
[reinvent 2025] Observability를 활용해 신뢰할 수 있고 책임 있는 AI 애플리케이션을 구축하기
Summary
Amazon Bedrock Guardrails와 Amazon CloudWatch Observability는 생성형 AI 애플리케이션의 안전성, 투명성, 거버넌스를 End-to-End로 보장합니다.
이 프레임워크는 유해 콘텐츠 차단, 민감 정보 보호, 모델 행동 분석을 통해 책임 있는 AI 운영을 가능하게 합니다.
실시간 텔레메트리 기반의 인사이트와 자동화된 대응을 통해 조직은 AI 리스크를 최소화하고 비즈니스 가치를 극대화할 수 있습니다.

Overview
들어가며
조직이 생성형 AI 애플리케이션에 투자하고 서비스를 운영하기 시작하면, 리더와 개발자는 밤잠을 설치게 만드는 세 가지 질문과 마주하게 됩니다.

- 우리의 AI 애플리케이션이 책임감 있게 사용되고 있는가?
— 실제 고객들이 가장 먼저 던지는 질문입니다. - 사용자 또는 모델이 민감한 정보를 무단 사용자에게 노출하는 상황을 어떻게 감지할 것인가?
— 66%의 경영진은 데이터 프라이버시와 보안을 AI의 가장 큰 위험으로 인식하고 있습니다. - AI 비용 지출(AI spend)이 실제 비즈니스 가치를 창출하고 있는가?
아니면 혼란·노이즈·법적 리스크만 증가시키고 있는가?
이 질문들은 실제로 AWS가 기업 고객과의 현장에서 가장 많이 듣는 고민입니다.
이번 세션에서는 위 질문을 해결하기 위해 AWS가 제공하는 Amazon Bedrock Guardrails와 Amazon CloudWatch Observability 기반의 책임 있는 AI(Responsible AI) 구축 프레임워크를 통하여 책임있는 AI 애플리케이션을 만드는 방안에 대하여 알아봅니다.
1. 생성형 AI 애플리케이션이 직면하는 4가지 핵심 도전 과제
생성형 AI는 기업에 큰 혁신을 가져오지만, 동시에 새로운 위험 요소도 만들어냅니다. AWS는 실제 고객 사례를 통해 다음 네 가지가 엔터프라이즈 환경에서 가장 중요한 리스크라고 정의합니다.

1. 바람직하지 않거나 무관한 주제
모델이 논란이 되는 질문이나 맥락과 맞지 않는 주제에 응답할 수 있습니다. 이로 인해 정책 위반, 브랜드 신뢰도 하락, CS 오류 등이 발생할 수 있습니다.
2. 유해성(Toxicity) 및 안전성 문제
모델이 공격적·유해한 콘텐츠를 생성하면 기업은 법적 리스크와 브랜드 손상에 노출됩니다.
3. 개인정보 및 민감 정보 보호
프롬프트나 응답을 통해 개인정보가 노출될 수 있으며, 이는 규제 위반으로 이어집니다.
4. 모델 환각(Hallucination)
모델이 사실이 아닌 정보를 생성하는 현상은 금융·의료·법률 등에서 치명적 문제를 일으킬 수 있습니다.
2. Responsible AI 프레임워크
Responsible AI를 구축하기 위해 AWS는 애플리케이션의 전 수명주기에 걸친 세 가지 핵심 단계를 제시합니다.
예방(Prevention) → 탐지(Detection) → 대응(Action)까지 완성하는 책임 있는 AI 운영의 필수 단계입니다.

3. Amazon Bedrock Guardrails — 안전을 강화하는 통제 레이어
예방 관점에서 AWS Bedrock Guardrails는 생성형 AI 모델 위에 추가적인 안전·정책 Enforcement Layer를 제공합니다.

1) 콘텐츠 기반 제어
허용/차단할 콘텐츠 유형 설정, 특정 단어·구·주제 기반 Rule 설정, 기업 정책에 맞지 않는 요청/응답 자동 차단이 가능합니다. 최대 88%의 위험 콘텐츠 차단 가능하였습니다.
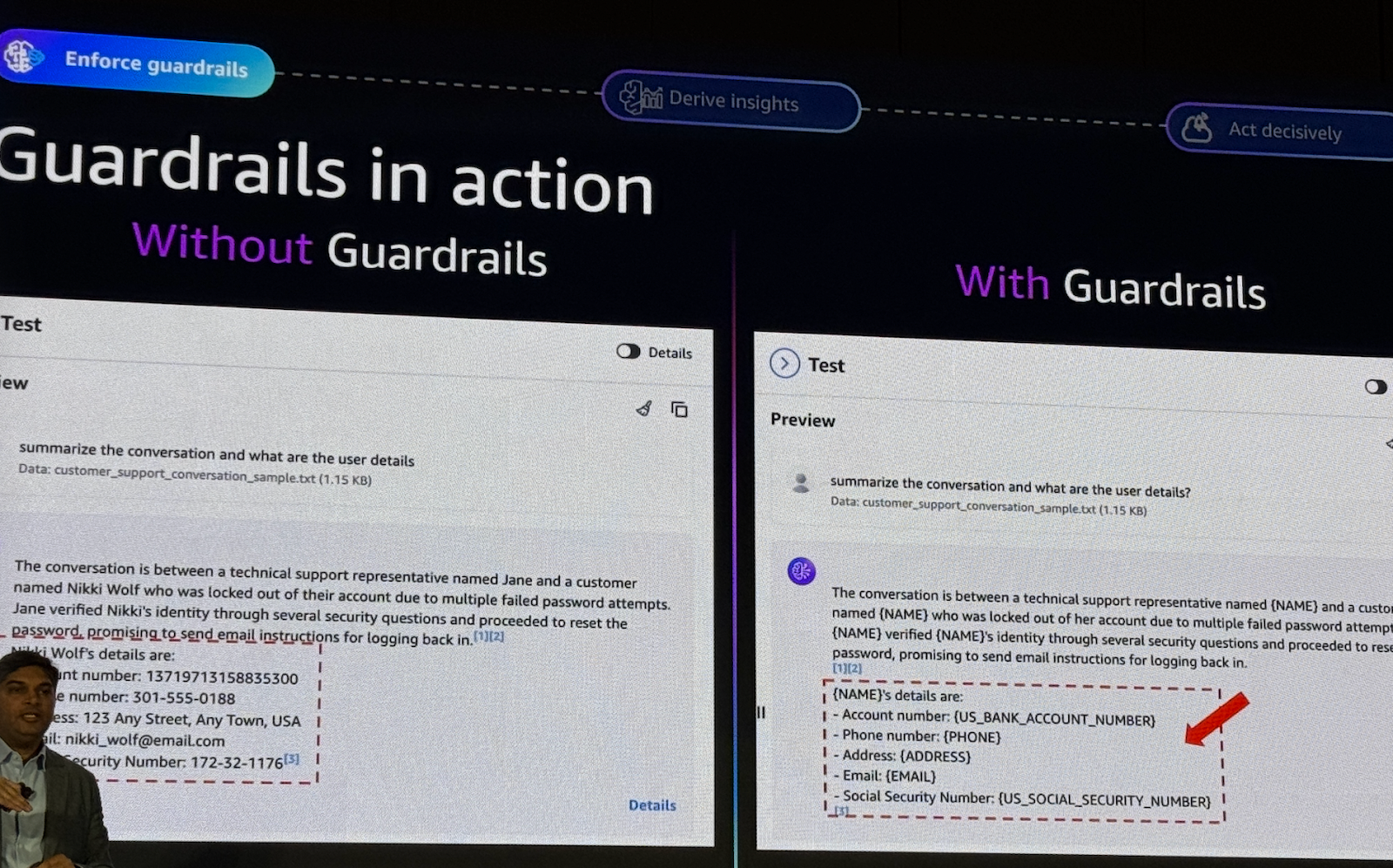
2) 민감한 정보 보호
이메일, 전화번호, SSN 등 100+ 유형 자동 감지, 익명화(Anonymization) 또는 완전 차단(Block), 모델 응답 레벨과 프롬프트 입력 레벨 모두 제어 가능합니다.
3) Hallucination 억제
기업 데이터에 없는 정보를 요구할 때, Guardrails가 개입해 “데이터 없음” 응답 또는 커스텀 메시지 제공합니다.
Guardrails는 시스템/정책/Security 팀이 정의한 기준을 모델 레이어에서 직접 강제합니다.
4. Amazon CloudWatch — AI Observability의 중심
Guardrails는 안전을 제공하지만, CloudWatch Observability는 “무슨 일이 실제로 일어나는지”를 보여주는 핵심 도구입니다.
CloudWatch는 Guardrails 텔레메트리 수집을 추가 계측 없이 자동으로 수행하며 기본 제공 대시보드만으로도 여러가지 상황을 분석할 수 있습니다.
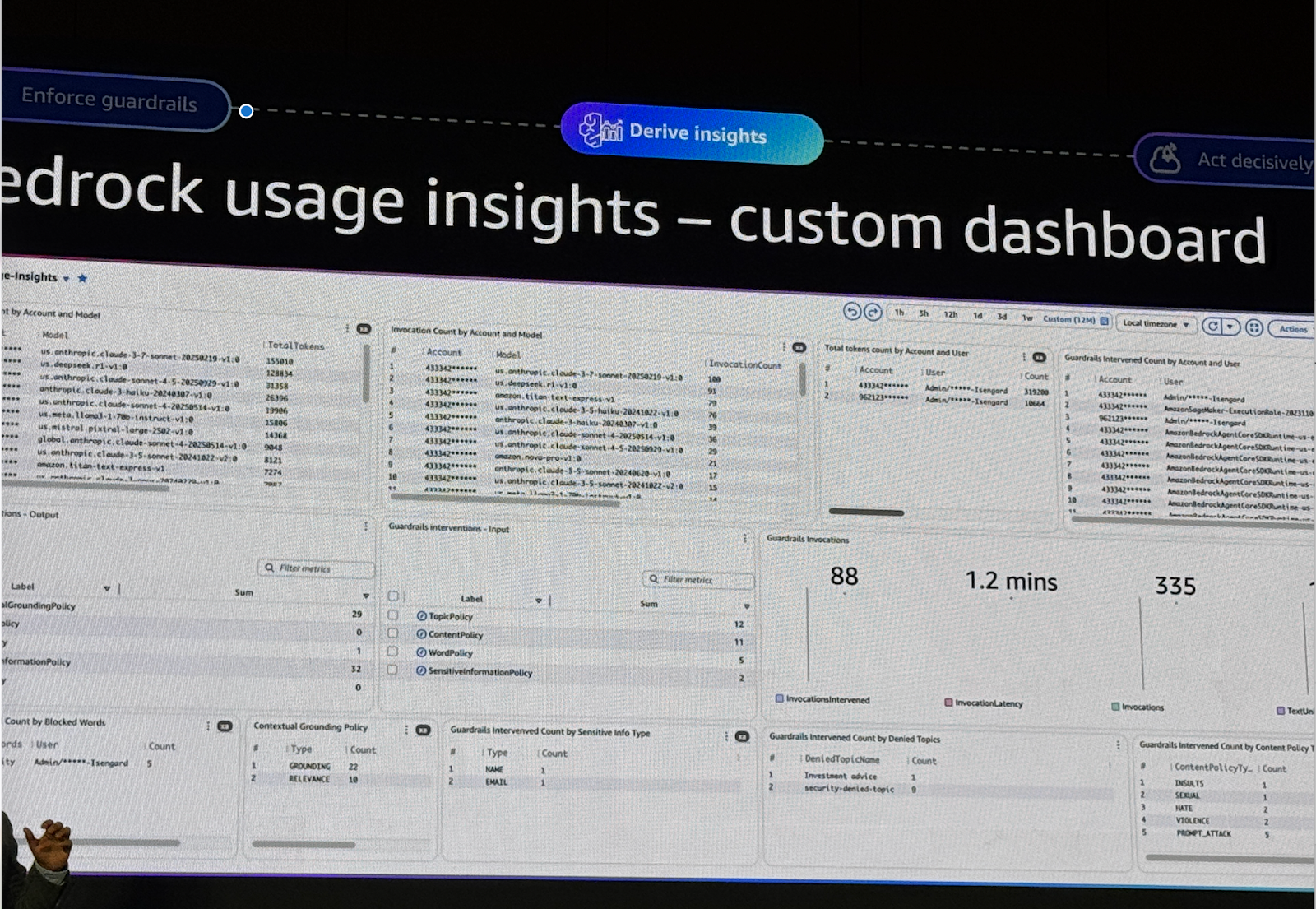
전체 모델 호출 대비 Guardrails Intervention 비율, 모델별/지역별/계정별 사용량, 민감한 정보 탐지/차단 현황, Prompt Attack 지수, Latency 및 운영 성능 지표 등을 볼 수 있습니다.
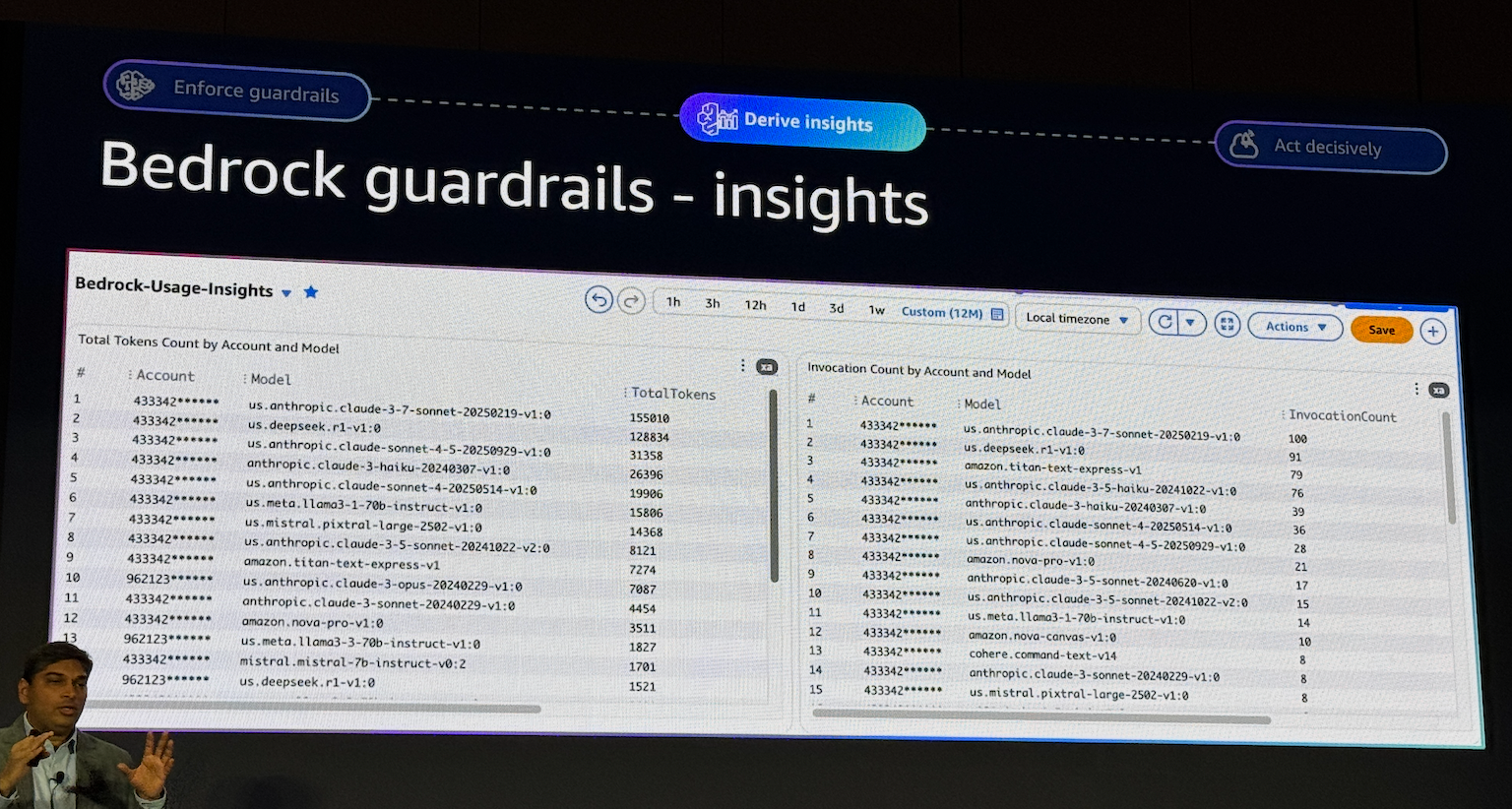
특정 Account와 모델별로 토큰 사용량을 파악하고, 호출 횟수(Invocation Count)를 모니터링하는 것은 추후 최적의 모델을 선정하는 데 유용한 지표가 됩니다.
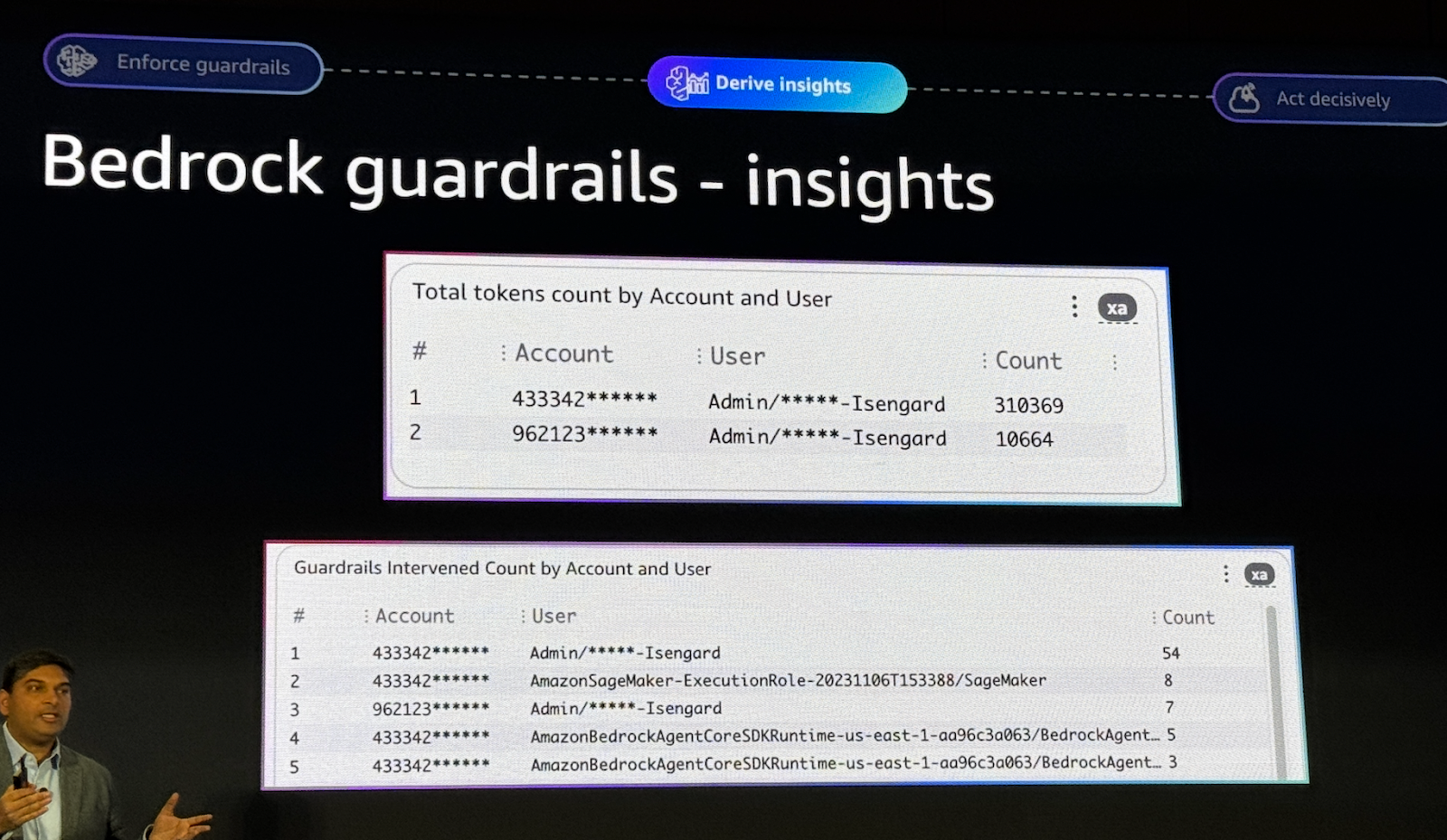
멀티 계정들에대한 모니터링 및 유저를 식별하는데도 직관적인 가시성을 제공합니다.
5. 인사이트를 기반으로 한 자동 대응 — CloudWatch Alarms
Insight → Action을 완성하기 위해 CloudWatch Alarms로 다음과 같은 자동 대응을 구성할 수 있습니다.
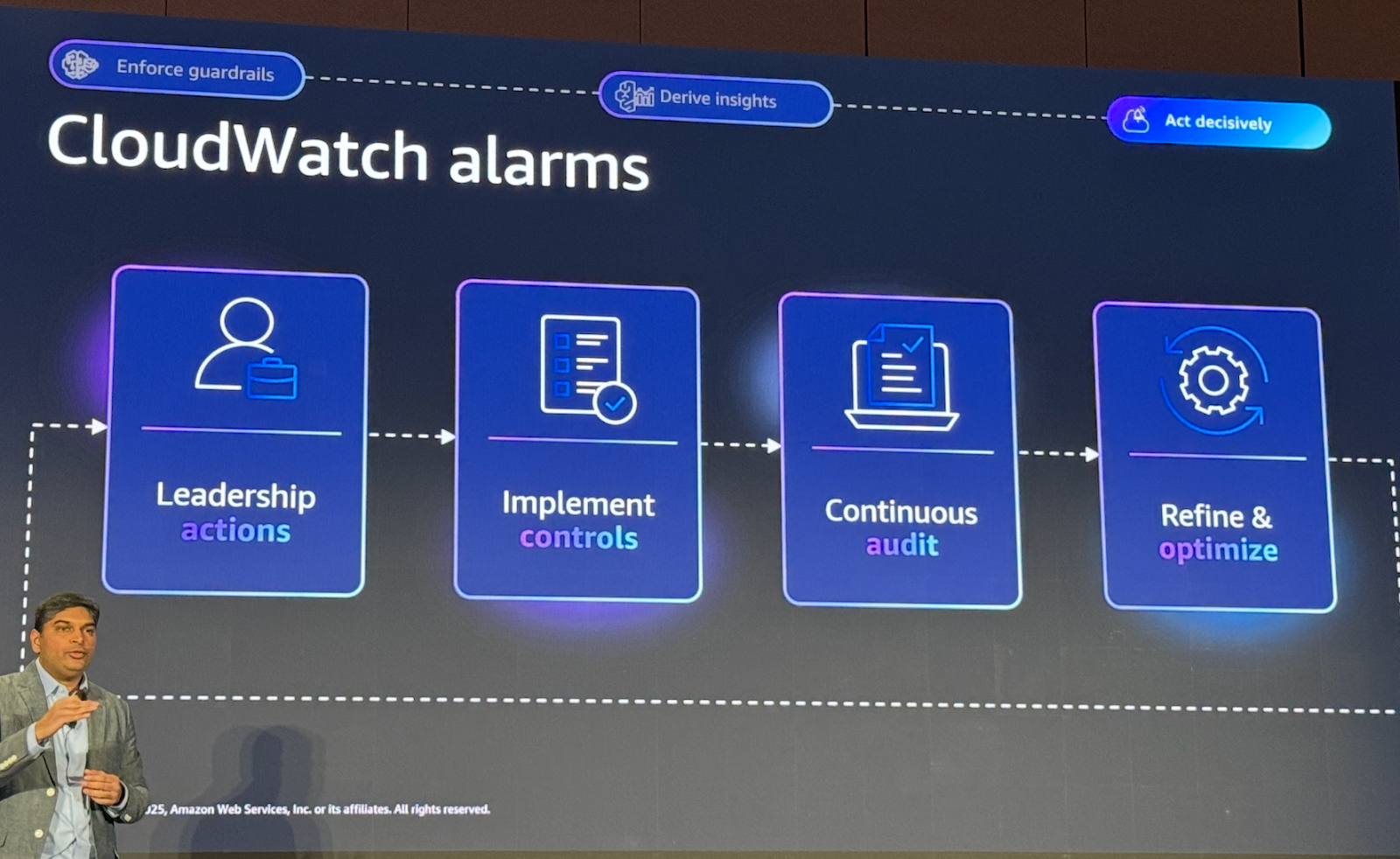
Guardrails Intervention이 특정 임계값 초과하거나, Prompt Attack 발생, 민감 정보 노출 시도 파악, 모델 호출 오류율/Latency 증가하는 경우에 알람을 구성합니다.

AI를 관리하는 리더십 팀이 알람을 받는 즉시 컨트롤 수행, 지속적인 Audit, Remediation이 가능합니다.
결론
AWS는 Amazon Bedrock Guardrails + Amazon CloudWatch Observability 조합을 통해 AI 애플리케이션이 다음 조건을 모두 충족하도록 돕습니다.
- 안전성(Safety)
- 투명성(Transparency)
- 거버넌스(Governance)
- 비용/성능 최적화
- 데이터·사용자·모델 흐름에 대한 End-to-End 가시성
고객은 이를 기반으로 책임 있는 AI 시스템을 운영하고, 규제 준비성을 갖추고,안전하고 신뢰할 수 있는 비즈니스 애플리케이션을 구성할 수 있습니다.
