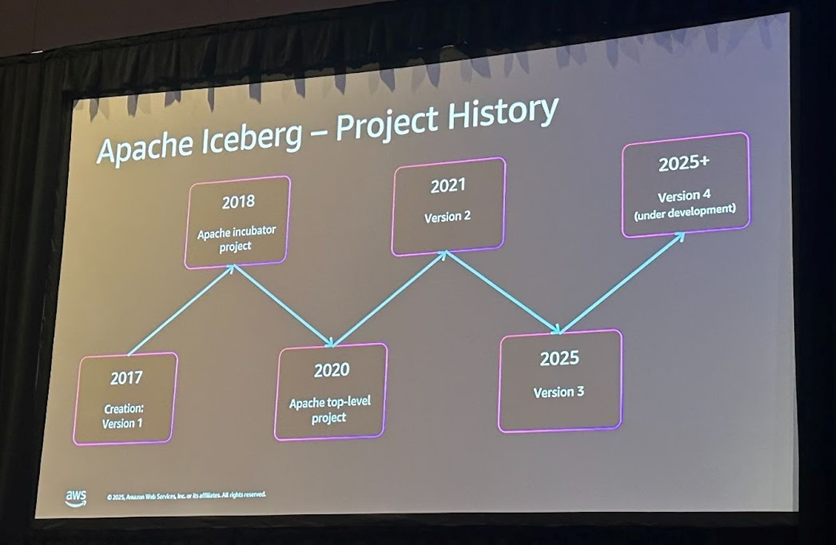
Apache Iceberg Project 발전 과정
Iceberg 프로젝트는 2017년 Netflix에서 Dan Weeks와 Ryan Blue가 기존 빅데이터 솔루션의 문제점을 해결하기 위해 시작했습니다. 2018년에는 Apache Software Foundation의 인큐베이터 프로젝트로 등록되었고, 2020년에는 정식 Top-Level 프로젝트가 되어 Apache의 공식 거버넌스를 따르게 되었습니다. 2021년에는 V2 스펙이 발표되며 Merge-on-Read 기능과 롤업 삭제 기능이 도입되었고, 2025년 5월에는 V3 스펙이 승인되었습니다. Iceberg는 스펙을 통해 상호운용성을 보장하며, 여러 벤더가 구현하더라도 동일한 데이터 위에서 다양한 컴퓨트 엔진을 사용할 수 있도록 설계되었습니다. 스펙에 정의된 기능들은 릴리즈를 통해 구현되며, 이 과정 역시 Apache의 공식 소프트웨어 릴리즈 절차를 따릅니다. Iceberg V3 스펙이 발표되었지만, 실제 기능 구현은 1.7부터 1.10 릴리즈 사이에 커뮤니티에서 순차적으로 이루어지고 있으며, 앞으로도 지속적으로 구현이 진행될 예정입니다.
주요 변화 1 : Variant Data Type
Iceberg v3에서 가장 큰 변화 중 하나는 새롭게 도입된 Variant 데이터 타입입니다. 기존에는 반정형(Semi-structured) 데이터를 처리하기 위해 고정 스키마로 변환하거나 별도 컬럼으로 추출하거나 혹은 문자열로 저장하여 파싱하는 방식을 사용했습니다. Variant 타입은 이러한 한계를 해결하기 위해 설계된 타입으로 반정형 데이터를 유연하게 처리하며 metadata, encoding, Shredding의 세 가지 핵심 요소를 활용하여 반정형 데이터를 유연하게 처리합니다. 특히 Shredding을 통해 Variant 데이터를 보이지 않는 서브 컬럼으로 구체화하여 성능을 최적화합니다. 이를 통해 IoT 워크로드, 데이터 파이프라인, 실시간 분석과 같은 사례에서 유용하게 활용할 수 있습니다.
주요 변화 2 : Deletion Vectors
Deletion Vectors는 기존 Iceberg V2의 positional delete 방식을 대체하는 효율적인 삭제 방식입니다. 기존 positional delete 방식은 삭제할 레코드의 위치 정보를 별도로 기록하는 방식으로, 데이터 파일을 다시 쓰거나 스캔할 때 추가 작업이 필요해 쓰기 증폭(write amplification)과 관리 부담이 발생했습니다.
반면 Deletion Vectors는 별도의 Deletion Vector 파일에 저장된 비트맵을 활용해 삭제 대상 정보를 효율적으로 관리합니다. 각 데이터 파일에 대해 삭제 대상 레코드를 비트맵으로 표시하고, 쿼리 시 해당 비트맵을 참조하여 삭제된 레코드를 무시함으로써 저장 효율을 높이고 쓰기 증폭 문제를 크게 줄입니다. 이러한 방식 덕분에 GDPR 준수, 데이터 클렌징, 증분 데이터 파이프라인 등 다양한 시나리오에서 유용하게 활용될 수 있습니다.
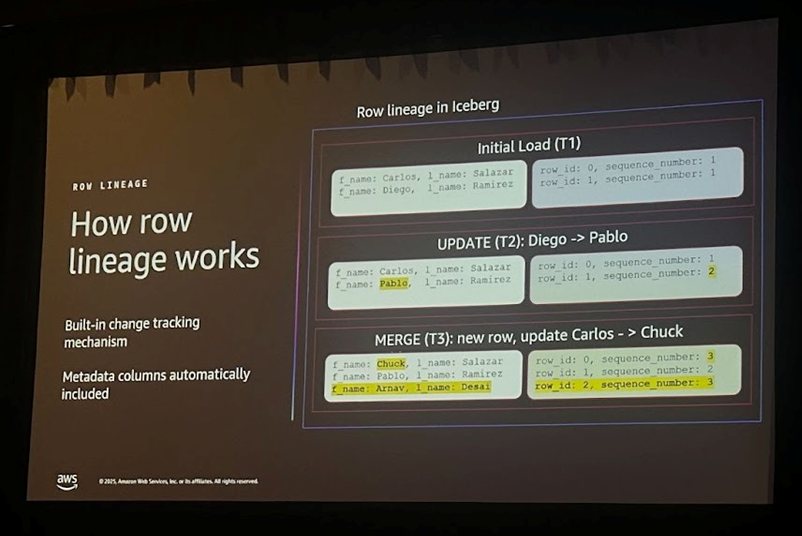
주요 변화 3 : Row Lineage
Row Lineage는 Iceberg v3에서 도입된 레코드 단위로 변경사항을 추적할 수 있는 기능으로, 각 행에 row_id와 sequence_number를 자동으로 부여해 변경 이력을 관리할 수 있도록 지원합니다. 이 정보는 숨겨진 컬럼 형태로 테이블에 저장됩니다. 변경되는 메타데이터가 데이터 레코드와 함께 저장되기 때문에 스냅샷과 데이터 레코드 상태 정보의 불일치 문제를 줄이고, 시간여행(Time Travel) 시점에도 해당 시점의 변경 이력을 그대로 확인할 수 있습니다.
v2의 Changelog 방식과 비교했을 때, Row Lineage는 스냅샷 간 diff 연산이 필요 없어 추가적인 연산 비용이 발생하지 않으며, 스키마 변경 시에도 별도의 뷰 관리가 필요 없어 운영 복잡도가 크게 감소합니다. 또한 변경 이력이 각 레코드에 직접 저장되므로, 시간여행(Time Travel)을 통한 상관관계 분석도 간단한 쿼리만으로 손쉽게 수행할 수 있습니다.
Iceberg v3의 추가 기능
Iceberg v3는 주요 기능 외에도 테이블 운영 효율성을 높이기 위한 다양한 개선 사항을 포함하고 있습니다. 기본값은 메타데이터에 기록되어 여러 개발자가 기본값을 다르게 설정하는 문제를 방지하고, 테이블 암호화 키와 키 회전을 통해 보안 관리가 강화됩니다. 또한 파티셔닝이나 정렬 시 다중컬럼을 지정할 수 있어 파티셔닝과 정렬 성능을 최적화할 수 있습니다. 나노초 단위 타임스탬프, 지리 정보 처리용 , Unknown 데이터 타입이 추가되었습니다. V3에서는 데이터 관리와 보안, 성능, 정밀도, 공간 데이터 활용 등 다양한 측면에서 기능이 강화되어 기존 Iceberg의 장점과 결합한 보다 안정적이고 유연한 데이터 플랫폼을 제공합니다.
향후 Iceberg v4 로드맵
Iceberg v4에서 논의되고 있는 주요 개선 방향은 현재 제안 단계이며, 전반적으로 쿼리 성능과 메타데이터 처리 효율 향상에 중점을 두고 있습니다. 개선된 컬럼 통계 구조를 통해 특정 컬럼에 대한 데이터 스캔이 보다 효율적으로 이루어질 것으로 기대됩니다. Adaptive metadata 구조는 소규모 단위 쓰기 작업 시 계층 구조를 단순화하여 처리 속도를 향상시키는 것을 목표로 합니다. 또한 Relative Path 기능은 테이블 복제나 백업 시 발생하는 절대 경로 문제를 해결하여 데이터 이동과 복제 작업의 유연성을 높입니다. 이 밖에도 소규모 단위 쓰기 및 쿼리 성능 최적화와 관련된 추가 개선안이 커뮤니티에서 활발히 논의되고 있습니다.
결론
이번 세션에서는 Iceberg V3의 핵심 기능인 Variant 타입, Deletion Vectors, Row Lineage와 다양한 추가 기능이 소개되었습니다. 대규모 데이터 레이크 환경에서 데이터 처리, 관리, 분석 효율을 동시에 높이는 기술적 개선 사항을 확인할 수 있었습니다.
Iceberg는 안정성과 유연성을 모두 갖춘 데이터 플랫폼으로 진화하고 있으며, 이번 V3 업데이트는 향후 V4를 통해 쿼리 성능과 메타데이터 처리 효율을 더 높여, 대규모 환경에서 효율적이고 신뢰성 있는 데이터 운영을 지원하려는 방향성을 보여주는 발표였다고 생각합니다
글 │메가존클라우드, AIR Unit, AIR Innovation Team, 송현진 Manager