
[reinvent 2025] AWS Glue와 MWAA를 활용한 데이터 워크플로우 통합 및 오케스트레이션
Summary
AWS Glue와 Amazon MWAA를 활용하여 데이터 레이크와 데이터 웨어하우스 간 ETL 파이프라인을 구축하고, Apache Airflow 기반 자동 DAG로 데이터 수집, 변환, 활용까지 전반적인 워크플로우를 효율적으로 관리하고 확장하는 방법을 실습 중심으로 소개합니다.
리인벤트 2025 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며

대규모 데이터 처리의 효율성을 위해 각 서비스의 역할을 명확히 하는 것이 중요합니다. Airflow는 전체 파이프라인의 흐름과 의존성을 제어하는 오케스트레이션 도구로 활용합니다. 부하가 큰 데이터 변환 작업은 AWS Glue를 활용하도록 구성하는 것을 권장합니다.
AWS Glue

AWS Glue는 서버리스 데이터 통합 서비스로, SQL 개발자, 비즈니스 분석가, 머신러닝 엔지니어 등 다양한 사용자를 지원합니다. Spark 기반 ETL 작업과 데이터 파이프라인을 자동으로 실행하며, 데이터 준비를 쉽고 빠르고 비용 효율적으로 수행할 수 있습니다.
개발 속도를 가속화하고 자동 확장으로 대규모 데이터 처리를 지원하는 서버리스 구조 덕분에 인프라 관리 부담을 최소화합니다. 또한, 현재 ETL 작업 생성과 Spark 작업을 최적화하고 문제 해결 속도를 높이는 생성형 AI 기반 기능도 제공합니다.
Amazon MWAA
Amazon MWAA(Amazon Managed Workflows for Apache Airflow)는 Apache Airflow를 완전관리형으로 제공하여 사용자가 인프라를 직접 관리하지 않고도 워크플로우를 안정적으로 운영할 수 있게 합니다. AWS가 환경 구성을 모두 관리해주기 때문에 사용자는 파이프라인과 태스크 간 의존성 정의에만 집중할 수 있습니다. 2025년 11월부터는 MWAA에 Serverless 옵션이 도입되어, Airflow 워크플로우를 작업 단위로 서버리스 방식으로 실행할 수 있으며, 인프라 프로비저닝이나 오토스케일링 관리 부담 없이 비용 효율적으로 운영할 수 있습니다.
2. MWAA 구성 요소

MWAA의 주요 구성 요소는 메타데이터 데이터베이스, 스케줄러, 워커로 나눌 수 있습니다. 메타데이터 데이터베이스는 워크플로우와 태스크 상태, DAG 정보를 저장하며, 실행 기록과 관련된 모든 데이터를 관리합니다. 스케줄러는 어떤 태스크를 언제 실행하고 실행 순서는 어떻게 되는지 결정하며 DAG의 의존성과 실행 계획을 관리합니다. 워커는 실제로 태스크가 실행되는 환경으로 작업 결과와 상태를 스케줄러에 전달합니다.
End-to-End 데이터 파이프라인 및 Lakehouse 아키텍처
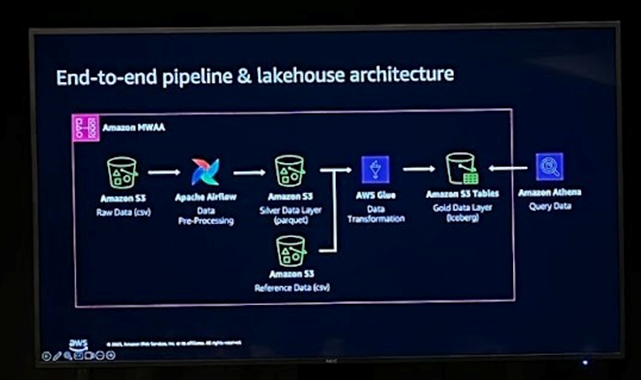
AWS Glue와 MWAA를 결합하면 데이터 수집부터 분석 가능한 Lakehouse 구축까지 이어지는 End-to-end 파이프라인을 구성할 수 있습니다. 이번 세션에서는 Raw Data(CSV) → Silver(Parquet) → Gold(Iceberg)의 흐름을 예시로 소개합니다.
먼저, Raw Data가 CSV 포맷으로 Amazon S3의 Raw Data Layer에 적재됩니다. 이 단계는 파이프라인의 시작점으로, 이후 처리될 소스 데이터를 저장하는 역할을 합니다. 이후 MWAA가 Raw Data를 읽어 전처리를 수행한 뒤, Parquet 포맷으로 변환하여 Silver Data Layer에 저장합니다. 단순 파일 변환이나 경량 처리 작업은 Airflow 내에서 수행할 수 있지만, 대규모 연산이나 복잡한 데이터 변환은 AWS Glue로 수행하는 것이 성능과 확장성 측면에서 효율적입니다.
변환된 데이터는 Iceberg 기반의 Gold Data Layer로 적재되며, 이를 통해 Upsert, Delete, Modify 등의 데이터 조작이 가능합니다. 마지막으로 Gold Layer에 적재된 데이터는 Amazon Athena 쿼리 엔진을 통해 조회 및 분석이 가능하며, 머신러닝 학습이나 BI 분석에도 활용할 수 있습니다.
Hands-On 핵심 내용
이번 세션의 핸즈온 실습에서는 앞서 제시한 아키텍처를 기반으로 실제 데이터 파이프라인을 구축하고, 운영 시나리오별 동작 방식과 시스템의 확장성을 검증했습니다.
1. Glue & MWAA 연동 비동기(Async) 파이프라인 구현
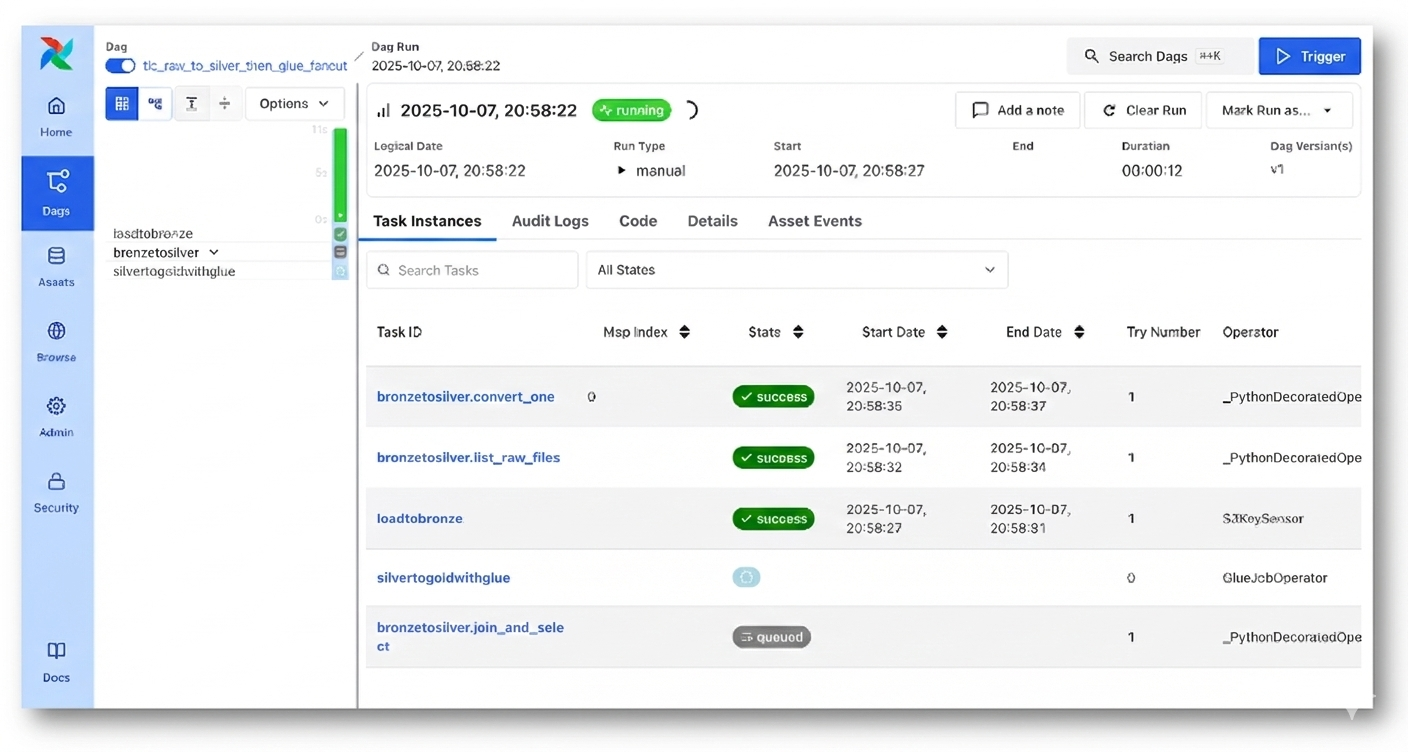
S3에 파일이 업로드되면 MWAA가 DAG을 자동으로 트리거하고 Glue 작업을 비동기적으로 실행합니다. MWAA는 각 작업의 완료를 기다리지 않기 때문에 DAG에서는 다양한 상태로 동시에 나타납니다. 이는 오케스트레이터가 대기 없이 리소스를 효율적으로 활용하며 파이프라인을 전개하는 비동기 처리 방식의 특징입니다.
2. Glue & MWAA 연동 동기(Sync) 파이프라인 구현
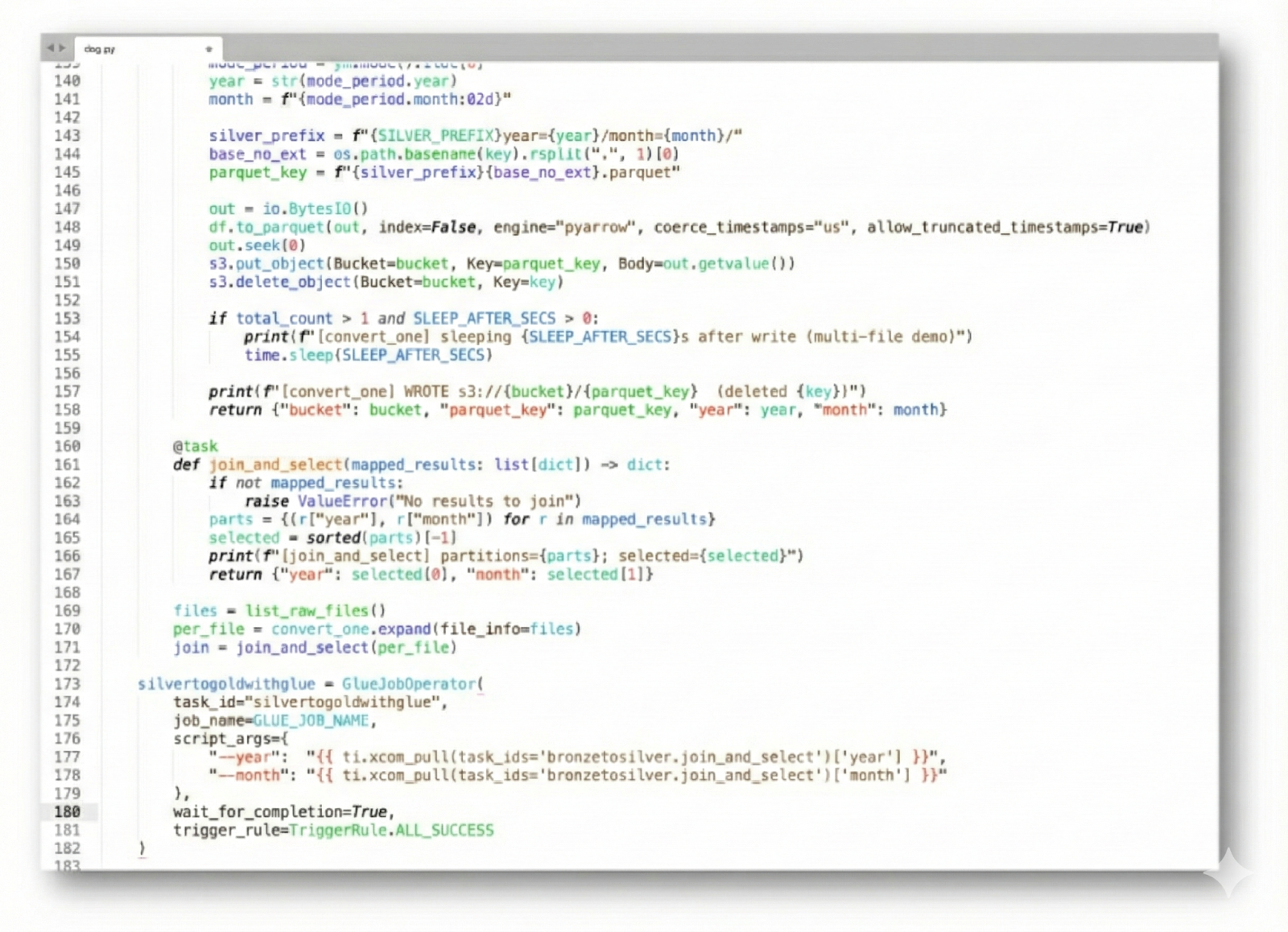
DAG 코드에서 wait_for_completion 옵션을 True로 설정하면, MWAA는 Glue 작업이 완료될 때까지 대기하며, 앞선 작업이 성공해야 다음 단계로 진행합니다. 비동기 방식과 달리, Glue 관련 태스크 상태는 작업이 완료될 때까지 running 상태로 유지되며, 완료되면 success로 변경됩니다. 이를 통해 동기 방식에서는 단계 간 의존성이 어떻게 동기화되는지 확인할 수 있었습니다.
3. MWAA Auto Scaling 관찰
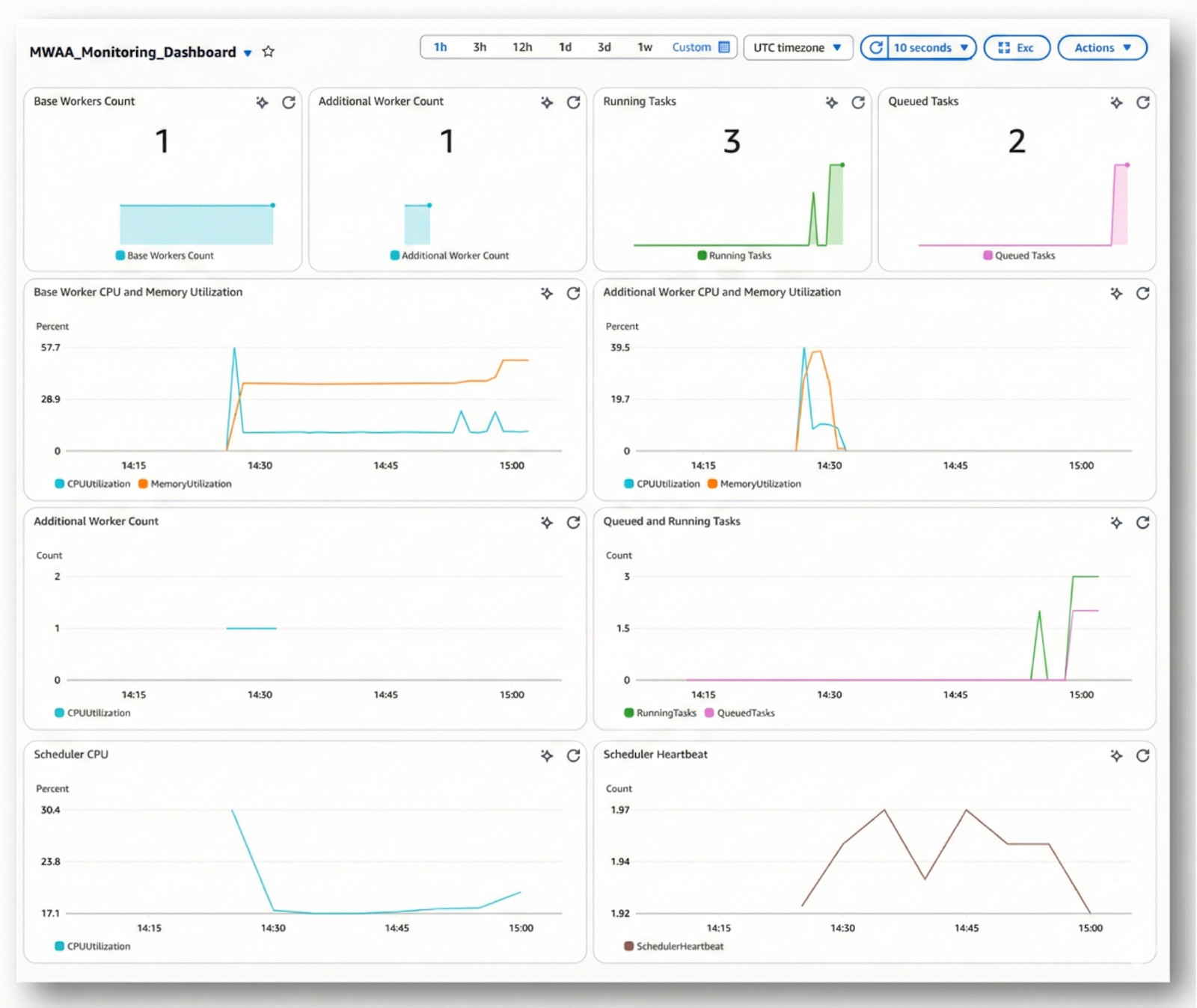
여러 파일을 동시에 업로드하여 병렬 Task가 증가하는 상황을 가정하고 MWAA의 확장성을 확인했습니다. 작업량이 급증하면 Worker가 처리하지 못한 작업이 큐에 쌓이게 되며, 이때 MWAA는 자동으로 Worker를 확장합니다. CloudWatch 모니터링 대시보드를 통해 Additional Worker, Queued Tasks, Running Tasks 등의 지표가 실시간으로 변하는 모습을 확인할 수 있습니다. 작업량이 줄어들면 Worker는 감소하며, 이를 통해 MWAA의 자동 확장 기능과 병렬 처리 효율성을 확인할 수 있습니다.
