
[reinvent 2024] Amazon S3의 새로운 기능들
Summary
Amazon S3는 거의 모든 사용 사례에서 데이터를 저장, 관리, 분석 및 보호하는 데 도움이 되는 새로운 혁신을 지속적으로 제공합니다. 탁월한 액세스 제어 기능으로 데이터를 보호하는 것부터 초당 최대 테라바이트의 총 처리량으로 확장하는 것까지 Amazon S3는 확장성, 내구성 및 가용성, 보안 및 데이터 보호, 가격 대비 성능의 한계를 계속 넓혀가고 있습니다. 이 세션에 참여하여 최신 Amazon S3 새로운 기능에 대해 알아보고 이러한 기능이 데이터를 보호, 관리 및 최적화하는 데 어떻게 도움이 되는지에 대한 실질적인 인사이트를 얻으세요.
리인벤트 2024 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며
이 세션에서는 AWS에서 지난 12개월간 새롭게 출시한 30개의 기능에 대해 알아봅니다. 이 세션은 구조적 데이터와 비구조적 데이터, S3의 기반 기술인 스케일, 보안, 성능 및 내구성에 대한 업데이트 등의 다양한 내용들을 간략하게 소개합니다. 이 세션을 듣고 S3를 더욱 효과적으로 사용할 수 있는 인사이트를 얻어가셨으면 좋겠습니다.

이 세션에서는 총 30개의 새롭게 런칭된 기능을 아래와 같이 크게 4개의 카테고리로 구분지어 소개합니다.
- 정형 데이터
- 비정형 데이터
- 스토리지 핵심
- S3 클라이언트
여기서 전부 설명하기에는 양이 많기 때문에 중요한 몇 몇 기능을 간추려 소개드리겠습니다.
정형 데이터
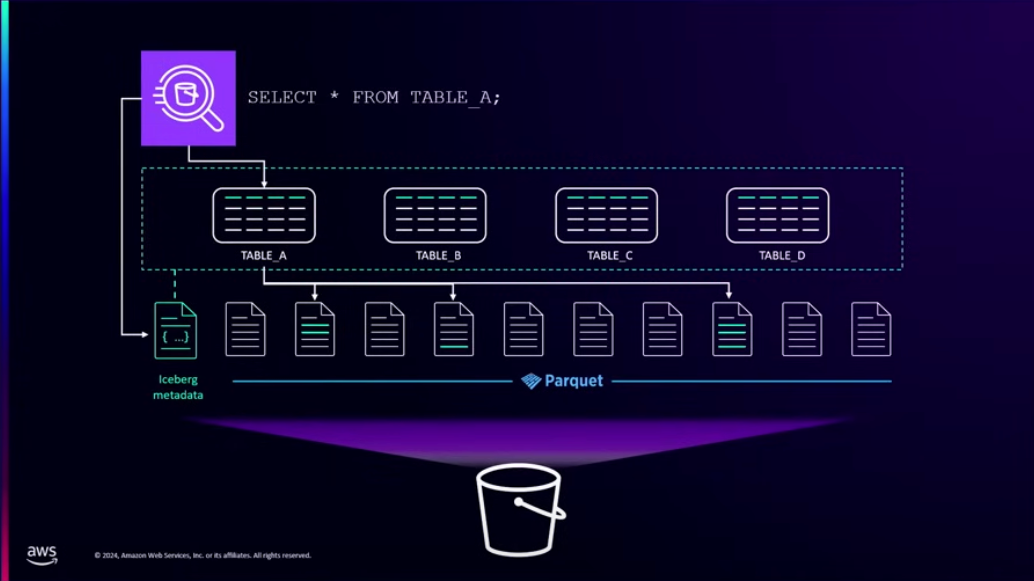
AWS는 이번에 S3 Table이라는 신기능을 런칭했습니다. S3 테이블은 Parquet 타입의 데이터를 저장 가능한 매니지드 Apache Iceberg입니다. S3 테이블을 통해, 너무 큰 데이터를 관리해야 하기 때문에 관리가 힘들고, 권한 및 권한 관리가 힘든 Apache Iceberg를 매니지드 서비스로 이용할 수 있습니다.

AWS는 내부적으로 많은 최적화 방법을 수행하여 10배의 TPS와 3배의 쿼리 퍼포먼스 향상을 이끌어냈습니다. 이 수치들을 어떻게 구현했는지 궁금하시면 세션 영상을 보시기 바랍니다.

S3 테이블은 각각의 테이블에 대한 권한 설정도 가능합니다. S3 테이블은 각각이 arn이 할당되고, 이를 통해 버킷 뿐만 아니라 테이블 단위의 권한 설정도 가능하게 합니다.

S3와 유사한 보존 정책도 설정이 가능합니다.
비정형 데이터
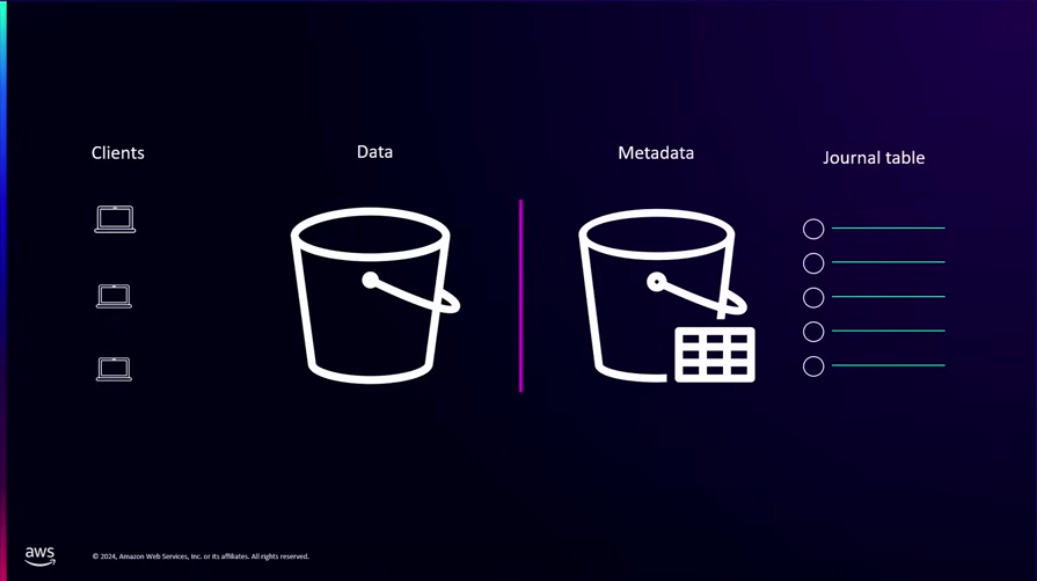
S3에는 이미지, 비디오, 로그 등등 수많은 수많은 비정형 데이터가 저장되어 있고, 끊임없이 쌓이고 있습니다. 오브젝트가 많아짐에 따라 사용자들은 실제로 필요한 오브젝트를 찾는 것에 어려움을 느끼고 있습니다. 이에 따라 일부 고객들은 자신들만의 자체적인 메타데이터 스토리지를 구축하는 경우도 있습니다. AWS에서는 이러한 문제를 해결하기 위해 Amazon S3 Metadata를 런칭했습니다.

S3 Metadata는 저장되는 오브젝트에 이미 있는 속성을 자동적으로 메타데이터에 기록하고, 간단한 SQL 쿼리를 통해 액세스할 수 있도록 합니다. S3 Metadata에서 자동으로 기록하는 필드 목록은 이미지를 참고해주시기 바랍니다. 또한 유저는 커스텀 메타데이터도 추가할 수 있습니다.

AWS에서 생각하는 간단한 사용 사례들은 아래와 같습니다.
- SQL 쿼리를 이용하여 원하는 오브젝트를 탐색
- 데이터 자체를 트래킹(예: 누가 어떤 데이터를 삭제했는지 추적)
- 스토리지를 무슨 목적으로 얼마나 사용하고 있는지에 대한 통계 데이터 획득
또한 AWS에서는 현재 Bedrock으로 생성되는 모든 비디오에 커스텀 태그로 content-source=AmazonBedrock을 추가 한다고 합니다.
스토리지 핵심

현재는 S3 버킷 생성 개수의 한계때문에 여러 어카운트에 걸쳐 버킷을 생성하여 사용하는 경우가 있다고 합니다. AWS에서는 버킷 생성 개수의 한계가 어플리케이션의 복잡성을 증가시키는 것을 원치 않기 때문에 버킷 개수의 한도를 백만개로 상향했다고 합니다. 이제 기본 버킷 개수 리밋은 10000개이고, 요청을 통해 백만개까지 증가시킬 수 있다고 합니다. 또한 버킷이 List API에 필터를 추가할 수 있도록 업데이트 했다고 합니다.
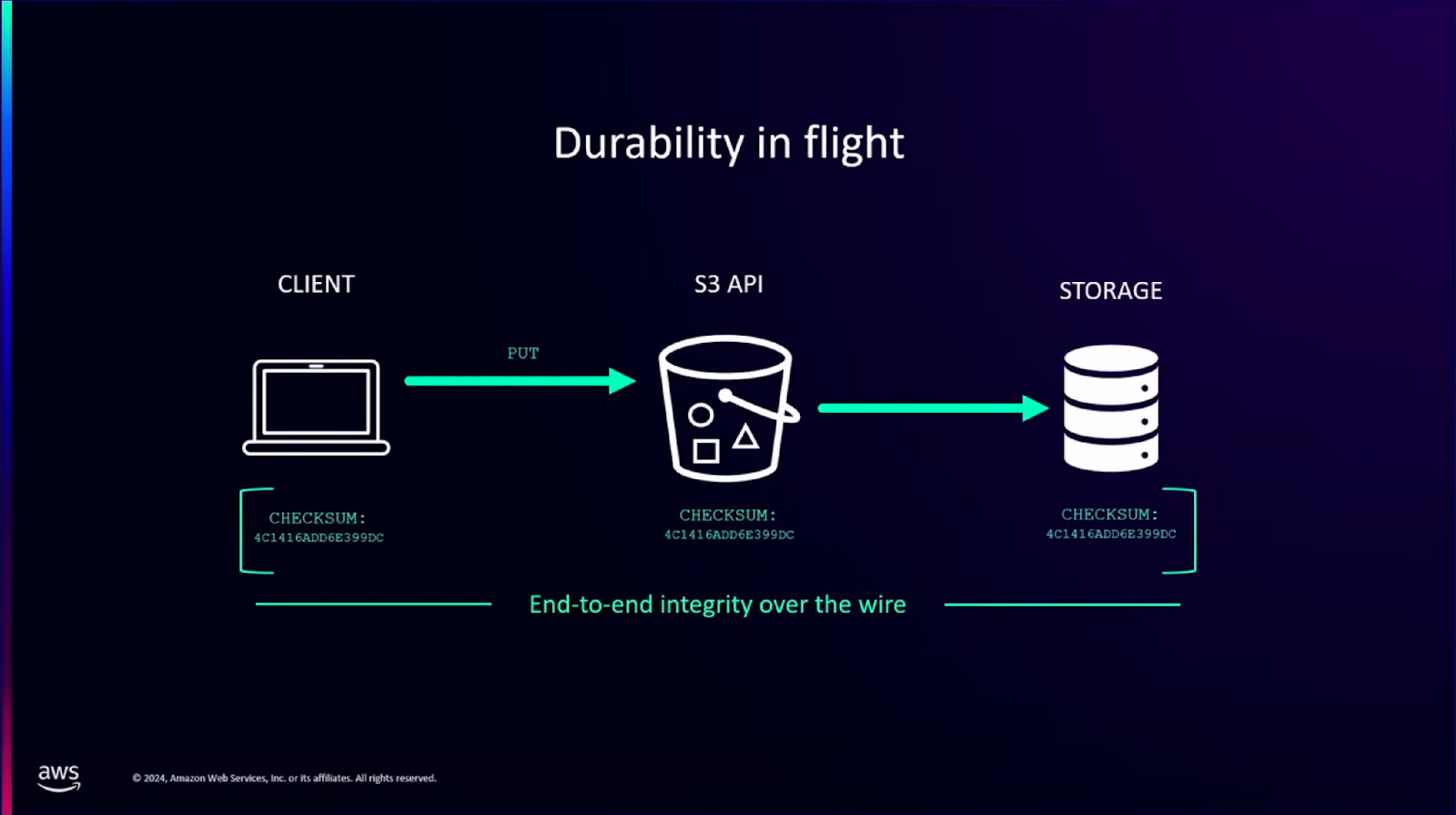
AWS에서 S3는 일레븐나인의 SLA를 가집니다. 이를 위해 S3 API는 데이터를 전달받은 시점부터 AWS 내에서 저장되거나 이동될 때 매번 CHECKSUM을 확인한다고 합니다. 하지만 이는 AWS로 데이터가 이동된 시점부터 유효한 것이기 때문에 Client에서 S3 API로 데이터가 이동될 때에 데이터가 변조되지 않음을 보장할 수 없다고 합니다. AWS에서는 이를 해결하기 위해 클라이언트가 데이터를 전달하는 시점부터도 CHECKSUM을 확인하게끔 업데이트 했다고 합니다. 이를 통해 데이터의 내구성이 더욱 향상되었다고 합니다.


이전에는 한 클라이언트가 데이터를 업로드 하는 도중에 다른 클라이언트가 같은 키로 데이터 덮어쓰기(PutObject)를 하면, 둘 다 200을 받지만 실제로는 덮어쓰기는 적용되지 않는다고 합니다. 이제는 이렇게 여러 클라이언트가 동시에 한 오브젝트에 대한 작업을 할 때, 충돌에 대한 조건을 설정할 수 있는 기능을 추가했다고 합니다.

이전에는 S3에서 403에러가 발생했을 때 원인을 파악하기가 매우 힘들었습니다. 이제는 조금 더 명시적인 에러 메시지를 전달하도록 업데이트하여 트러블슈팅을 용이하게 했다고 합니다.
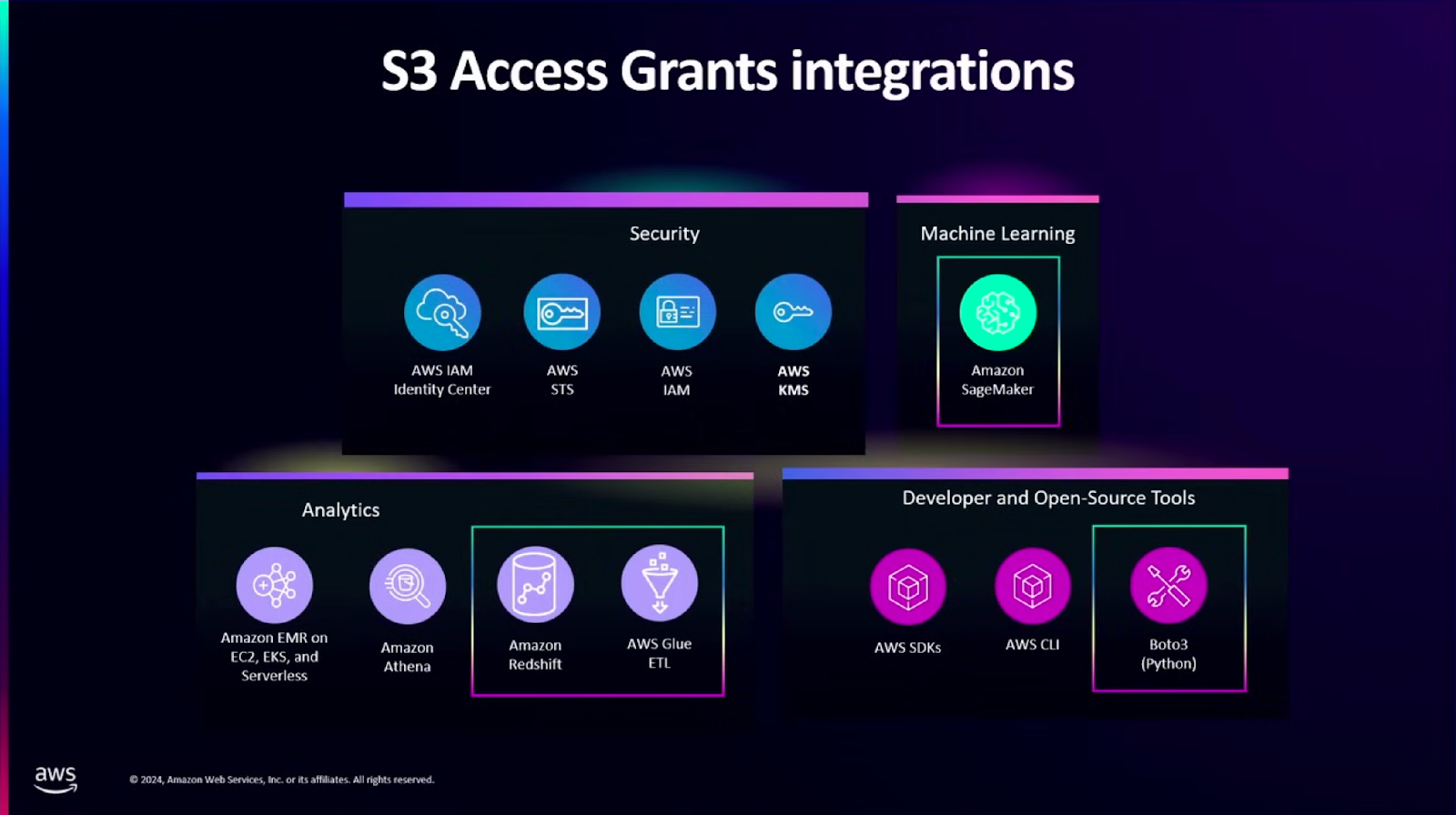
이제는 Okta와 같은 외부 IdP에 대해서도 권한 설정이 가능하다고 합니다. 또한 이렇게 인증받은 사용자가 어떤 데이터 셋에 액세스가 가능한지 확인 가능한 ListCallerAccessGrant API도 추가했다고 합니다.
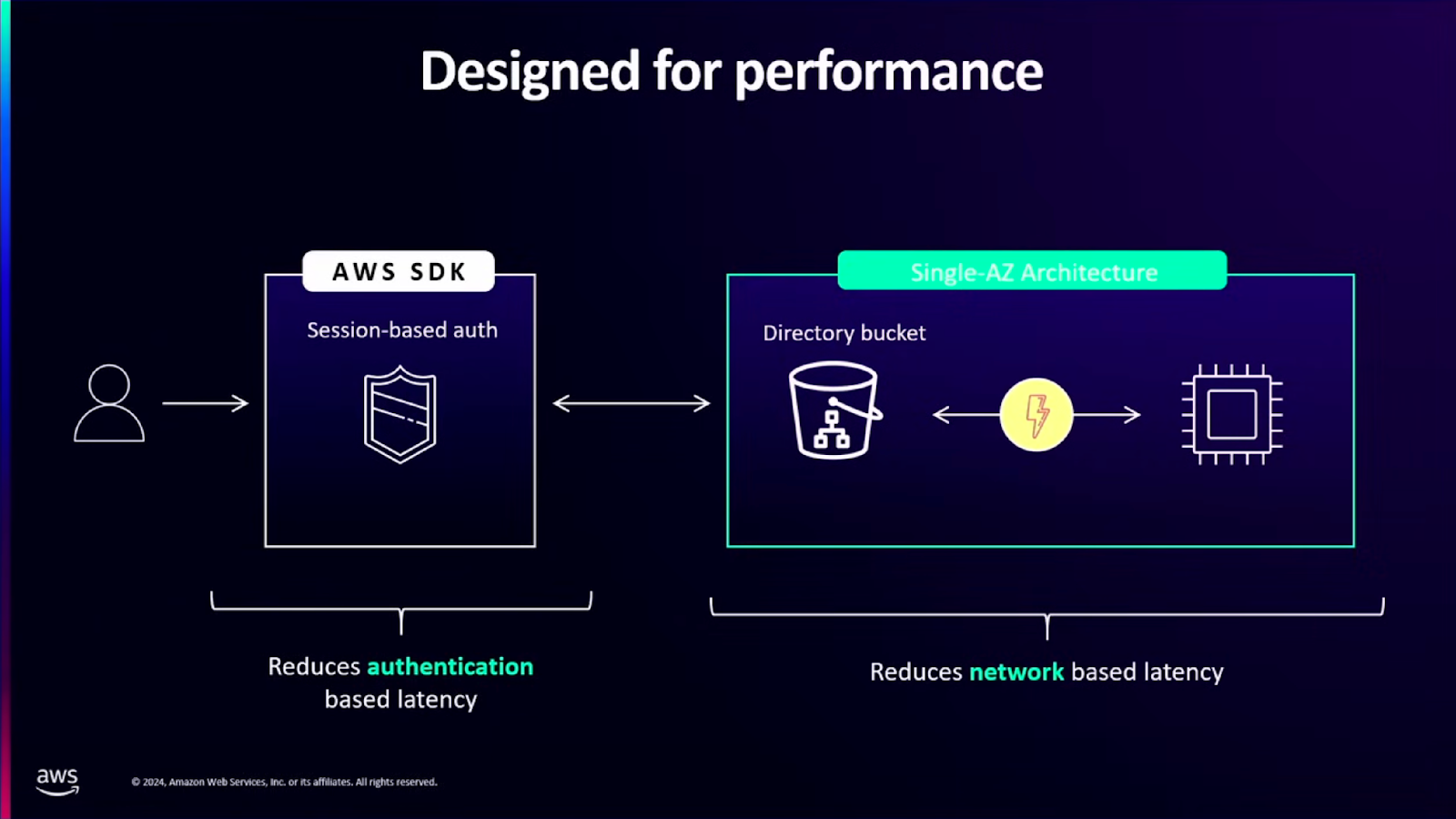
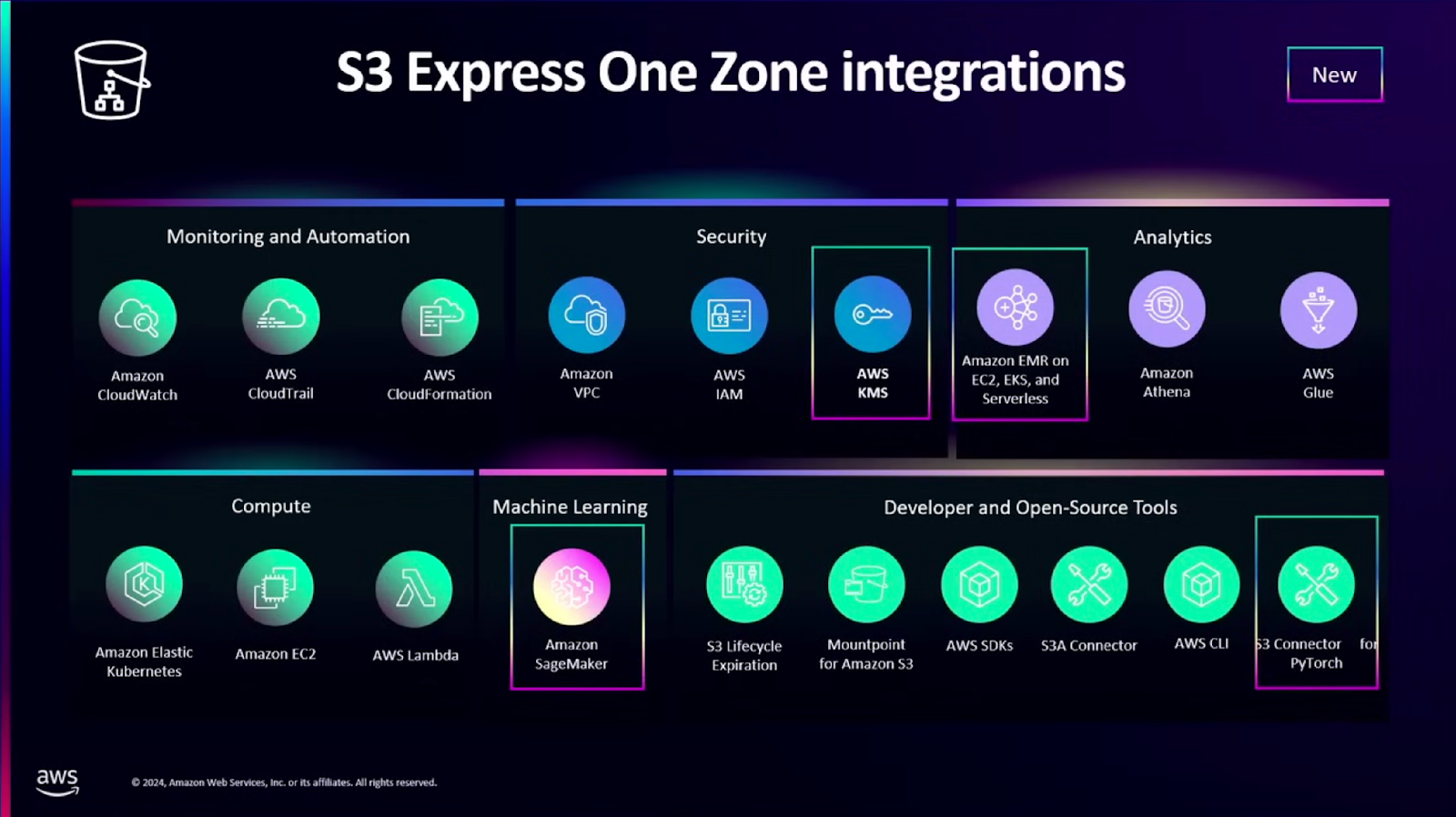
AWS에서는 S3 Express One Zone 스토리지 클래스를 2023년도 re:Invent때 발표했습니다. 인증 방식을 기존의 토큰 방식에서 세션 방식으로 변경하고, 한 AZ에만 사용하도록 제한함으로써, 읽기 작업 속도를 10배 빠르게 하고, 요청 비용을 50% 감소시켰다고 합니다. 이 스토리지 클래스는 대량의 데이터를 사용해야 하는 워크로드(예: AI, ML)등에 적합하다고 합니다. 이번 re:Invent 2024에서는 SageMake 와 같은 AWS 매니지드 서비스와 S3 Express One Zone의 연동을 신규로 발표합니다.
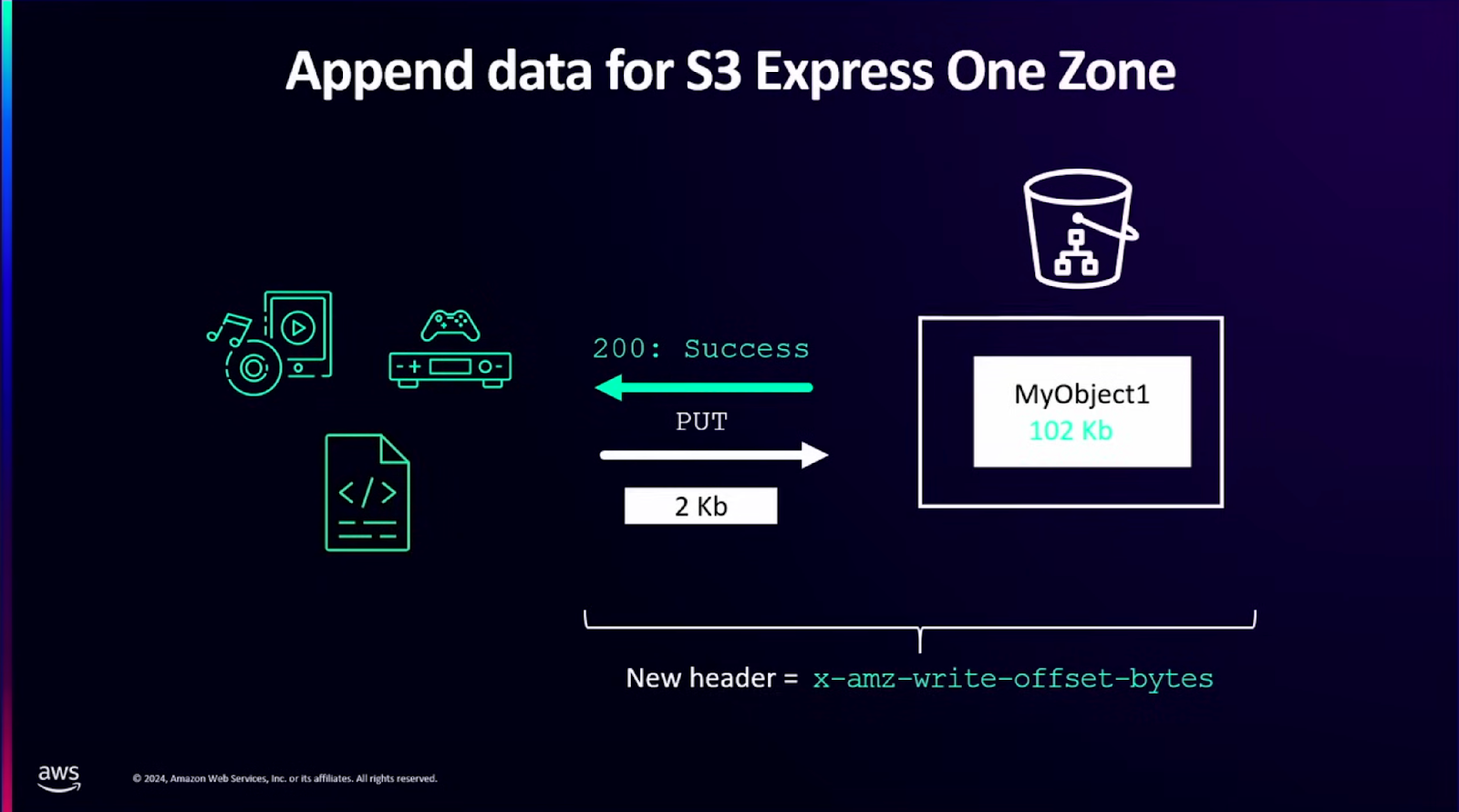
S3는 오브젝트 스토리지로 오브젝트 단위로밖에 수정이 안 됐었습니다. AWS에서는 S3 Express One Zone에 한하여 기존에 저장되어 있는 오브젝트에 데이터를 append하는 기능을 추가했다고 합니다.
S3 클라이언트

S3를 이용하는 방법은 다양합니다. AWS는 여기에 더해 새로운 방법들을 런칭했습니다.
여기서 모두 설명하기엔 내용이 많기 때문에 목록만 전달드리겠습니다. 궁금하시다면 영상을 보고 확인해보시기 바랍니다.
- S3 Mountpoint Distributed caching
- S3 Connector for PyTorch support for PyTorch Lightning checkpoints
- S3 Connector for PyTorch support for distributed checkpoints
- Storage Browser for Amazon S3
- AWS Transfer Family for web apps
- Amazon S3 static websites with AWS Amplify
결론
S3는 AWS의 가장 기반이 되는 서비스 중 하나로, 관리하기 힘든 대용량 데이터를 간편하게 관리할 수 있는 좋은 서비스입니다. 단순히 데이터를 저장하는 것을 넘어 다양한 사용 사례에 맞춘 다양한 기능들을 계속해서 출시하는 모습이 인상깊었습니다. 이 세션을 보는 분들이 새롭게 런칭된 S3의 여러 기능들에 대해 알아보고, 자사의 데이터를 더욱 가치있게 사용하는데 도움이 되었으면 좋겠습니다.
