
[reinvent 2024] AWS로 최적화된 클라우드 워크로드 구축
Summary
다리를 건설하는 것처럼 클라우드 워크로드를 구축하려면 원하는 품질을 충족하고 의도한 비즈니스 결과를 효과적으로 지원하기 위해 설계와 재료를 신중하게 고려해야 합니다. 이 세션에 참여하여 AWS Well-Architected Framework를 사용하여 클라우드 워크로드가 최적의 비즈니스 결과를 제공하는 데 필요한 품질 집합을 결정하는 방법을 알아보세요. AWS Health, AWS Trusted Advisor 등 다양한 서비스를 사용합니다. 호주의 다국적 은행인 커먼웰스 은행은 클라우드 아키텍처를 견고하고 안전하며 비용 효율적으로 유지하기 위해 AWS Well-Architected를 사용하여 아키텍처 문제를 해결하는 방법에 대한 인사이트를 얻을 수 있습니다.
리인벤트 2024 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며

AWS Well-Architected Framework 이해하기
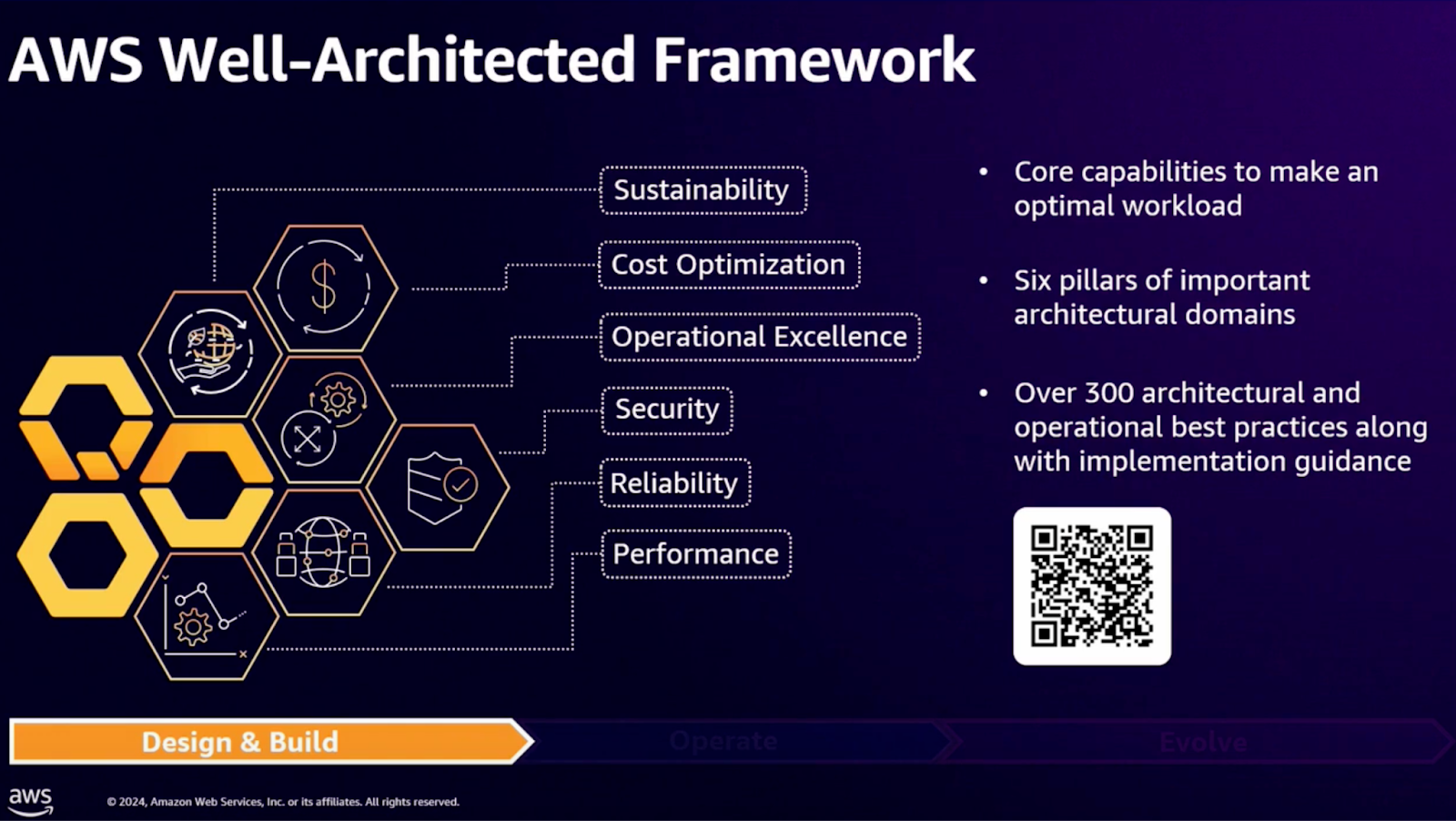
AWS Well-Architected Framework는 클라우드 워크로드를 효과적이고 안정적으로 설계하기 위한 AWS의 핵심 지침입니다. 이 프레임워크는 다음과 같은 6가지 주요 내용으로 구성되어 있습니다:
- 보안(Security): 워크로드를 잠재적 취약점과 무단 접근으로부터 보호하기 위한 조치.
- 신뢰성(Reliability): 시스템 장애 시 빠르게 복구할 수 있는 능력을 보장.
- 성능 효율성(Performance): 요구 사항 변화에 대응할 수 있는 최적의 자원 사용.
- 운영 우수성(Operational Excellence): 효율적인 운영과 관리 방식을 통해 지속적인 개선.
- 비용 최적화(Cost Optimization): 자원과 비용을 효율적으로 관리.
- 지속 가능성(Sustainability): 환경적으로 책임 있는 설계를 통해 탄소 발자국을 최소화.
이 프레임워크는 AWS가 다양한 고객과 협력하며 축적한 경험을 바탕으로 개발되었으며, 300개 이상의 아키텍처 및 운영 모범 사례를 포함하고 있습니다. 이를 통해 워크로드의 안정성과 효율성을 동시에 확보할 수 있으며, 특히 워크로드를 처음 설계하고 구축하는 단계에서 매우 유용하게 적용할 수 있습니다. 이 단계에서는 워크로드의 기초를 세우기 위해 아키텍처의 안정성과 확장성을 확보하는 데 초점을 맞춰, 워크로드가 보안, 비용, 성능 등 여러 측면에서 AWS 모범 사례에 부합하도록 설계해야 장기적으로 지속 가능한 아키텍처를 운영할 수 있습니다.

또한 추가적으로 클라우드 환경에서 인프라를 안전하게 보호하기 위해 다층 방어 전략과 신뢰 경계(Trust Boundaries)를 설정하여 시스템 강화(System Hardening), 접근 제어(Access Control), 정책 집행(Point Enforcement)을 통해 무단 접근과 취약점으로부터 워크로드를 보호할 수 있습니다.
효율적인 클라우드 아키텍처 설계
효율적인 클라우드 아키텍처 설계는 성능, 비용, 보안, 운영 효율성 등 여러 측면에서 최적화된 상태를 유지하면서도 변화하는 비즈니스 요구 사항에 유연하게 대응할 수 있는 구조를 만드는 것을 목표로 합니다. AWS Well-Architected Framework는 이러한 설계를 체계적으로 지원하며, 효율적인 설계의 핵심 원칙과 모범 사례를 제공합니다.

클라우드 아키텍처 설계는 비즈니스 요구를 충족시키는 동시에 성능, 비용 효율성, 보안, 지속 가능성을 고려해야 합니다.
첫 번째로 중요한 핵심 역량은 보안(Security)입니다. 클라우드 환경에서 데이터와 시스템, 자산을 보호하기 위해 암호화, 접근 제어, 네트워크 보안을 철저히 구현해야 합니다. 예를 들어, AWS Key Management Service(KMS)를 사용하면 암호화 키를 안전하게 관리할 수 있고, AWS Identity and Access Management(IAM)를 통해 최소 권한 원칙을 적용할 수 있습니다. 또한, AWS WAF와 AWS Shield 같은 도구를 활용해 외부의 악의적인 공격으로부터 워크로드를 보호할 수 있습니다.
다음으로, 신뢰성(Reliability)은 장애 발생 시 워크로드가 빠르게 복구되고 안정성을 유지할 수 있는 능력을 의미합니다. 예를 들어, Amazon RDS의 멀티 AZ(Multi-AZ) 배포를 통해 데이터베이스를 여러 가용 영역에 복제하면 단일 장애점(Single Point of Failure)을 제거할 수 있습니다. 또한, AWS Backup을 사용해 자동으로 데이터를 백업하고, 복구 시간을 최소화하는 재난 복구(Disaster Recovery) 전략을 수립하는 것도 중요합니다. 이를 보완하기 위해 Amazon CloudWatch를 활용해 실시간으로 워크로드 상태를 모니터링할 수도 있습니다.
비용 최적화(Cost Optimization)는 클라우드 아키텍처 설계에서 빼놓을 수 없는 요소입니다. AWS Compute Optimizer를 활용하면 애플리케이션 요구 사항에 맞는 최적의 리소스를 추천받을 수 있습니다. 또한, Spot Instances와 AWS Savings Plans를 사용하면 컴퓨팅 비용을 효과적으로 절감할 수 있으며, 데이터 전송 비용을 줄이기 위해 Amazon S3 Transfer Acceleration을 활용할 수도 있습니다. 이러한 접근법은 단기적으로는 물론 장기적으로도 비용 효율성을 극대화합니다.
운영 우수성(Operation Excellence)도 중요한 역할을 합니다. AWS Systems Manager를 통해 반복적인 운영 작업을 자동화하면 인적 오류를 줄이고, 운영 효율성을 높일 수 있습니다. 또한, Amazon CloudWatch Logs와 AWS X-Ray를 활용해 애플리케이션의 성능과 상태를 상세히 분석하고, 운영 환경에 대한 가시성을 확보할 수 있습니다. 더 나아가 CI/CD 파이프라인을 AWS CodePipeline과 통합해 신속하고 안전한 배포를 실현할 수도 있습니다.
효율적인 아키텍처는 성능 효율성(Performance Efficiency)을 통해 일관되고 효율적인 워크로드 운영을 보장합니다. Amazon Auto Scaling을 활용하면 워크로드의 수요 변화에 따라 리소스를 자동으로 확장하거나 축소할 수 있습니다. 또한, 서버리스 아키텍처(Lambda, DynamoDB)를 통해 애플리케이션 성능을 극대화하면서도 인프라 관리의 부담을 줄일 수 있습니다. AWS Trusted Advisor를 사용하면 리소스의 성능 최적화 상태를 점검하고 잠재적인 문제를 사전에 발견할 수 있습니다.
마지막으로, 지속 가능성(Sustainability)은 클라우드 환경이 환경에 미치는 영향을 줄이고 장기적으로 책임감 있게 운영되도록 하는 데 중점을 둡니다. AWS의 탄소 발자국 도구를 활용해 리소스 사용으로 인한 탄소 배출량을 측정하고 이를 줄이기 위한 방안을 모색할 수 있습니다. 에너지 소비를 줄이기 위해 사용량에 따라 리소스를 조정하는 것도 중요한 전략 중 하나입니다.
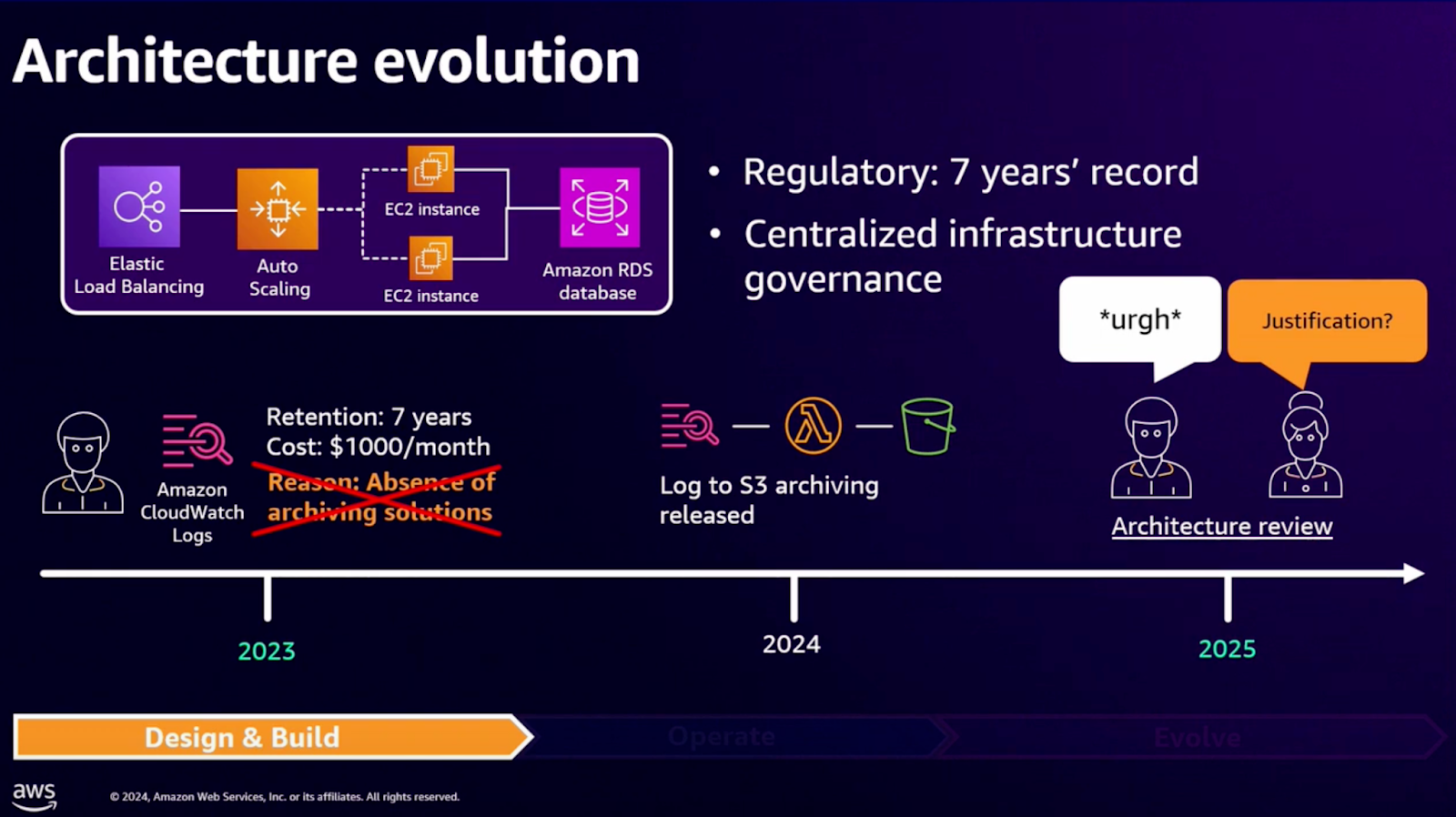
위에서 설명한 내용을 기반으로 CloudWatch를 사용한 로그 저장 사례를 통해 효율적인 아키텍처 설계가 얼마나 중요한지 살펴보도록 하겠습니다.
2023년 기준, Amazon CloudWatch Logs를 사용하여 7년 보관 규제 요건을 충족하려 했으나, 로그 보관 솔루션이 부재하여 월 $1000 이상의 비용이 발생하는 문제가 있었습니다. 이는 로그 데이터 보관에 적합하지 않은 솔루션을 사용한 결과로, 비용 효율성과 운영상의 비효율을 초래했습니다.
2024년 로그 데이터를 더 비용 효율적으로 보관하기 위해 S3로 로그 아카이빙 솔루션이 도입되었습니다. 이 과정에서 Lambda를 활용하여 CloudWatch Logs 데이터를 S3로 자동 전송하는 프로세스가 구축되어, 월간 로그 보관 비용을 대폭 절감하고, 장기 보관 규제 요건도 충족할 수 있었습니다.
이러한 사례에서 볼 수 있듯이 아키텍처 리뷰를 통해 이러한 개선 사항이 정당화되고, 중앙화된 거버넌스 체계를 통해 최적화함으로서, 워크로드 운영의 효율성과 비용 절감 효과를 동시에 달성할 수 있었습니다.
워크로드 운영 및 관리 전략
워크로드 운영 및 관리 전략에 있어서 중요한것은 현재 상태에서 멈추지 않고 지속적으로 발전을 도모하는 것입니다. 이 단계의 핵심은 프로세스의 단순화와 자동화, 새로운 기술 도입, 운영 데이터 활용, 그리고 팀 생산성 강화입니다. 이를 통해 워크로드는 변화하는 비즈니스 요구와 기술 트렌드에 유연하게 적응하며, 비용 효율성과 안정성을 유지할 수 있습니다. 지속적인 개선을 통해 클라우드 환경에서의 경쟁력을 강화해야 하는 것입니다.
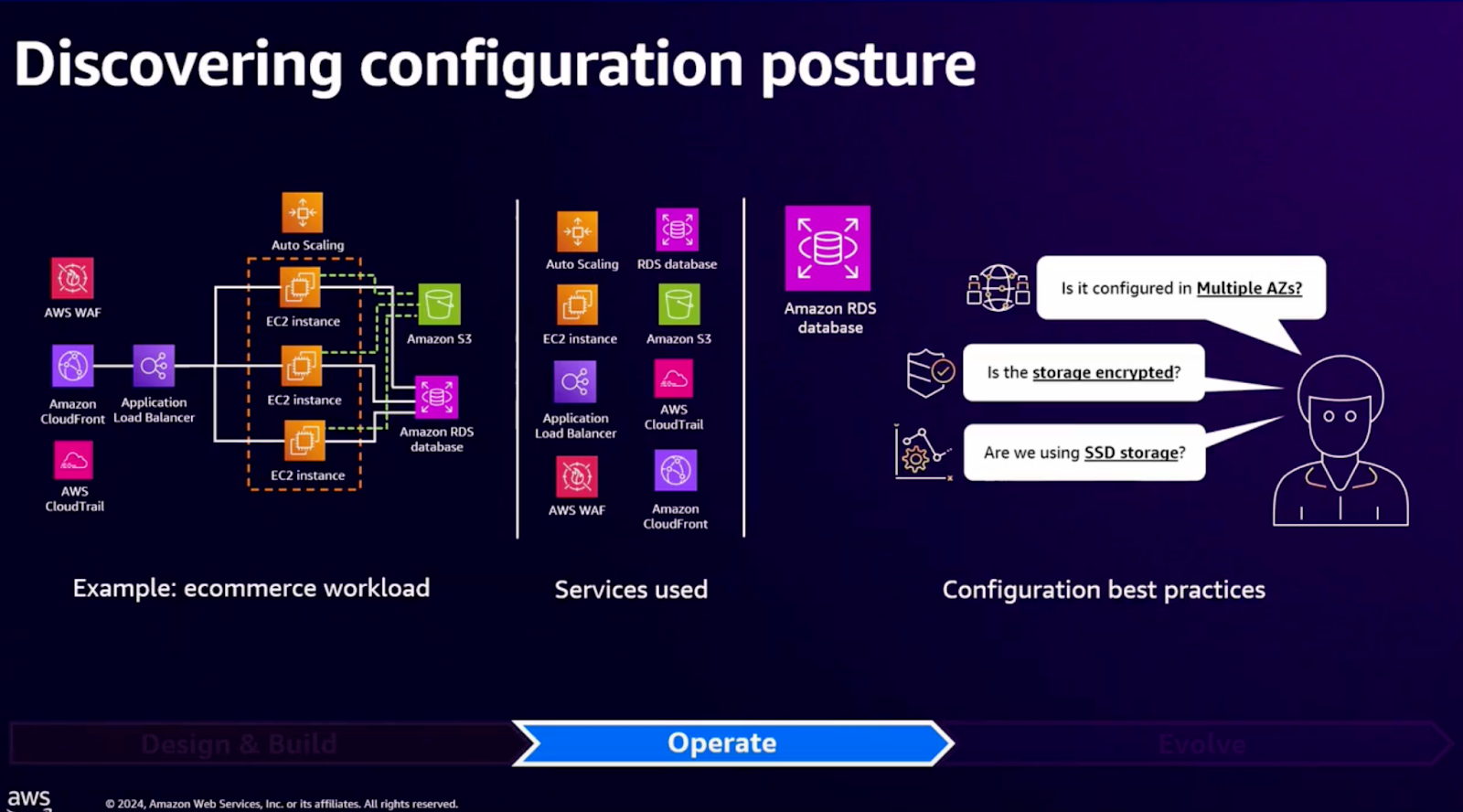
전자상거래 워크로드를 기반으로 구성된 아키텍처를 확인하고 운영 및 관리 전략을 통한 예를 살펴보겠습니다.
이미지에서 볼 수 있듯이 해당 워크로드를 사용하기 위해 다음과 같은 AWS의 서비스가 사용되고 있으며, 고가용성과 성능이 중요한 애플리케이션에서 흔히 사용되는 패턴입니다.
- Auto Scaling: 수요 변화에 따라 EC2 인스턴스를 자동으로 조정하여 워크로드 안정성을 유지.
- EC2 인스턴스: 애플리케이션 로직을 실행하는 컴퓨팅 리소스.
- Amazon RDS: 트랜잭션 데이터를 처리하는 데이터베이스 서비스.
- Amazon S3: 정적 콘텐츠를 저장하고 배포하기 위한 객체 스토리지.
- Application Load Balancer: 요청을 여러 EC2 인스턴스에 분산하여 트래픽을 효율적으로 처리.
- AWS WAF: 악의적인 요청을 필터링하여 보안을 강화.
- CloudFront: 정적 및 동적 콘텐츠의 글로벌 캐싱을 통해 응답 속도를 향상.
- AWS CloudTrail: API 호출 기록을 저장하여 보안 및 거버넌스를 강화.
우리는 워크로드가 AWS 모범 사례에 맞게 설계되고 운영되고 있는지 확인하는 과정을 거쳐야 합니다. 이를 통해 워크로드의 안정성과 성능을 유지하고, 잠재적인 문제를 사전에 예방할 수 있습니다.
- 다중 가용 영역(Multiple AZs) 구성 여부:
데이터베이스와 같은 주요 리소스는 다중 가용 영역에 걸쳐 배포되어야 장애 발생 시에도 복구가 가능하고, 고가용성을 유지할 수 있습니다. - 스토리지 암호화 여부:
데이터의 기밀성과 무결성을 유지하기 위해 스토리지가 암호화되어 있는지 확인해야 합니다. 예를 들어, Amazon RDS 및 S3는 기본적으로 암호화를 지원하며, AWS KMS를 통해 키를 관리할 수 있습니다. - SSD 스토리지 사용 여부:
성능에 민감한 워크로드의 경우 SSD 스토리지를 사용하는 것이 중요합니다. 이는 더 빠른 읽기 및 쓰기 속도를 제공하여 애플리케이션의 성능을 향상시킵니다.

이러한 일이 완료되고 최종적인 단계에서는 기존 워크로드를 지속적으로 개선하고, 프로세스를 간소화하며, 변화하는 요구사항에 맞춰 워크로드를 최적화하는 것을 목표로 나아가야 합니다.

이를 위해 가장 먼저 해야 하는 일은 운영 프로세스를 간소화하는 것입니다. 예를 들어, AWS Lambda와 EventBridge를 사용하여 정기적인 관리 작업을 자동화하면 운영 시간을 절약하고 인적 오류를 줄일 수 있습니다. 또한, AWS CodePipeline 및 CodeDeploy와 같은 CI/CD 도구를 활용하면 코드 배포와 업데이트 과정을 자동화하여 팀의 작업 속도와 안정성을 동시에 향상시킬 수 있습니다.
또한 워크로드가 변화하는 환경에 적응하기 위해서는 구성 상태를 정기적으로 점검하고 필요한 변경 사항을 적용해야 합니다. AWS Trusted Advisor는 워크로드의 현재 상태를 모범 사례와 비교하여 개선이 필요한 부분을 확인하고, AWS Config는 구성 변경을 추적하며 규정 준수를 보장합니다. 이를 통해 워크로드의 안정성과 보안성을 강화하고, 비용 효율성을 극대화할 수 있습니다.
운영 중 생성되는 데이터를 분석하여 워크로드의 성능을 개선할 기회를 식별하는 것도 중요한 단계입니다. Amazon CloudWatch Metrics와 AWS X-Ray를 사용하면 성능 데이터를 시각화하고, 병목 현상이나 비효율성을 찾아 수정할 수 있습니다. 또한, CloudWatch Logs Insights를 활용해 로그 데이터를 분석하면 장애 원인이나 성능 저하의 근본 원인을 신속히 파악할 수 있습니다. 이를 통해 데이터를 기반으로 한 정확한 의사결정을 내릴 수 있습니다.
마지막으로 팀의 생산성을 높이는 것도 주요 과제입니다. AWS Systems Manager를 통해 중앙화된 관리 인터페이스를 제공함으로써 운영팀이 더 효과적으로 작업할 수 있도록 지원합니다. 또한, AWS Re:Post Private와 같은 지식 관리 도구를 활용하면 팀 간 정보 공유와 협업을 강화하여 효율성을 높일 수 있습니다.
결론
마지막으로, 지속적인 모니터링과 유지보수, 그리고 체계적인 거버넌스 전략을 통해 워크로드의 안정성과 성능을 지속적으로 유지할 수 있다는 점이 인상적이었습니다. 이 세션을 통해 얻은 인사이트를 바탕으로, 앞으로 AWS 환경에서 더욱 최적화된 워크로드를 구축하고 운영하는 데 큰 도움이 될 것입니다. 이 정보를 실무에 적극적으로 적용하여 더욱 효율적이고 탄력적인 클라우드 환경을 만들어 나가겠습니다.
