
[reinvent 2024] 관리형 Apache Kafka와 Apache Flink 클러스터 운영과 확장
Summary
기업들은 Apache Kafka와 Apache Flink를 실시간 분석, 애플리케이션 메시징, 머신 러닝등을 위해 사용하고 있는데 이러한 사용 규모가 증가함에 따라 클러스터의 관리도 중요해지고 있습니다. AWS 고객들이 Amazon MSK와 Amazon Managed Service for Apache Flink의 높은 가용성과 내구성을 유지하면서도 더 낮은 비용과 단순하게 운영할 수 있는 방법을 배워보는 세션입니다.
리인벤트 2024 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며
이번 칼럼에서 다룰 세션은 스트리밍 데이터를 처리할 때 사용하는 Apache Kafka와 Apache Flink의 스케일을 관리 및 운영하는데 도움이 되는 방법들을 알아보는 세션입니다.
이 서비스들은 비용이 저렴하지 않기 때문에 스케일을 구성할 때 기준을 궁금해하시는 고객분들이 많은데요
이번 세션을 통해 스케일을 구성할 때 도움이될 요소들과 운영 관점에서 고려해야할 요소들을 공유드리겠습니다.
(해당 컬럼에서는 분량관계로 Kafka에 대한 부분만 자세히 다룹니다.)

Why streaming?
우리가 스트리밍 데이터에 주목하는 이유는 즉각적인 피드백 때문입니다.
금융, 소매 등등의 비즈니스에서 당연히 이벤트가 발생하고 한참 후 알람, 결과를 내놓는 것보다 즉각적으로 피드백을 주는게 중요하기 때문입니다. 특히 비용은 최우선 관심사인데 모든 데이터를 저장하고 이후에 처리하여 인사이트를 얻는 것 보다 스트리밍 데이터에서 노이즈를 필터링하고 빠르게 피드백을 얻는게 비용을 절감할 수 있기 때문입니다.

스트리밍 애플리케이션을 구축할 때 kafka로 대량의 데이터를 캡쳐하고 이를 flink로 처리하는 구조로 사용합니다.
두 서비스의 공통점은 위와 같고 대표적으로 둘 다 확장형 아키텍처를 가져서 처리할 데이터가 많아도 걱정할 필요가 없습니다.

그렇지만 Apache Kafka와 Flink를 사용하는데 위와 같이 신경써야 하는 것들이 많습니다.
이러한 점들을 AWS 관리형 서비스를 이용해서 인프라 관리, 위와 같은 어려운 작업들을 AWS에 맡김으로써 어려움을 해결하고 애플리케이션 구축과 운영에 집중할 수 있습니다.
Kafka Planning

일단 Kafka의 컨셉을 먼저 보자면 Kafka 클러스터는 브로커로 구성되며, 각 브로커는 컴퓨트 레이어와 스토리지 레이어를 포함해서 데이터 검색, 인증 및 권한 부여를 처리합니다.
클라우드 환경에서는 EC2 인스턴스인 브로커에 문제가 생겨도 스토리지인 EBS는 손실되지 않아서 복구 시간이 단축됩니다.
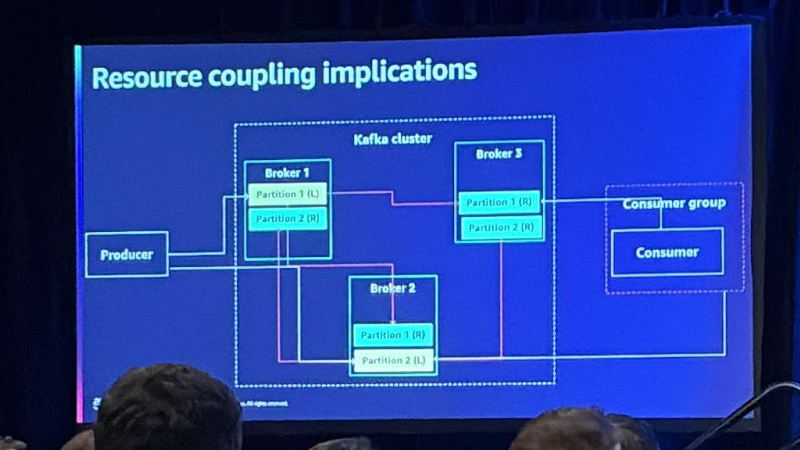
클러스터 구성에서 자원간 의존성에 대해 살펴보겠습니다.
리더 파티션이 있는 브로커의 장애 발생 시, Kafka는 복제본이었던 파티션을 새로운 리더로 선출하고, 이 브로커가 받는 데이터양이 많아지게 됩니다 이러한 과정은 데이터 처리량에 영향을 줄 수 있습니다.
다시 브로커가 정상이 됐을 때 그동안의 데이터를 따라잡아야 하는데 이 과정은 추가적인 데이터 처리가 필요하기 때문에 클러스터 가용성이 저하될 수 있습니다.
이러한 문제들 뿐만 아니라 인스턴스 사양, 최대 트래픽, cpu/메모리, 스토리지 등 이러한 모든걸 고려해서 클러스터를 구성해야 합니다.
Operating with high availability

첫번째로 Kafka의 구성이 올바른지 확인해야 합니다. 주요 구성 요소는 Replication Factor, minimum in-sync replica, unclean election 입니다. 아래에 세부 구성에 대해 설명드리겠습니다.
- Replication Factor를 3으로 설정하여 세 가지 가용 영역에 걸쳐 고가용성과 높은 내구성을 확보하실 수 있습니다.
- minimum in-sync replica에서 최소 개수를 설정하여 데이터 내구성 문제에 대한 도움을 받을 수 있습니다.
- unclean leader election은 false로 설정해서 데이터 일관성을 유지하실 수 있습니다.
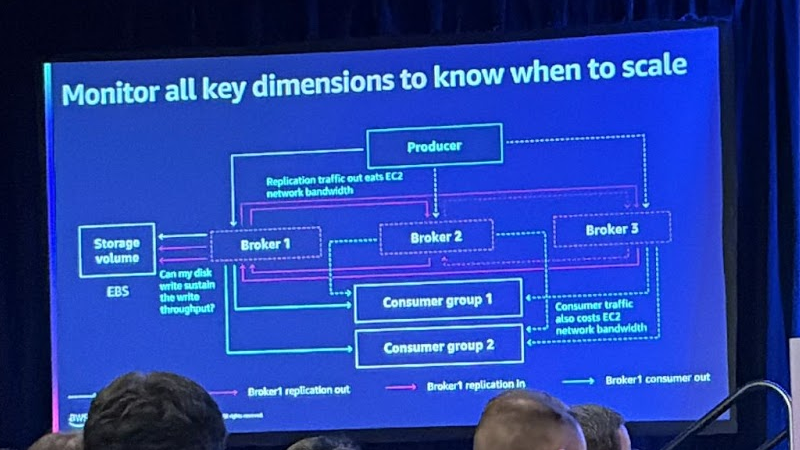
두 번째로 중요한 점은 올바른 메트릭을 확보하는 것 입니다. 만약 Kafka의 디스크가 가득차면 브로커가 테일스핀 상태에 빠지고 비정상적으로 종료된다음 수동 복구에 많은 시간을 소비하게 됩니다. 또한 스토리지 추가는 빠르게 이루어질 수 있는 작업이 아닙니다.
볼륨 처리량이 부족한 경우도 많은 요청이 큐에 걸리게 되고 브로커가 좋지 않은 상태에 빠질 수 있습니다.
이러한 문제점들을 사전예방하기 위해 스토리지를 추가할 지표를 정하고 모니터링하고 알림을 보내는 방법 등을 구성해야합니다. 그렇지 않으면 클러스터 전체가 불안정해 질 수 있습니다.
Scale
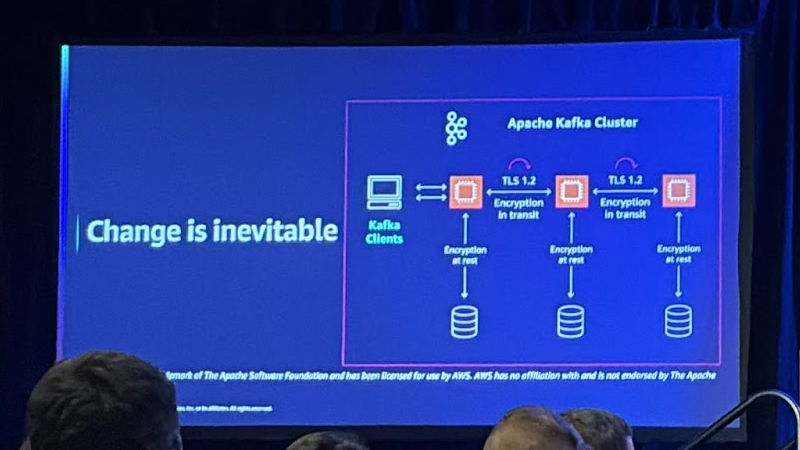
세 번째로 스케일 조정에 대한 설명입니다. 처리해야할 양이 많아지면 스케일 조정은 피할 수 없는 요소인데요.
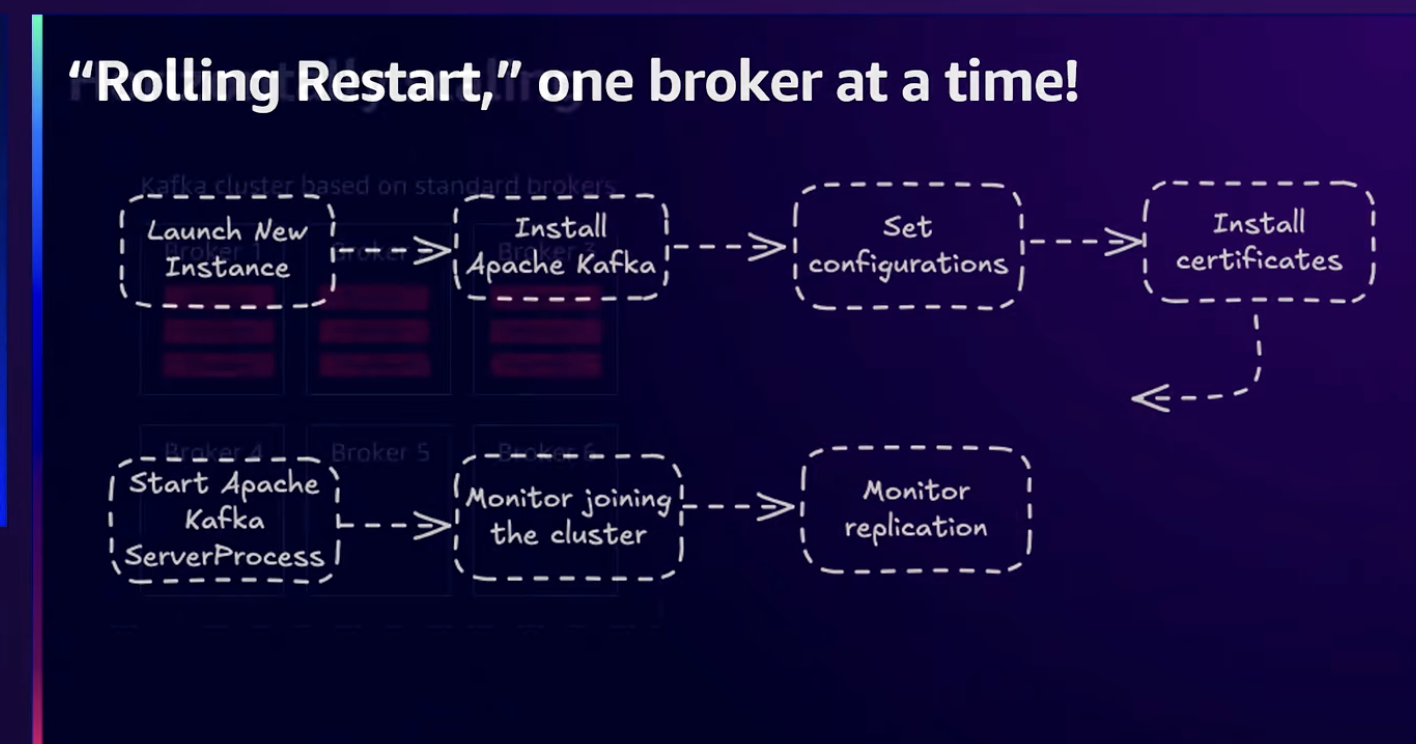
위 맵을 통해 Scale 조정에 대한 모범사례를 확인할 수 있습니다. 여기서 중요한 것은 롤링 재시작 순서입니다.
롤링 재시작은 분산 시스템에서 모든 노드를 한꺼번에 중단하지 않고, 한 번에 하나씩 순차적으로 재시작하는 방법을 말하는데 Kafka 클러스터를 롤링 재시작할 때 컨트롤러 노드는 항상 마지막에 재시작해야 합니다. 그렇지 않으면 컨트롤러 이동으로 인해 클러스터 불안정, consumer 타임아웃, 쓰기 지연 등의 문제가 발생할 수 있기 때문입니다.

다른 하나는 브로커를 추가하는 것입니다. 브로커를 추가 시 파티션을 리밸런싱해야 하는데 이는 다소 시간이 걸릴 수 있습니다. 이를 위해 리밸런싱 시 버퍼가 재조정 되어있는지 확인해야합니다.
Operate Apache Kafka at scale

- 스토리지 관리가 매우 복잡해 보이는데, 이를 고객들에게 어떻게 더 간단하게 만들 수 있을까?
- Kafka의 리소스 결합을 어떻게 간소화할 수 있을까?
- 고객들이 몇 분 안에 용량을 확장하거나 축소할 수 있도록 컴퓨팅 탄력성을 어떻게 더 쉽게 제공할 수 있을까?
- 이러한 모든 모범 사례를 제품에 어떻게 통합할 수 있을까?
이 모든 질문에 대한 해결책으로 Express Brokers for Amazon MSK라는 고성능 및 고탄력성을 제공하는 새로운 브로커 유형을 제공합니다.
Express broker
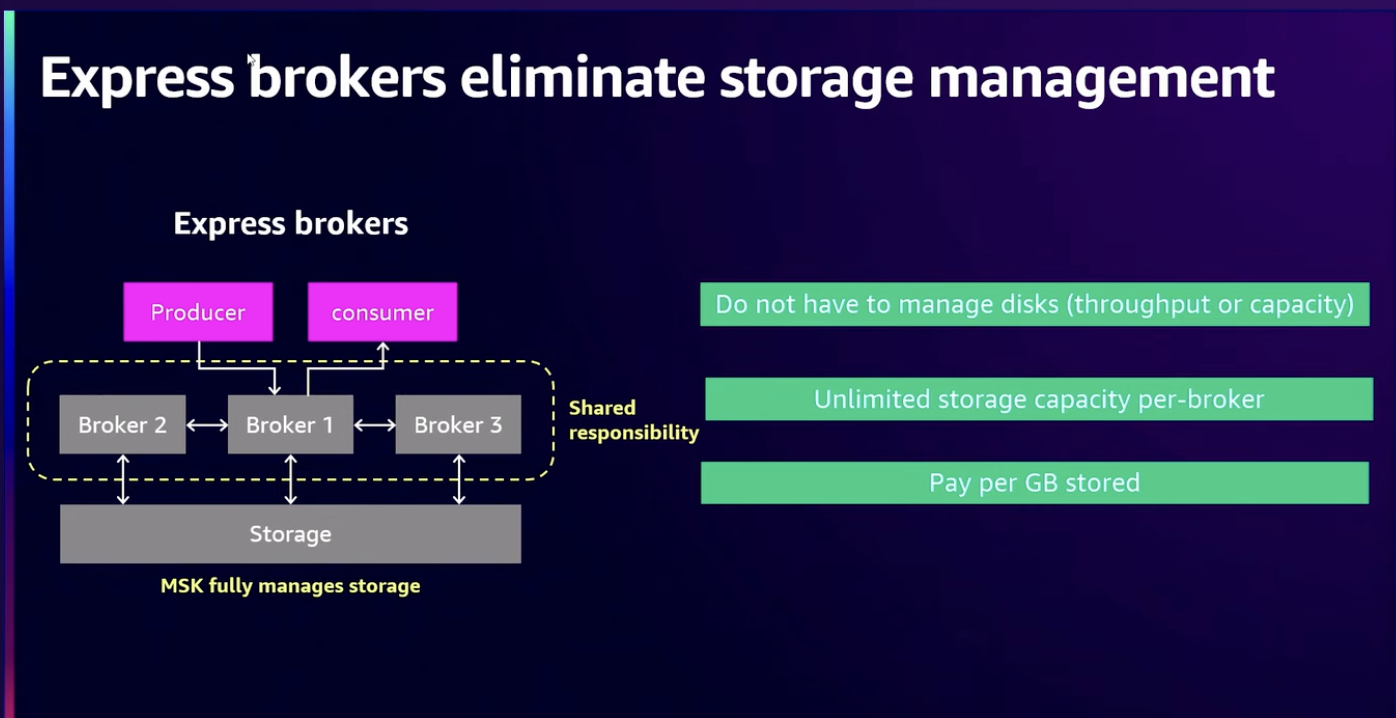
Express 브로커는 브로커당 무제한의 저장용량을 지원해서 이전에 디스크가 가득찼던 것은 더이상 문제가 되지 않으며 스토리지 구성을 걱정할 필요가 없습니다. 세그먼트 크기, 복제본 수 등을 AWS 에서 제어하고 관리합니다.
마지막으로 보유한 데이터 양에 따라 비용을 지불합니다.
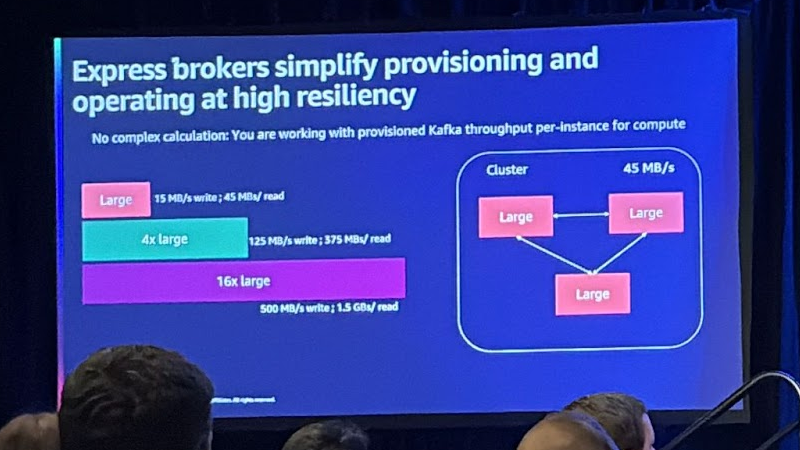
인스턴스 크기를 결정하는 것도 단순화됩니다. 브로커 선택 시 45 MiB/read의 클러스터를 원한다면 세 개의 브로커를 Large로 375MB는 4x large의 브로커로 선택하면 됩니다.
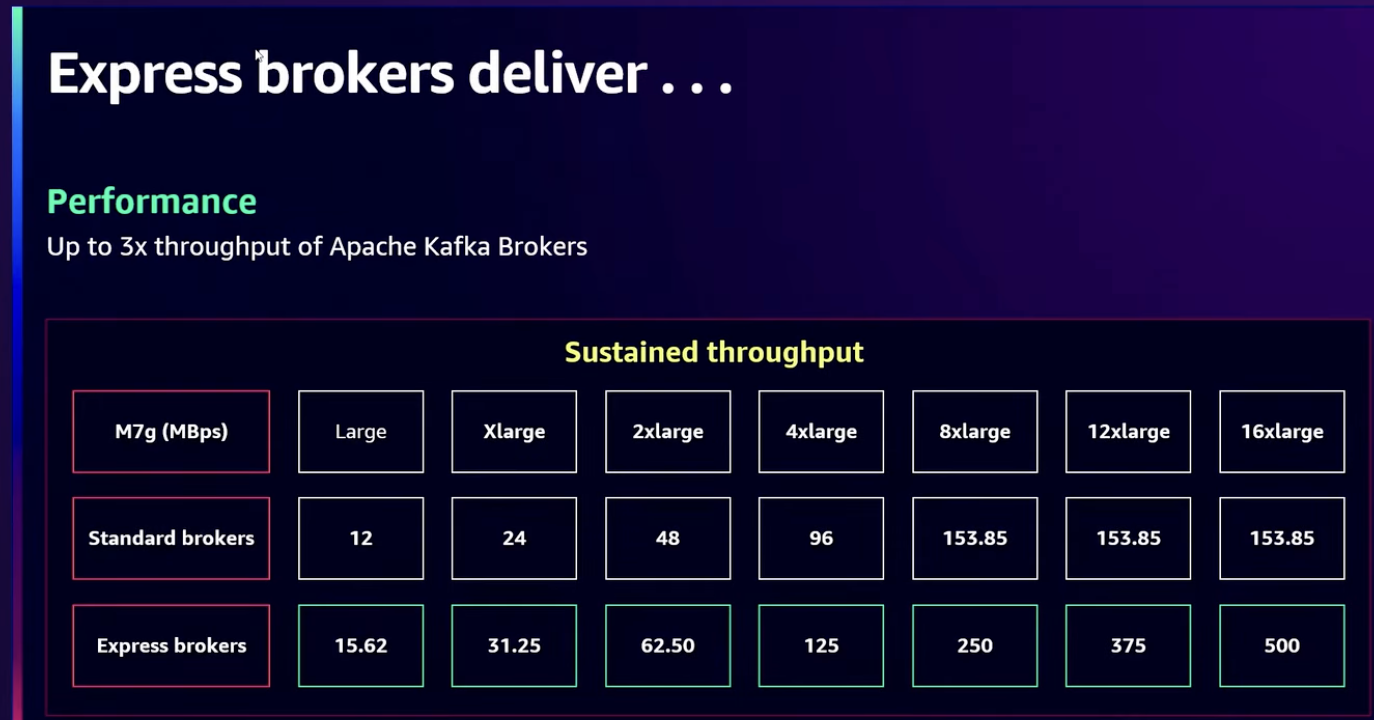
Express 브로커는 최대 3배 더많은 처리량을 지원합니다

Scaling에는 수직, 수평 scaling이 있는데, 수직 스케일링은 한 번의 클릭으로 인스턴스 유형 변경이 가능합니다. 이 작업은 애플리케이션이나 내구성에 영향을 미치지 않는 방식으로 수행됩니다.
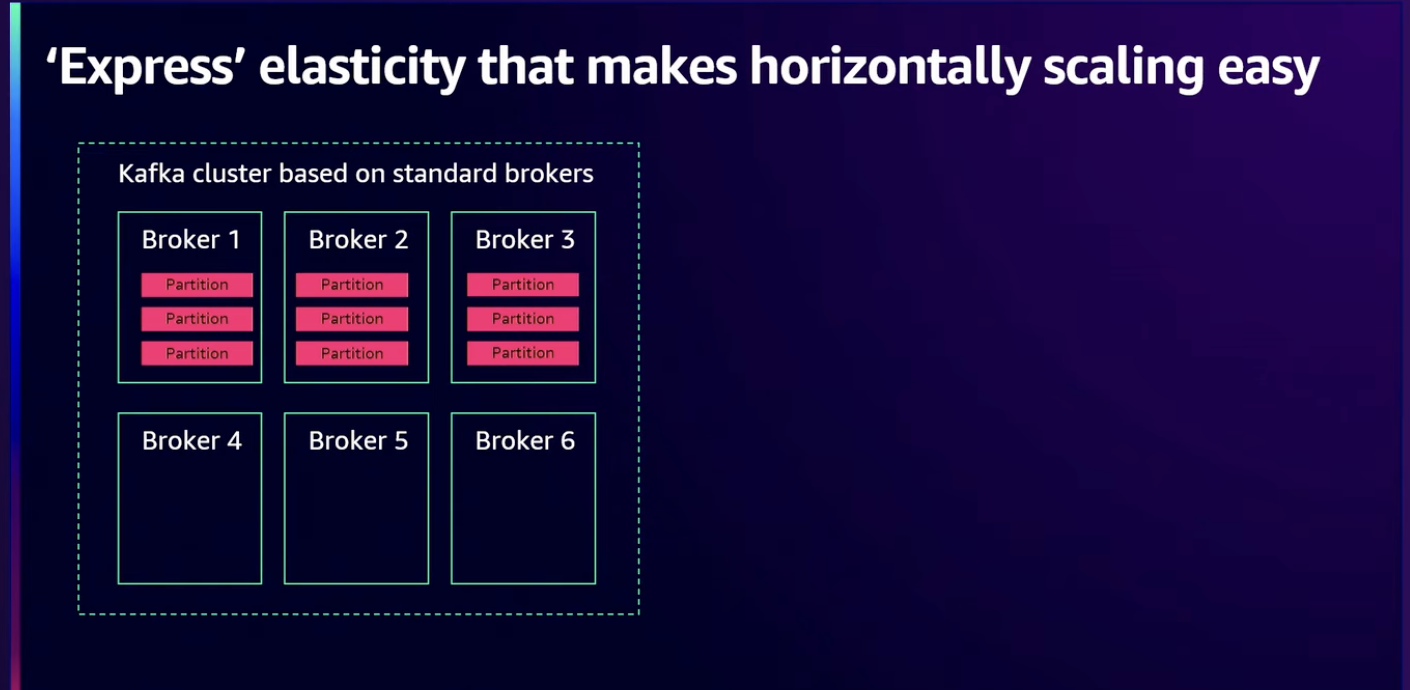
앞서 말씀드렸던 리밸런싱에서도 Express 브로커는 몇 분정도의 시간이 걸립니다.

Amazon MSK는 사용자의 요구 사항에 따라 세 가지 옵션(Standard, Serverless, Express Brokers)을 제공합니다. 아래 정보를 통해 브로커 선택에 도움이 될 수 있을 것 같습니다.
Standard Brokers:
제어와 유연성을 중시하며 Kafka 전문가를 위한 옵션. 가격 대비 성능이 뛰어남.
Serverless:
단순한 사용을 원하는 경우, 클릭 한 번으로 클러스터 생성.
Express Brokers:
탄력성, 확장/축소 기능, 자동화와 높은 가격 대비 성능을 원하는 사용자들에게 적합.
Express Brokers는 성능, 탄력성, 자동화의 균형을 필요로 하는 대부분의 Kafka 워크로드에 이상적인 선택지 입니다.
결론
이번 세션에서는 왜 스트리밍 데이터가 중요한지, Kafka 클러스터를 초기 셋팅할 때 고려해야할 요소가 무엇인지, 구성요소를 어떻게 설정해야 하는지, 구성하고 나서 스케일 조정을 위해 염두해야 하는 요소가 무엇인지 등에 대해 정보를 얻을 수 있는 세션이었습니다.
Apache Kafka를 사용하여 대규모 데이터를 처리하고 실시간 스트리밍 애플리케이션을 구축하는 데 있어서 AWS 관리형 서비스를 활용하면 인프라 관리에 대한 부담을 크게 줄일 수 있다는 점이 매우 유용하다고 느껴졌습니다. 또한, Express Brokers와 같은 새로운 브로커 유형을 통해 스토리지 문제와 성능 최적화를 쉽게 해결할 수 있다는 점에서, 기업들이 Kafka를 더욱 효율적으로 운영할 수 있을 것 같다고 느꼈습니다.
