
[reinvent 2024] 데이터 분석 플랫폼으로서의 Amazon EKS
Summary
Amazon EKS에서 실행되는 분석 워크로드가 계속 증가함에 따라, 데이터 엔지니어는 분석 작업을 실행하기 위한 인프라를 생성하기 위한 셀프 서비스 도구가 필요합니다. 이 세션에서는 조직들이 어떻게 데이터 플랫폼을 현대화하여 코드 파이프라인으로서의 기존 인프라에서 Kubernetes API로서의 인프라로 전환하고 있는지에 대한 실용적인 인사이트를 제공합니다. 데이터 플랫폼 팀은 Kubernetes용 AWS 컨트롤러(ACK)와 같은 오픈 소스 기술을 사용해 데이터 엔지니어가 분석 작업을 실행할 수 있는 온디맨드 네임스페이스와 클러스터를 생성하여 워크플로우를 간소화할 수 있도록 지원할 수 있습니다.
리인벤트 2024 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며

데이터 활용의 중요성과 다양한 사용자 페르소나

데이터 사용자(개발자, 데이터 분석가 등)들은 본인들이 수행하는 워크로드에 적합한 오픈소스, 컴퓨팅 자원, 스토리지, GPU 자원 등을 요구합니다. 이들이 사용하는 데이터가 어디에 위치하는지, 네트워크는 어떻게 구성되어 있는지, 보안적으로 신경쓸 것은 없는지 등의 여러 고민해야 할 요소들이 있습니다. 플랫폼 팀은 이런 것들을 종합적으로 고려하여 데이터 처리에 대한 라이프 사이클을 제공해야 합니다.
최근에는 많은 고객들이 서비스를 제공하기 위한 인프라를 표준화하기 위해 쿠버네티스를 사용하고 있고, 이를 위해 EKS 사용하는 경우가 많습니다. 이러한 환경에서, 자유로운 인프라 사용을 원하는 사용자들과 쿠버네티스를 관리해야 하는 플랫폼 팀 간의 경계를 구분하는 일은 매우 힘든 일입니다.

AWS에서는 이러한 다양한 패턴의 사용자들의 니즈에 맞춰 쿠버네티스 위에서 데이터를 사용할 수 있도록 Data on EKS를 런칭했습니다.

Data on EKS는 AWS의 다양한 데이터 관련 솔루션들을(S3, MSK 등) 이용하여 데이터를 수집하고, 다양한 오픈소스 잡 스케쥴러(Argo Workflow, Airflow 등), 배치 스케쥴러(YUNIKORN), 데이터 분석 도구(Spark, Flink) 등을 활용하여 데이터를 처리하는 기능을 제공합니다. 처리된 데이터는 BI 도구 등에서 이용되며 이 때 데이터는 Amazon Athena 등의 솔루션을 통해 데이터 저장소에서 쿼리됩니다.
Kubernetes에서의 데이터 플랫폼을 더욱 최적화하기 위한 여러가지 기법

클러스터를 운영하다보면 IP가 고갈되는 문제를 겪을 수 있습니다. 이를 해결하기 위해 오버레이 네트워크를 이용하면 레이턴시가 증가하기 때문에 사용자의 요구 사항에 맞추지 못할 수 있습니다. 이를 해결하기 위해 별개의 IP 공간을 secondary CIDR로 등록하여 사용할 것을 권장합니다. 여기서는 CG-NAT(Carrier Grade NAT) 대역대의 사용을 예로 들고 있습니다.

VPC-CNI는 WARM_ENI_TARGET 옵셥값이 기본적으로 1로 설정됩니다. 이는 한 노드에 과도하게 많은 IP를 미리 할당하는 문제를 일으킬 수 있습니다. 따라서 MAX_ENI=1 옵션과 maxPods: 30 옵션을 추가하는 것을 권장합니다. 마지막으로, IP가 필요할 때마다 EC2 API를 호출하도록 동작하게 되면 API를 너무 많이 호출해 리밋에 걸리게 될 수 있습니다. 이를 방지하기 위해 한 번 IP를 할당받을 때, 단일 IP를 할당받지 않고 Prefix를 할당받도록 ENABLE_PREFIX_DELEGATION=true 설정을 권장합니다.
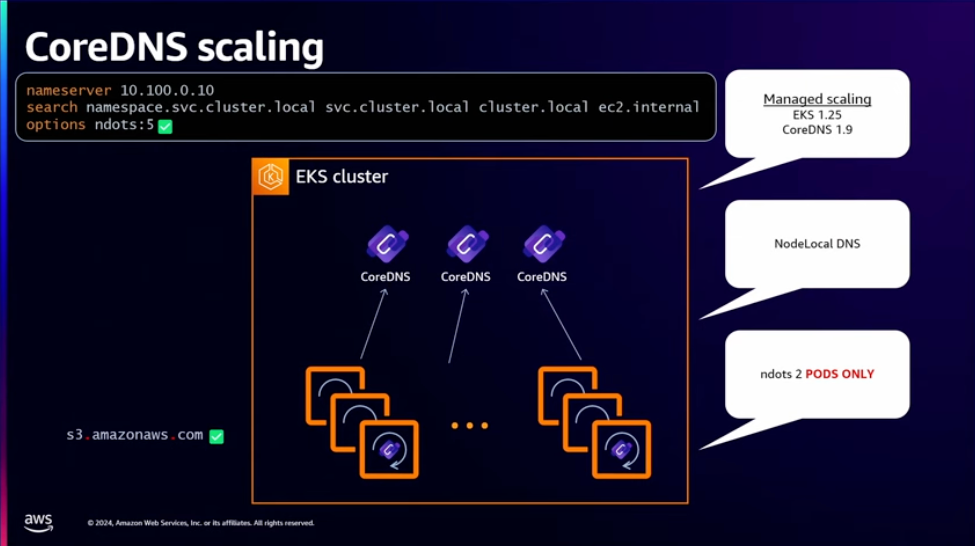
CoreDNS는 쿠버네티스에서 굉장히 중요한 애드온입니다. 따라서 부하가 많이 생길 때 자동적으로 수평 확장되도록 autoscaling.enable=true 옵션을 사용하길 권장합니다. 또한 NodeLocalDNS를 이용하면 CoreDNS로 가해지는 부담을 덜 수 있습니다. 마지막으로 ndots 옵션을 2로 설정하여 점이 두 개 이상인 도메인은 FQDN이라는 설정을 함으로써 해당 도메인에 대한 쿼리 횟수를 크게 줄일 수 있습니다.
이 외에도 Karpenter, 스토리지, ECR을 더 잘 사용하는 방법, 모니터링을 더 잘 하는 방법 등의 실전적인 가이드를 주고 있습니다. 여기서 다 설명드리기에는 양이 많기 때문에 생략했습니다.
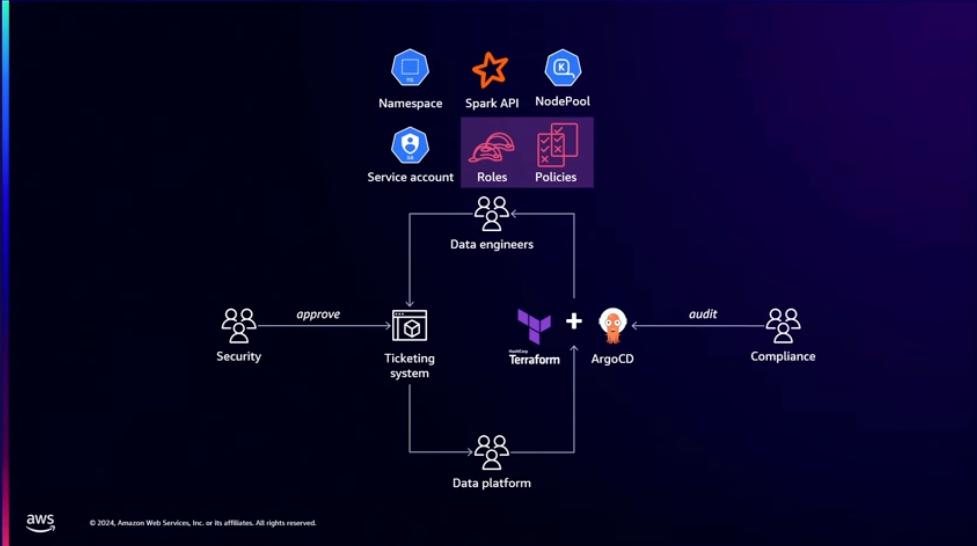
새롭게 인프라를 구성할 때, 거치는 과정들이 있습니다. 데이터 엔지니어가 인프라 구성을 요청하는 티켓을 생성하면, 보안 담당자가 이 티켓을 승인해야 하고, 데이터 플랫폼 팀의 누군가가 인프라를 구성하게 됩니다 인프라 구성이 완료되면 컴플라이언스 팀에서 구성된 인프라에 대한 감사를 수행합니다.
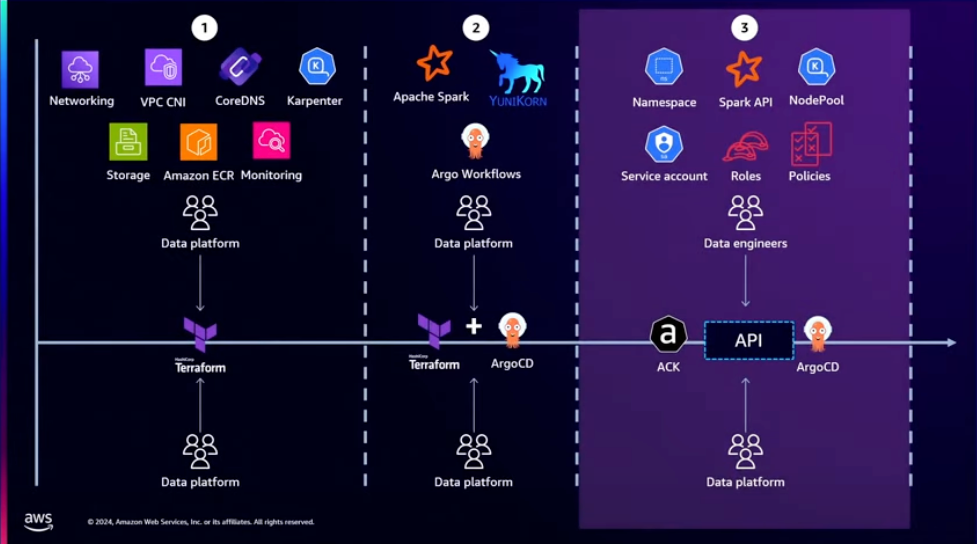
ACK를 이용하여 이 일련의 과정을 쿠버네티스 API를 통해 수행할 수 있도록 구성할 수 있습니다. ACK는 쿠버네티스 API를 이용하여 AWS의 각종 자원(IAM, S3 버킷 등)을 생성할 수 있는 도구입니다. Terraform 등의 IaC 도구를 이용하면 인프라를 생성할 때마다 새로운 코드가 생성되고, 어떤 프로세스로 apply를 수행할 것인지도 정해야 하고, 서로 다른 방법으로 운영될 수도 있습니다. 이는 운영 효율성을 낮추게 됩니다. ACK를 이용하면 더욱 간단하고, 표준화된 작업 방식을 구현할 수 있습니다.
AppsFlyer의 사례
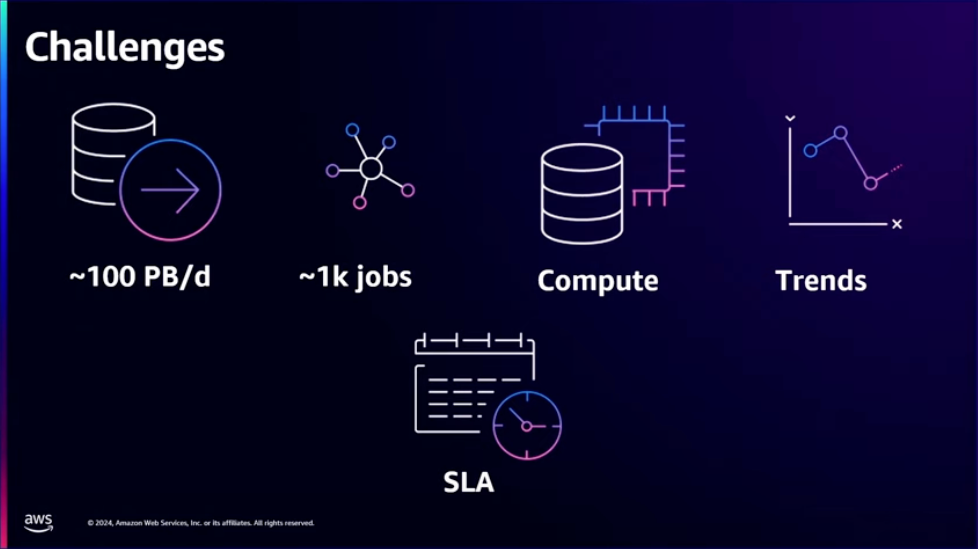
AppsFlyer는Spark를 사용합니다. 하루에 최대 100 PB의 데이터를 수집하고, 1000개의 잡을 수행합니다. 초당 수백만 건의 데이터를 처리하며 SLA가 있기 때문에 데이터를 적시에 제공해야 합니다. 이를 만족하기 위해 AppsFlyer는 쿠버네티스 위에서 비용/성능 최적화가 용이한 확장성 좋은 데이터 플랫폼을 구축했습니다.

AppsFlyer는 Karpenter를 통해 스케일링 작업을 수행했습니다. 언제든지 파드가 종료되어도 문제 없이 동작하도록 설정하여 Sopt 인스턴스의 사용을 늘리고 하나의 작업은 모두 같은 AZ에서 실행되게끔 설정하여 데이터 통신 비용을 줄이는 등의 노력을 통하여 비용 효율성을 높일 수 있었습니다.

Karpenter를 통해 실시간으로 데이터 처리 파이프라인의 비용 모니터링이 가능하게 했고, 이는 기술적으로도 비즈니스적으로도 매우 유용한 지표입니다.
