
[reinvent 2025] Cisco Data Fabric을 통해 혼돈 속에서 명확성을 찾아보세요 (Splunk가 후원)
Summary
해당 세션에서는 2028년 394 제타바이트(Zettabytes)에 이를 것으로 예상되는 데이터 폭증 시대에, Cisco Data Fabric powered by Splunk가 어떻게 데이터 카오스를 명확성(Clarity)으로 전환하는지 다룹니다. 바이오테크 기업 Regeneron의 사례를 통해 머신 데이터와 AI를 결합하여 실험 속도를 높이고 생명을 구하는 혁신을 소개하며, 저장과 인덱싱을 분리한 새로운 ‘Machine Data Lake’ 아키텍처를 공개합니다.
리인벤트 2025 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며
“만약 브라질에서 나비가 날갯짓을 하면 텍사스에 토네이도가 일어날까요?” 1960년대 에드워드 로렌츠 박사가 제기한 ‘나비 효과(Butterfly Effect)’는 복잡한 엔터프라이즈 IT 환경에서도 유효합니다. 서버 온도의 0.5도 변화나 로드 밸런서의 미세한 성능 저하가 전체 비즈니스의 중단을 초래할 수 있기 때문입니다. 해당 세션을 통해, AI 에이전트가 24시간 시스템을 모니터링하며 데이터 폭증을 주도하는 Agentic 시대에서 기업이 어떻게 데이터의 혼란(Chaos)을 잠재우고 비즈니스 통찰력으로 연결할 수 있는지 Splunk와 Cisco의 새로운 전략을 통해 알아보겠습니다.

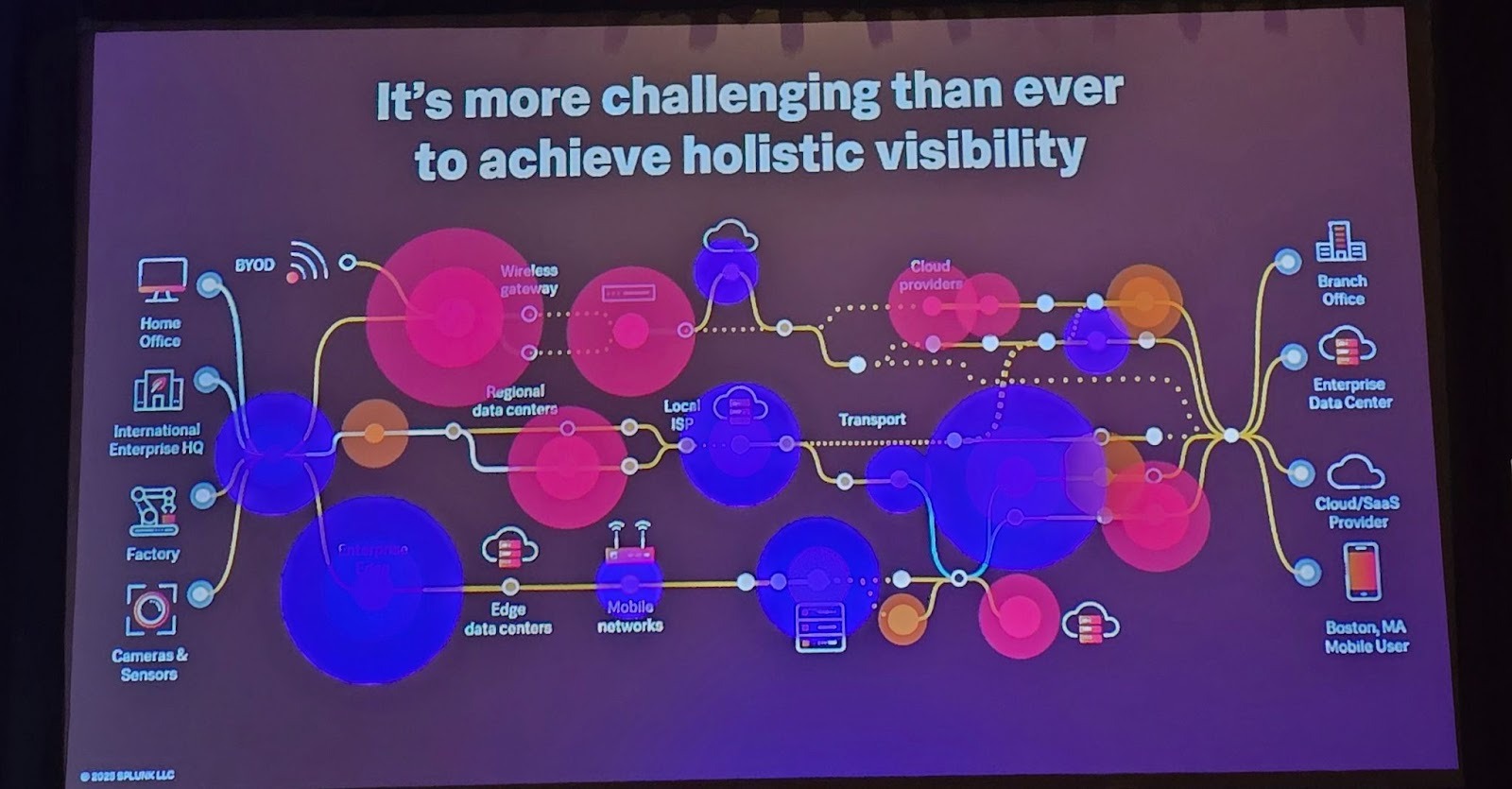
1. 181 제타바이트의 시대와 ‘데이터 카오스’
인류는 전례 없는 데이터 폭증의 시대를 맞이하고 있습니다. 스피커는 2024년 말까지 전 세계 데이터 양이 181 제타바이트(Zettabytes)에 달하고, 2028년에는 394 제타바이트까지 늘어날 것이라 경고했습니다. 1 제타바이트의 HD 비디오를 시청하려면 무려 3,600만 년이 걸리는 엄청난 양입니다.


- 변화의 원인: 과거에는 사용자가 질문을 던질 때만 데이터 스파이크가 발생했지만, 이제는 AI 에이전트가 인간을 대신해 24시간 내내 시스템을 모니터링하고 작업을 수행하며 끊임없이 머신 데이터를 생성합니다.
- 문제점: 데이터는 보안, IT, 엔지니어링 등 각 팀의 사일로(Silo)에 갇혀 있으며, 중복 저장되고 파편화되어 엔드 투 엔드(End-to-End) 가시성을 확보하기 어렵습니다. 이러한 ‘데이터 카오스’는 기업에 연간 4,000억 달러 규모의 손실을 입히는 문제입니다.
2. Regeneron 사례: 생명을 구하는 데이터 가시성
바이오테크 기업 Regeneron은 Splunk를 통해 데이터가 단순한 숫자가 아니라 생명을 구하는 도구임을 증명했습니다.
- 도전 과제: 과학자들은 실험이 완료될 때까지 실험실의 단일 스크린 앞을 지켜야 했습니다.
- 해결책: Splunk와 Cisco의 솔루션을 통해 캠퍼스 어디서든 여러 실험을 동시에 모니터링할 수 있는 ‘단일 창(Single Pane of Glass)’ 환경을 구축했습니다.
- 결과: 작은 과학자 팀이 마치 거대한 팀처럼 효율적으로 움직일 수 있게 되었고, 생명을 구하는 치료제의 출시 속도를 획기적으로 단축했습니다.
3. Cisco Data Fabric powered by Splunk: 아키텍처의 진화
이번 세션의 핵심은 ‘Cisco Data Fabric powered by Splunk’의 공개였습니다. 이는 비즈니스 데이터, 지식(Knowledge) 데이터, 그리고 머신 데이터를 하나로 통합하는 플랫폼입니다.

- AI 기반 데이터 관리 (Auto-healing Pipelines): 밤새 데이터 다운로드가 실패하여 아침부터 복구 작업을 해야 했던 악몽은 사라집니다. AI가 데이터 파이프라인의 오류를 감지하고 자동으로 복구(Auto-healing)하며, 스키마 변경(Schema Drift)을 감지하여 자동으로 필드를 추출합니다.
- 연합 검색 (Federated Search): 데이터가 S3, Azure, Snowflake, 온프레미스 어디에 있든 이동시키지 않고 즉시 검색하고 분석할 수 있습니다.
- Machine Data Lake (MDL): 가장 큰 기술적 변화는 ‘수집(Ingestion)’과 ‘인덱싱(Indexing)’의 분리입니다. 모든 데이터를 비싼 인덱서에 즉시 넣는 대신, 저렴한 개방형 스토리지(Machine Data Lake)에 원본 그대로 저장(Iceberg 포맷 등 개방형 포맷 활용)합니다. 이후 가치가 확인된 데이터만 Splunk 인덱스로 ‘승격(Promote)’시켜 분석하거나, 데이터 사이언스 팀을 위해 레이크하우스로 내보낼 수 있습니다. 이를 통해 비용 효율성과 데이터 활용성을 극대화합니다.
4. 에이전틱 AI 경험 (Agentic AI Experience)
Splunk는 SPL(Splunk Processing Language)을 몰라도 자연어로 데이터를 질의할 수 있는 ‘SPL Agent’를 소개했습니다.

- 자연어 쿼리: “지난주 로그인 실패 추이를 보여줘”라고 물으면 AI가 이를 SPL로 변환하여 실행하고, 반대로 복잡한 SPL 쿼리가 무슨 뜻인지 자연어로 설명해주기도 합니다.
- AI 비서의 활약: 데모에서는 AI 어시스턴트가 AWS CloudTrail 로그의 스키마 변경을 감지하고, 이에 맞는 파이프라인 수정 규칙을 제안하여 클릭 한 번으로 문제를 해결하는 과정을 보여주었습니다. 이는 분석가가 며칠 걸려 찾을 문제를 단 몇 초 만에 해결하는 ‘나비 효과 방지’의 실사례입니다.
결론
Cisco Data Fabric은 머신 데이터를 AI의 연료로 사용하여, 80억 인구가 마치 800억 인구의 역량을 발휘할 수 있도록 돕는 것을 목표로 합니다. 이번 세션은 단순히 로그를 수집하고 검색하는 것을 넘어, ‘데이터를 어디에 저장하고 어떻게 처리할지’에 대한 결정권을 사용자에게 돌려주었다는 점에서 의의가 있습니다. Machine Data Lake를 통한 비용 최적화와 AI 에이전트를 통한 운영 자동화는 다가오는 제타바이트 시대를 대비하는 기업들에게 필수적인 나침반이 될 것으로 보여집니다.
글 │메가존클라우드, Cloud Technology Unit (CTU) AWS Delivery SA 2 팀 서해민 SA
게시물 주소가 복사되었습니다.
