
[reinvent 2024] AWS를 활용해 해결한 다양한 데이터 수집 사례
Summary
데이터 수집은 보통 데이터 파이프라인을 구축하는 첫 번째 단계입니다. 비정형 데이터, 증분 데이터, Apache Iceberg와 같은 오픈 테이블 형식 등 데이터 유형이 다양해지면서, 안정적인 데이터 파이프라인을 구축하고 데이터를 즉시 수집하여 원하는 스키마 구조를 적용하며, 다양한 사용 사례에 적합한 고품질 결과를 제공하는 것이 더욱 중요해졌습니다.
이번 세션에서는 다양한 데이터 수집 문제를 해결할 수 있는 구체적인 솔루션을 다룹니다. AWS Glue, Amazon Kinesis, Amazon Redshift, Amazon OpenSearch Service와 같은 서비스를 활용하여 데이터를 효율적으로 수집하고 처리할 수 있는 견고한 아키텍처와 핵심 전략에 대해 배울 수 있습니다.
리인벤트 2024 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며
이번 칼럼에서 다룰 세션에서는 현대 데이터 아키텍처 전략에 초점을 맞추어 데이터 수집 환경이 서비스에 따라 어떻게 변화했는지, 데이터 수집 사례에 어떤 것이 있는지, 데이터 수집을 효과적으로 하기 위해 다양한 툴과 서비스를 활용한 일반적인 아키텍처와 핵심 전략에 대해 설명합니다.


다양한 데이터 수집 전략을 알아보기 전에 데이터 수집 시 문제점에 대해 살펴보겠습니다.
다양한 소스 시스템(관계형 DB, 데이터 레이크 등)으로 인해 결합이 어려워지고 소비자가 데이터를 특정 방식이나 특정 형식으로 요구하는 경우가 많은데 이 때문에 ETL 작업이 수행되어야 하며 이로인해 데이터 준비 과정이 오래걸리는 문제점이 있습니다.
또한 비즈니스 요구사항에 따라 독자적인 데이터 세트가 생성되면서 데이터 사일로가 발생하는 등 여러 문제점들이 존재합니다. 이러한 문제들을 해결하기 위해 다양한 데이터 수집 아키텍처에 대해 알아보겠습니다.
Redshift 데이터 수집
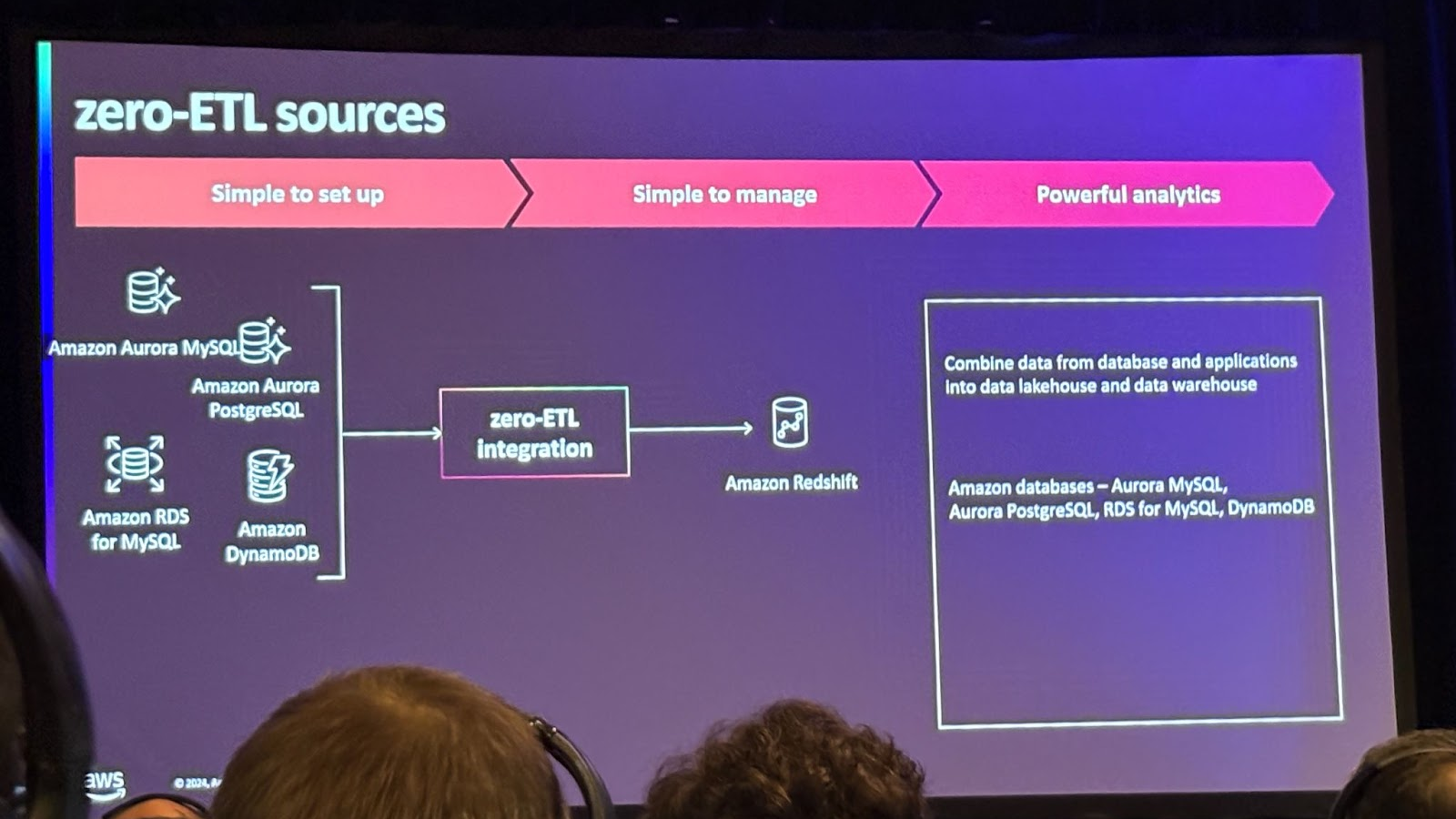
데이터 웨어하우스의 데이터 수집에 대해 살펴보겠습니다.
그 전에 Zero ETL에 대해 설명드리자면 사용자가 ETL 파이프라인을 생성하지 않아도 되는 point-to-point 데이터 이동 방식을 의미합니다.
AWS의 데이터웨어하우스 서비스인 Redshift에서 Zero ETL을 어떻게 활용할 수 있을까요?
처음에는 소스로 Amazon Aurora MySQL을 사용해 Redshift로 데이터를 로드하는데, 전체 스키마나 데이터베이스 데이터를 전송하는 옵션을 지원했습니다. 이를 개선해서 특정 테이블 포함 또는 제외 옵션을 통해 선택적으로 전송할 수 있게 되었습니다. 추가로 Amazon Aurora PostgreSQL, RDS MySQL, DynamoDB도 Zero ETL을 통해 Redshift와 통합할 수 있게 되었습니다.
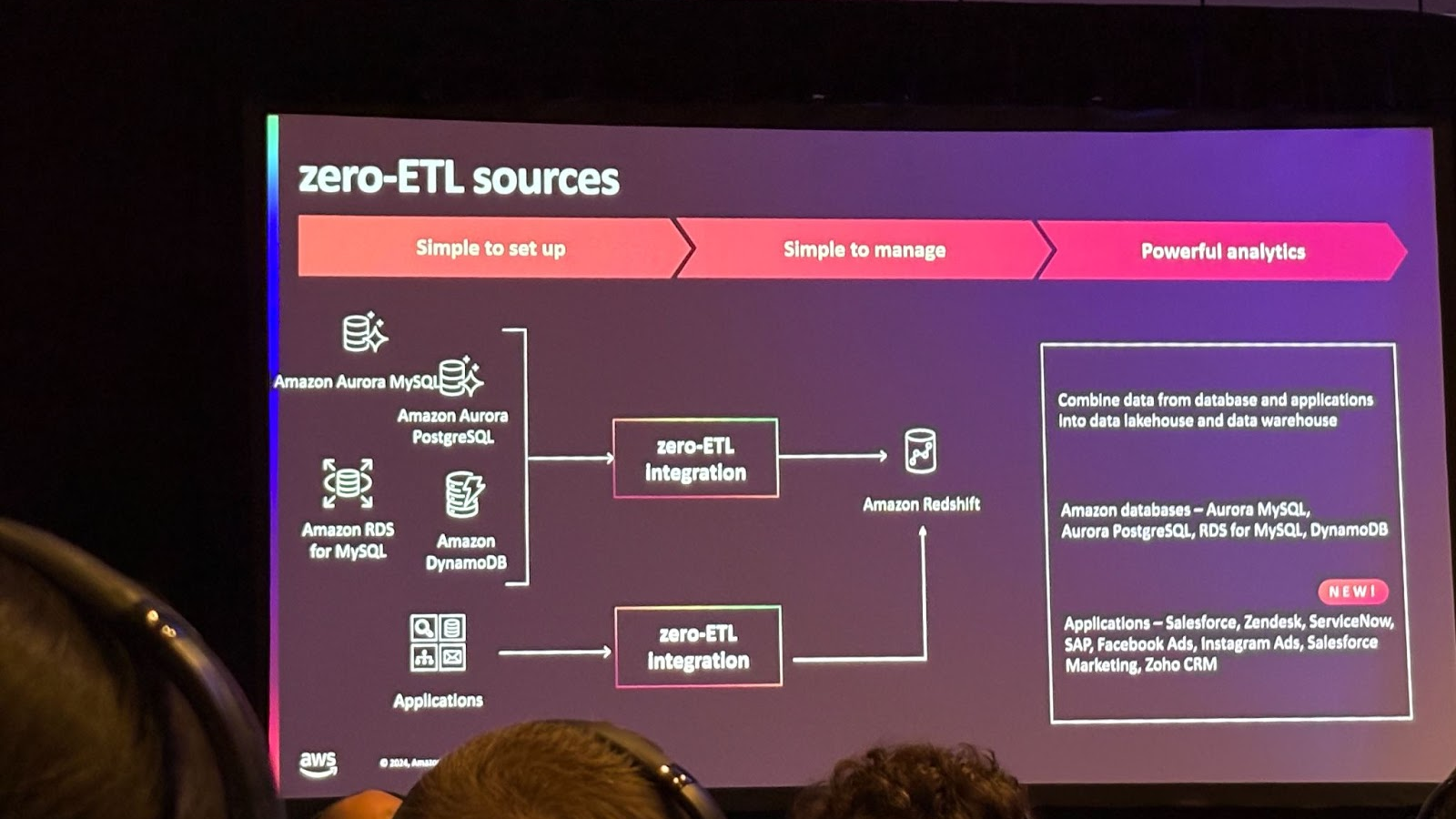
AWS 이외 서비스와도 통합하여 Salesforce, Zendesk, ServiceNow 같은 타사 애플리케이션과도 통합이 가능합니다. 다른 기능으로는 스트리밍 데이터 수집을 위해 Kinesis Data stream나 MSK를 사용하여 Redshift와 통합이 가능합니다.

다른 패턴으로는 외부에서 파일을 S3에 로드하거나, ETL 작업 후 데이터를 로드했을 때 이를 COPY 명령을 통해 Redshift에 로드하는 패턴이 있었고 이를 위해 오케스트레이션 작업이 필요했습니다. Auto-copy를 통해 초기 명령만 설정하면 이후 Redshift가 자동으로 데이터 전송을 처리하므로 job 오케스트레이션에 대한 부담이 감소되었습니다.
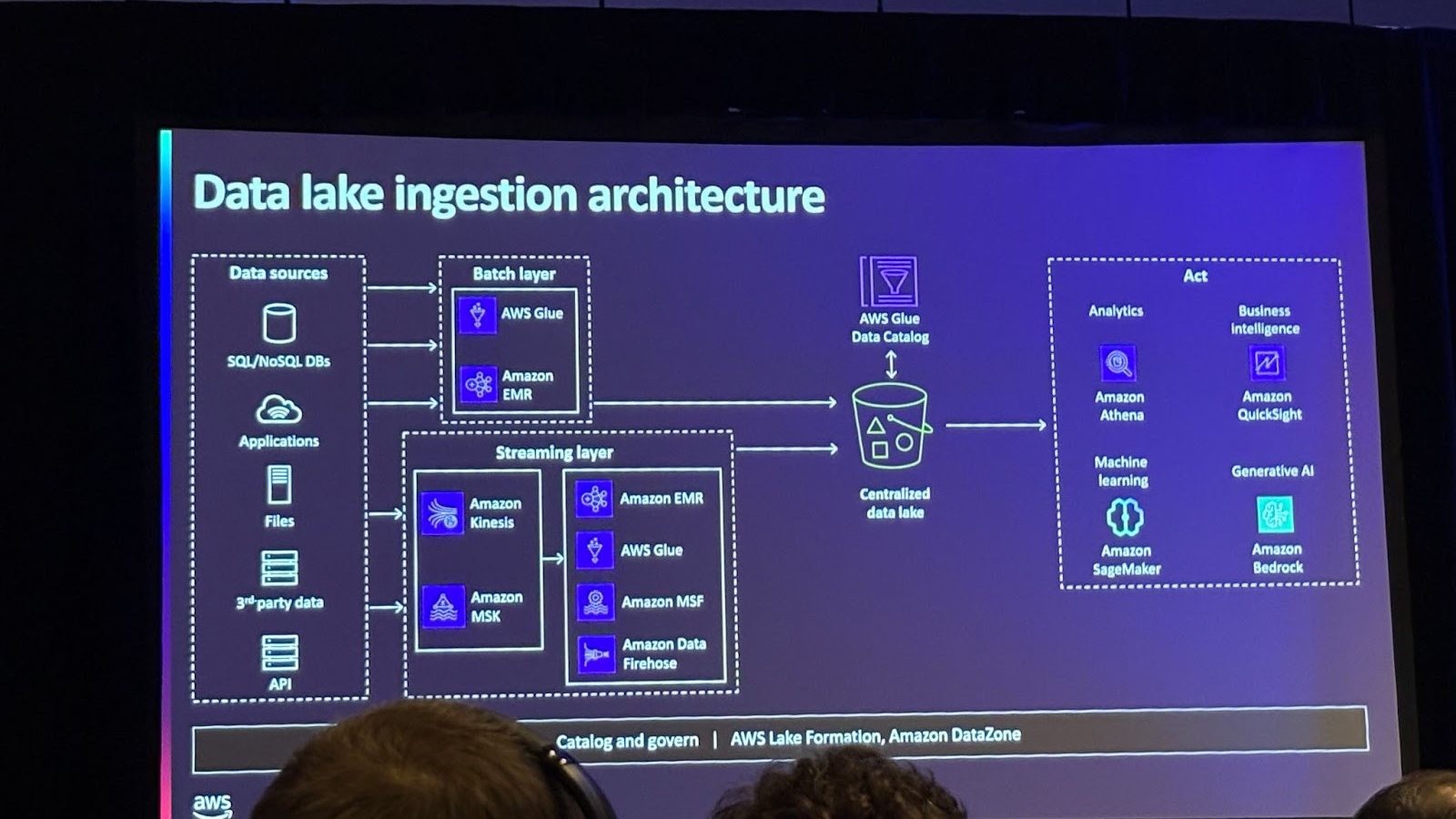
데이터 레이크 데이터 수집 패턴에 대해 살펴보겠습니다.
데이터 수집 패턴으로는 정기적인 간격으로 데이터를 수집하는 배치 수집, 실시간으로 데이터를 데이터 레이크에 저장하는 스트리밍 수집이 있습니다.
관련 서비스로는 AWS Glue가 있는데 배치 및 실시간 스트리밍 모두를 지원하며,70개 이상의 기본 커넥터와 커스텀 커넥터를 지원하고 데이터 수집에서 중요한 역할을 합니다.
또한 실시간 데이터 수집을 위한 강력한 서비스로 Amazon Kinesis 와 MSK가 있는데 Kinesis는 초당 수 GB의 데이터를 처리하며, MSK는 Apache Kafka의 관리형 서비스로 제공됩니다.
Sagemaker LakeHouse
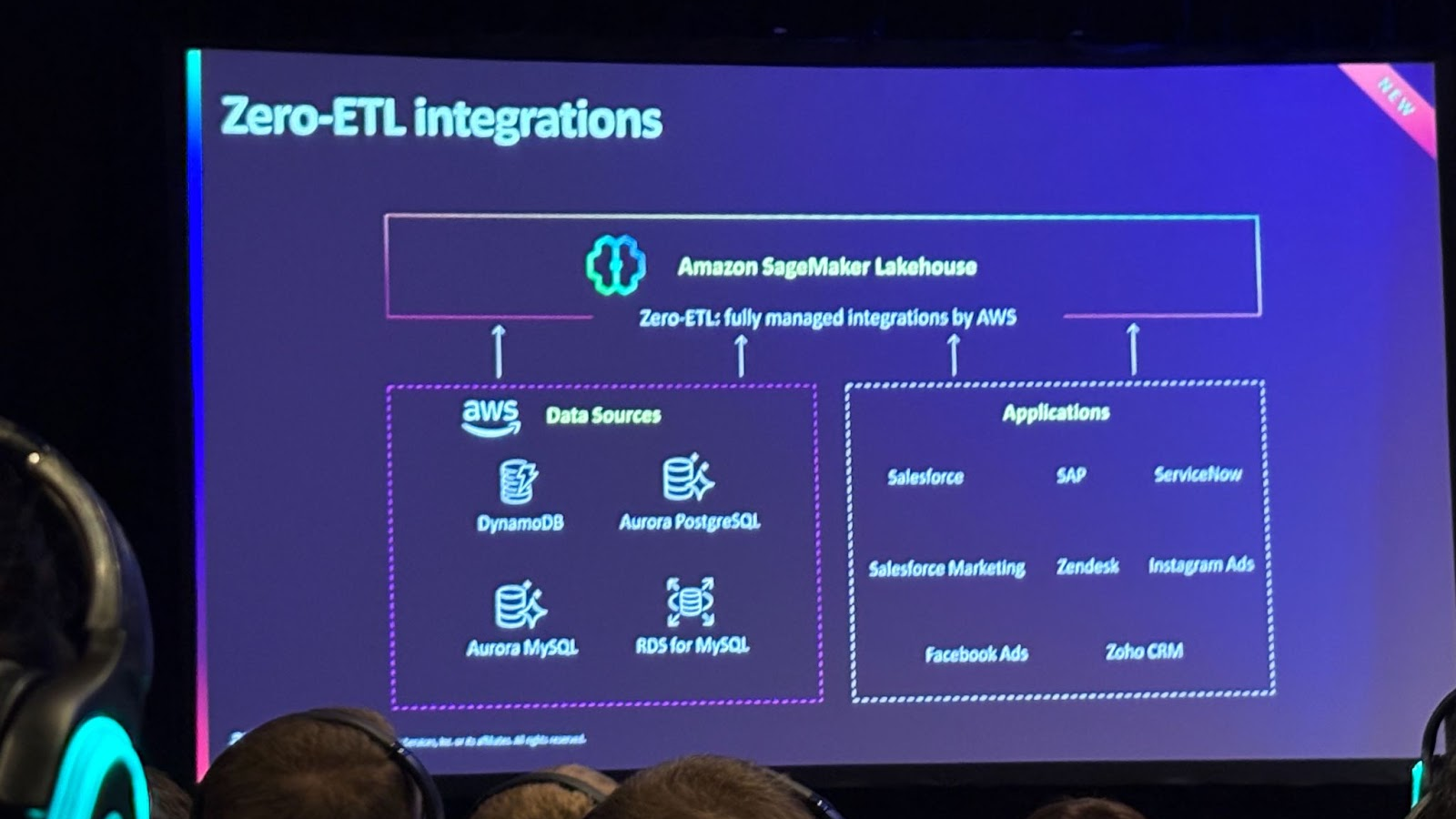
하지만 비즈니스 관점에서는 다양한 데이터 소스가 통합된 단일 접근 지점을 제공하는 것이 중요합니다.
이를 위해 Lake House 접근 방식을 도입했고 최종 사용자 입장에서는 데이터가 데이터 웨어하우스에서 오든 데이터 레이크에서 오든 신경 쓰지 않아도 됩니다.
그럼 SageMaker Lake House로 데이터를 어떻게 수집할 수 있는지 살펴보겠습니다.여기서도 Zero ETL 통합으로 DynamoDB, PostgreSQL, MySQL, Aurora, RDS와 같은 데이터 소스뿐만 아니라 Salesforce, SAP, ServiceNow와 같은 애플리케이션에서도 데이터를 수집할 수 있습니다.

AWS Glue와 EMR은 오픈 테이블 포맷의 데이터를 효율적으로 수집하고 처리할 수 있는 기능을 제공합니다.
오픈 테이블 포맷의 인기 이유는 S3에서 ACID 트랜잭션을 지원하고 뛰어난 유연성과 데이터 처리 효율성 제공하기 때문인데요. AWS는 Apache Hudi, Apache Iceberg, Delta Lake를 현대적인 데이터 레이크 포맷으로 지원합니다.
Opensearch 데이터 수집
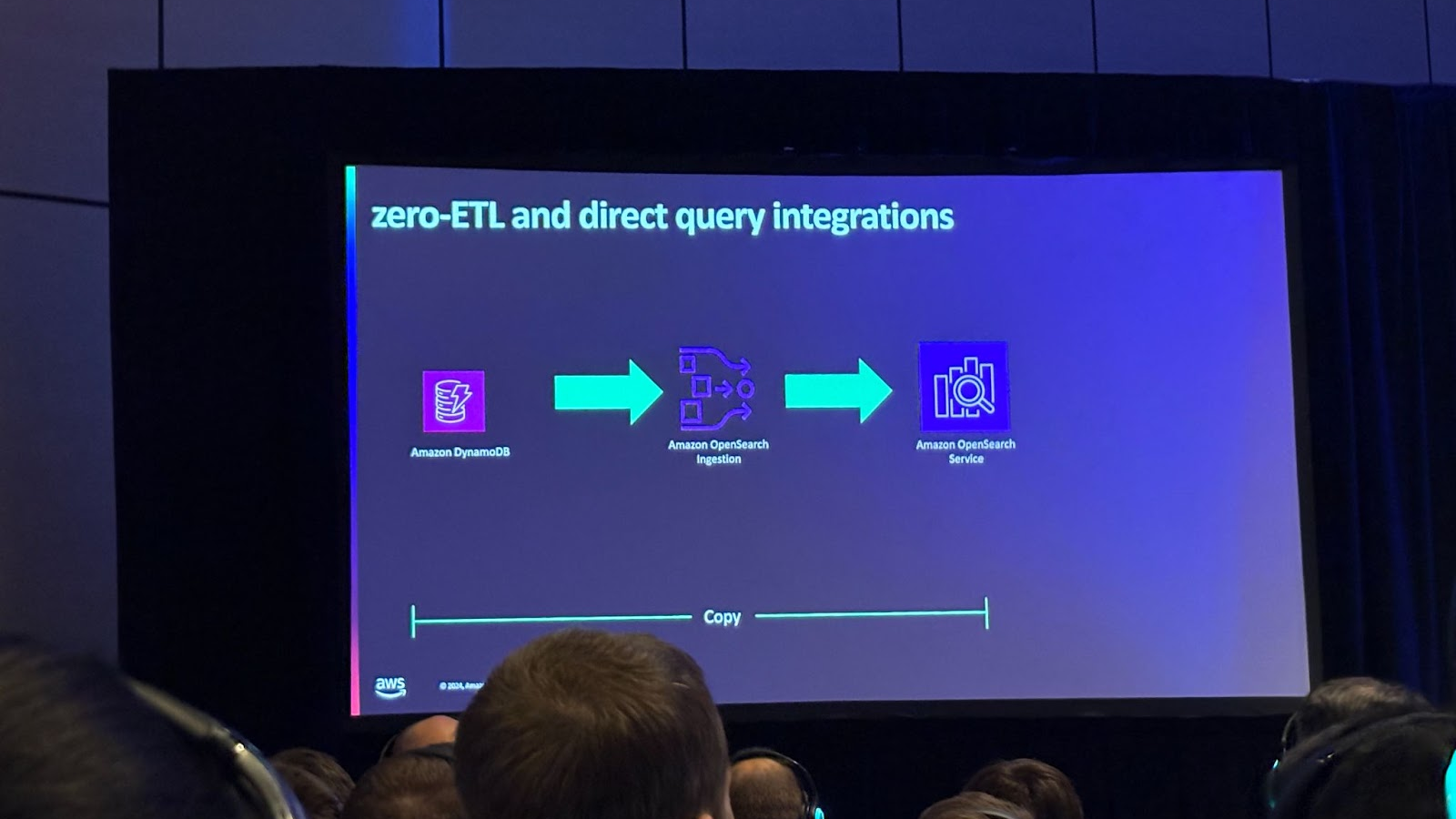
분석, 검색엔진 데이터 수집에 대해 살펴보겠습니다.Amazon OpenSearch Service가 바로 이런 분석과 검색에 사용되는 엔진인데요, DynamoDB와의 Zero ETL 통합을 통해 코드 작성 없이 DynamoDB 데이터를 거의 실시간으로 OpenSearch에서 볼 수 있고 DynamoDB와 OpenSearch 간 데이터를 동기화하며 데이터 일관성이 보장됩니다.
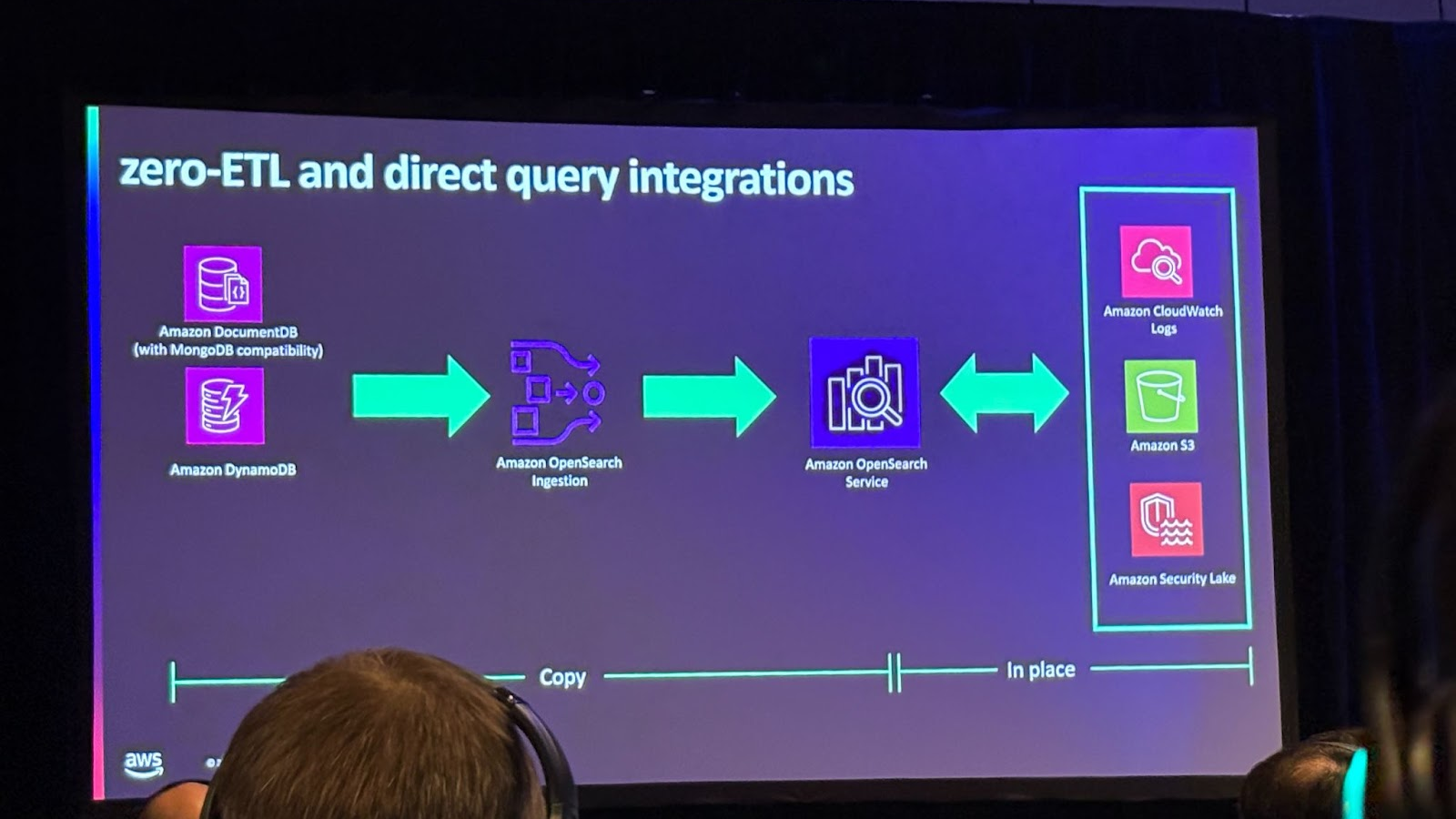
DynamoDB와 DocumentDB의 경우 데이터를 OpenSearch로 복사하지만 S3에 저장하는 용도의 대량의 데이터를 OpenSearch로 가져오는 것은 경제적으로 비효율적입니다.
OpenSearch에서 데이터를 이동하지 않고 직접 S3 데이터를 쿼리할 수 있는 direct query integration 기능을 도입했습니다. 또한 이번 re:Invent 행사 전에 CloudWatch Logs와 Security Lake에 대한 직접 쿼리 기능도 발표했습니다. 대량의 데이터를 이동하지 않고 바로 쿼리와 분석을 수행함으로써 경제적이고 데이터 측면에서도 높은 가치를 창출할 수 있습니다.
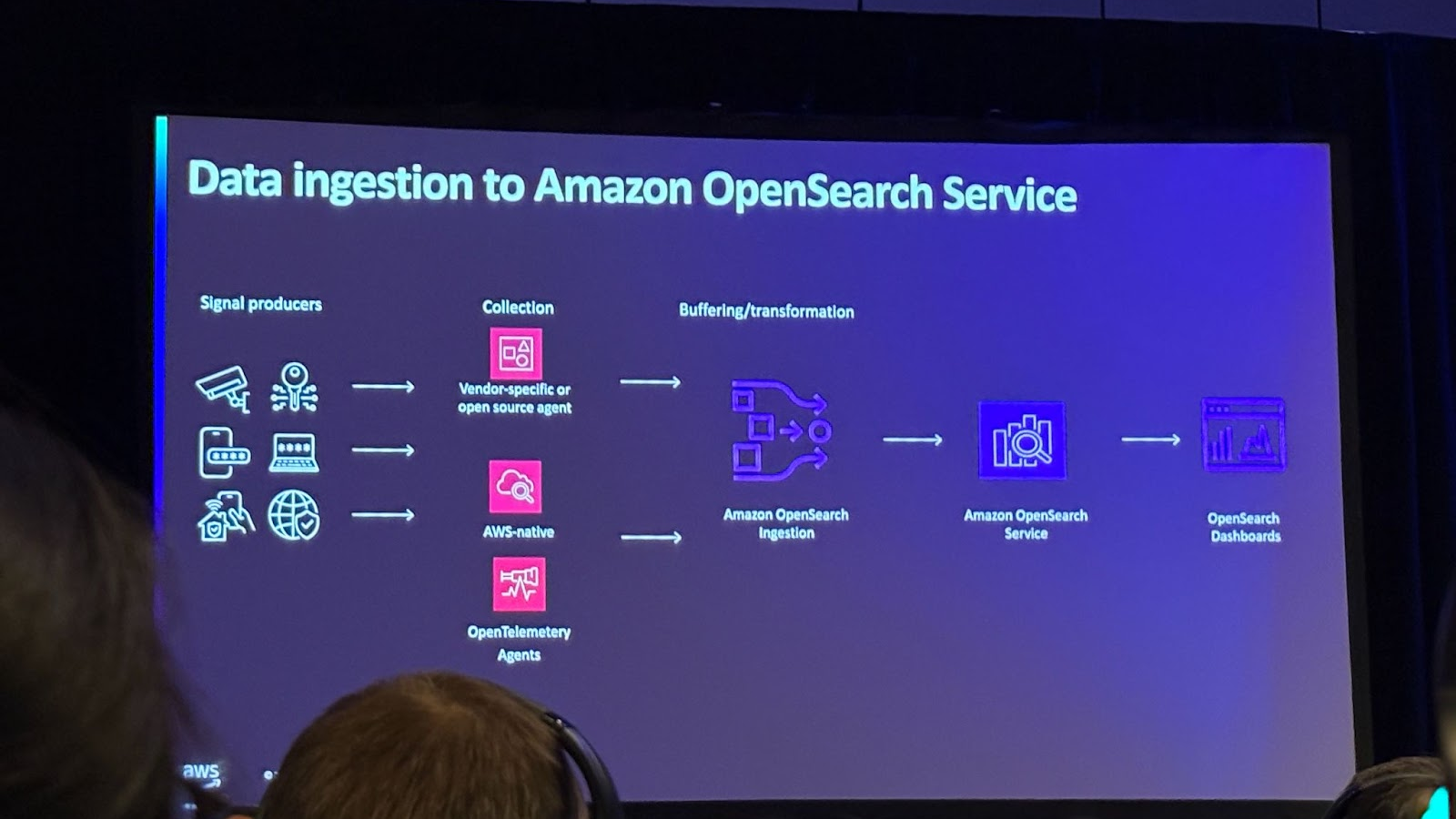
Zero ETL 통합을 지원할 뿐만 아니라, 다양한 소스를 지원합니다. 예를 들어, S3, HTTP, OpenTelemetric 소스 및 메트릭을 포함한 다양한 데이터 소스를 지원하며 MSK와 Kinesis 데이터 스트림과 같은 스트리밍 서비스도 지원합니다.
데이터수집 핵심전략

Glue 를 사용하여 효과적인 데이터 수집을 하기 위한 전략에 대해 살펴보겠습니다.
Glue는 G1, G2 등 다양한 작업자 유형과 버전을 제공하며, 각각 vCPU와 메모리가 다릅니다. 따라서 작업의 성능 요구사항에 맞는 인스턴스를 선택하고 자동 스케일링을 활성화하여 워크로드에 맞춰 인스턴스 확장 및 축소하도록 하면 최적의 성능을 얻을 수 있습니다.
또한 Flex 유형이란 여유 용량을 활용하는 옵션을 사용해서 시간에 민감하지 않은 작업을 배치 처리하거나 데이터를 채우는 등의 작업에서 더 낮은 비용으로 작업을 처리할 수 있습니다. 그리고 항상 glue의 최신 버전을 사용하면 오픈 소스 Spark보다 더 나은 성능을 체감할 수 있습니다.
모니터링 측면으로는 작업 지표와 Spark UI로 실시간 모니터링을 제공하는데 Generative AI Spark 디버깅 기능을 통해 근본 원인 분석과 추천 사항에 대한 정보를 얻을 수 있습니다.

다음으로는 Opensearch 에 대한 전략입니다.
Opensearch 를 여러 가용 영역(AZ)에 배포하여 고가용성을 확보해야 하고, 항상 dead letter queue를 설정하여 오류 발생 시 데이터를 큐로 보내 디버깅 가능하게 해야합니다.데이터 매핑 측면으로는 OpenSearch가 자동으로 데이터 유형 매핑을 지원하지만 직접 매핑하여 검색 성능을 최적화할 수도 있습니다. 또한 Zero ETL 통합을 통해 효율적인 데이터 엔진을 확장성 있게 구축할 수 있습니다.
결론
이번 세션에서는 Zero ETL 통합을 통해 데이터 파이프라인을 간소화하고, 실시간 데이터 스트리밍을 효율적으로 처리할 수 있다는 게 주된 내용 이었는데요. 이를 통해 비즈니스에 필요한 데이터를 신속하게 수집할 수 있고 비용 절감 및 시스템이 높은 확장성을 가지는 게 가능해진다는 점이 매우 유용하게 느껴졌습니다.
이러한 기술들을 적용하여 사용자들이 자동화된 데이터 파이프라인을 더 쉽게 구축하고 각 서비스의 데이터 수집 전략을 살려서 더 빠르고 정확한 데이터 분석 시스템을 구축할 수 있을 거라 생각됩니다. 결과적으로 데이터 엔지니어의 수고를 덜고 비즈니스 요구에 더 빠르게 대응할 수 있게 될 것 같습니다.
