
[reinvent 2024] AWS 다중 Region 아키텍처를 만드는 모범 사례
Summary
이 세션에서는 다중 지역 아키텍처 설계와 구축 시 고려해야할 중요한 내용을 다룹니다. 장애 조치 전략의 장단점을 분석하고, 리전 간 장애 조치를 실행하는 방법과 프로세스를 설명합니다. 또한, 삼성 계정의 다중 지역 애플리케이션 사례를 통해 관련 과제를 해결하는 방법을 공유합니다.
리인벤트 2024 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며
이번 세션을 신청한 이유는 AWS 다중 리전 아키텍처와 관련된 실질적인 모범 사례를 배우고자하여 신청하였습니다. 빠르게 변화하는 클라우드 환경 속에서 장애 조치 전략은 비즈니스 연속성을 보장하는 핵심 요소로, 이 주제에 대해 이해하고 실제 업무에 적용하고자하는 마음에 신청하게 되었습니다. 또한, 삼성전자와 같은 대기업 사례를 통해 실질적인 인사이트를 얻을 것을 기대하였습니다.

Multi-Region의 기본 사항
AWS는 전 세계적으로 34개 리전과 600개 이상의 엣지 로케이션을 통해 고객에게 높은 성능과 복원력을 제공합니다. 모든 리전은 최소 3개 이상의 가용 영역을 통해 고가용성 애플리케이션을 지원하며, AWS 백본 네트워크는 저지연, 고속 연결을 제공합니다. 다중 지역 워크로드 전환의 주요 이유는 성능 향상, 규제 요구사항 준수, 가용성 향상으로 요약할 수 있습니다.
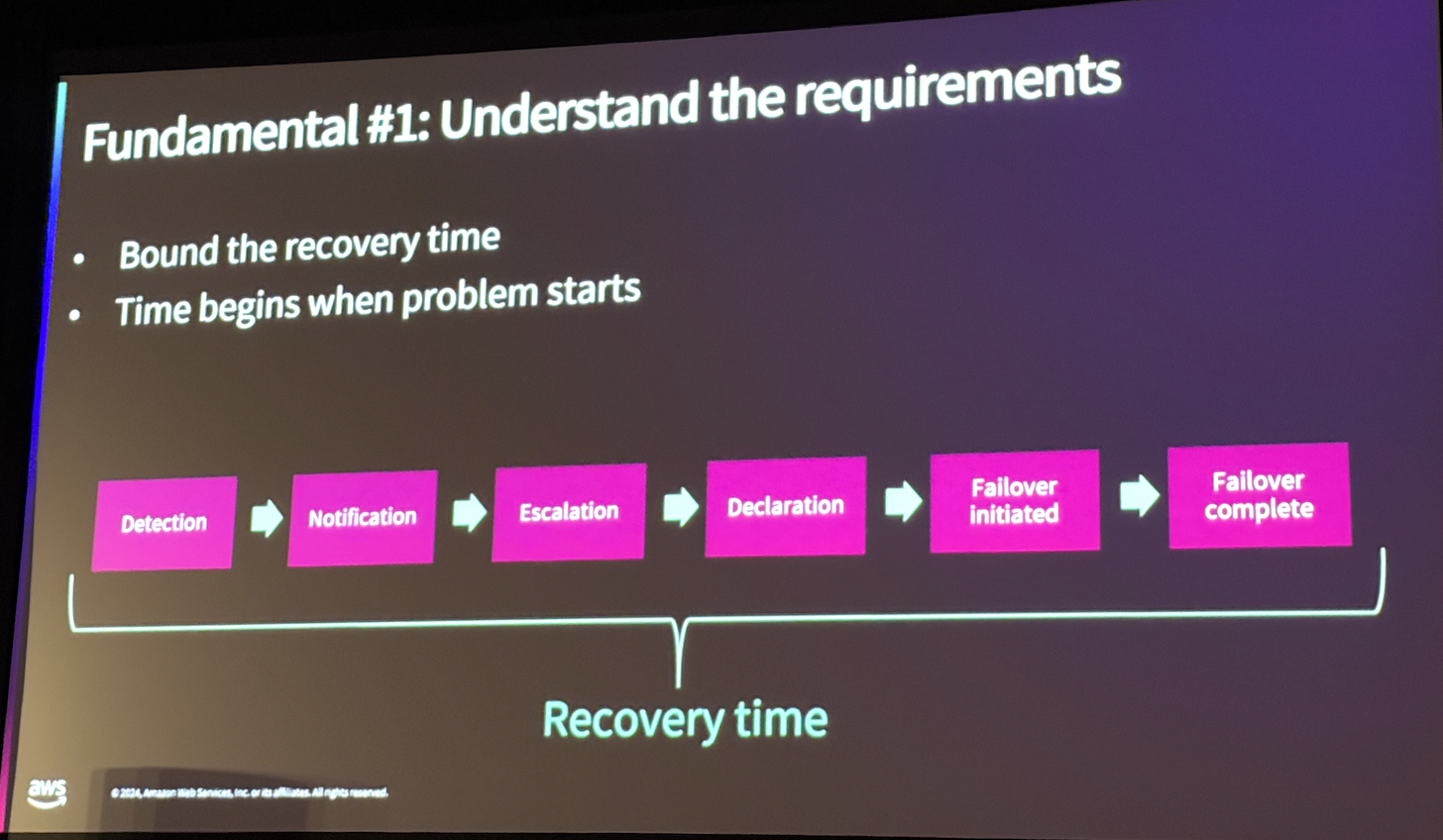
기본 원칙 1 : 요구사항을 이해해라
가장 중요한 기본 원칙은 요구 사항을 명확히 이해하는 것입니다. 고객의 요구사항을 제대로 파악하지 못하면 확장성, 성능, 복원력 같은 조건을 충족하기 어렵습니다. 특히, 지리적으로 분산된 사용자에게 낮은 지연 시간과 높은 성능을 제공하기 위해 리전 간 최적화가 필요하며, 이를 실현하기 위해 페일오버 프로세스를 상세히 분석하고, 복구 시간을 줄이는 단계별 개선이 이루어져야 합니다.
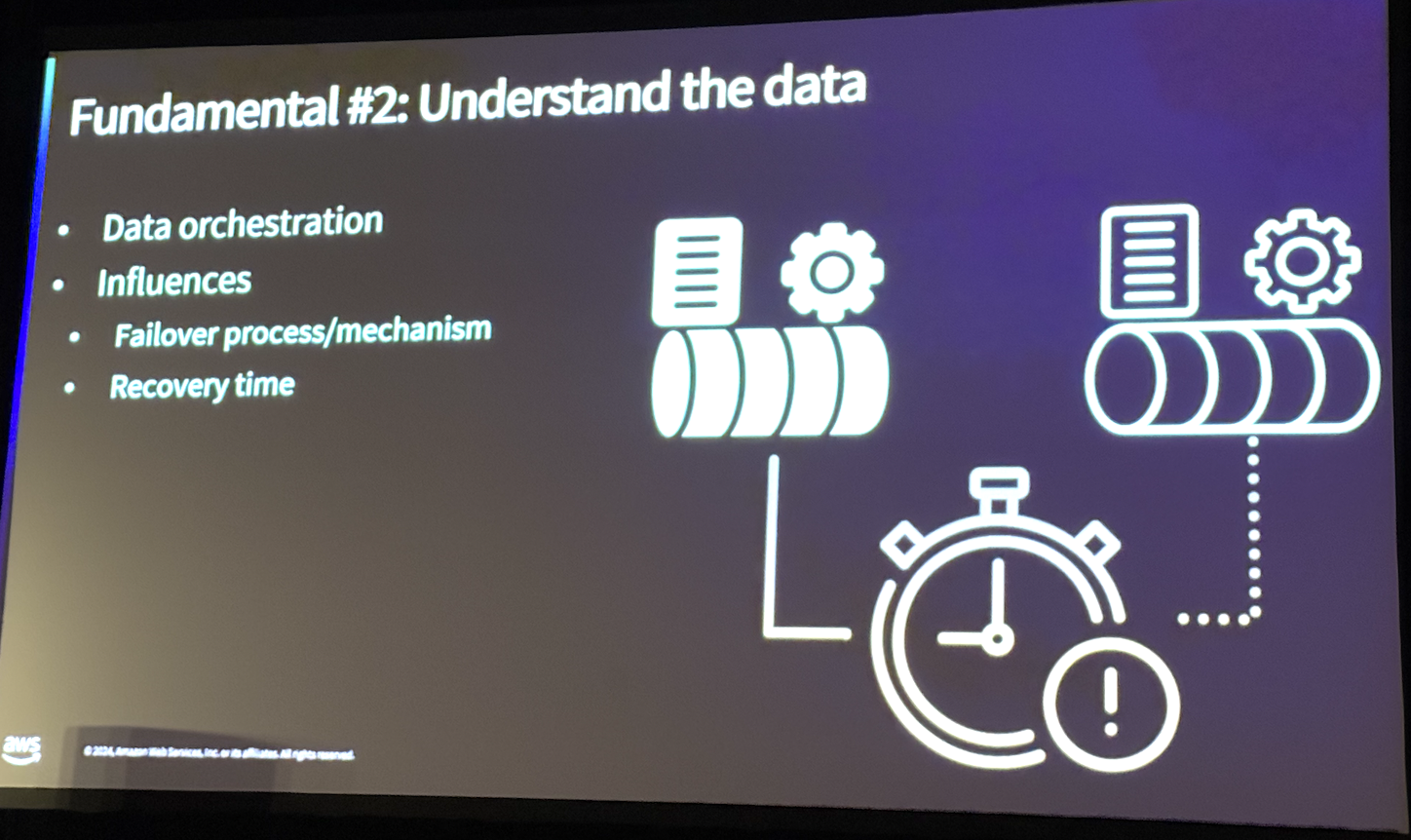
기본 원칙 2 : 데이터를 이해해라
데이터에 대한 깊은 이해도 멀티 리전 아키텍처 설계에서 중요한 부분입니다. 데이터는 위치와 복제 방식(실시간, 동기식, 비동기식), 일관성 수준에 따라 복잡성이 증가합니다. 또한, 허용 가능한 데이터 손실 수준과 복제 지연 한도를 설정하고 지속적으로 모니터링해야 합니다. 복제 지연이 허용 한도를 초과하는 경우 아치텍처에 문제가 발생했음을 의미하며, 활성 복제 전략을 통해 이러한 문제를 해결할 수 있습니다. 예를 들어, 복구 시간이 만족스럽지 않은 경우 백업 복구 전략을 활성 복제로 전환하여 더 빠른 복구를 실현할 수 있습니다.

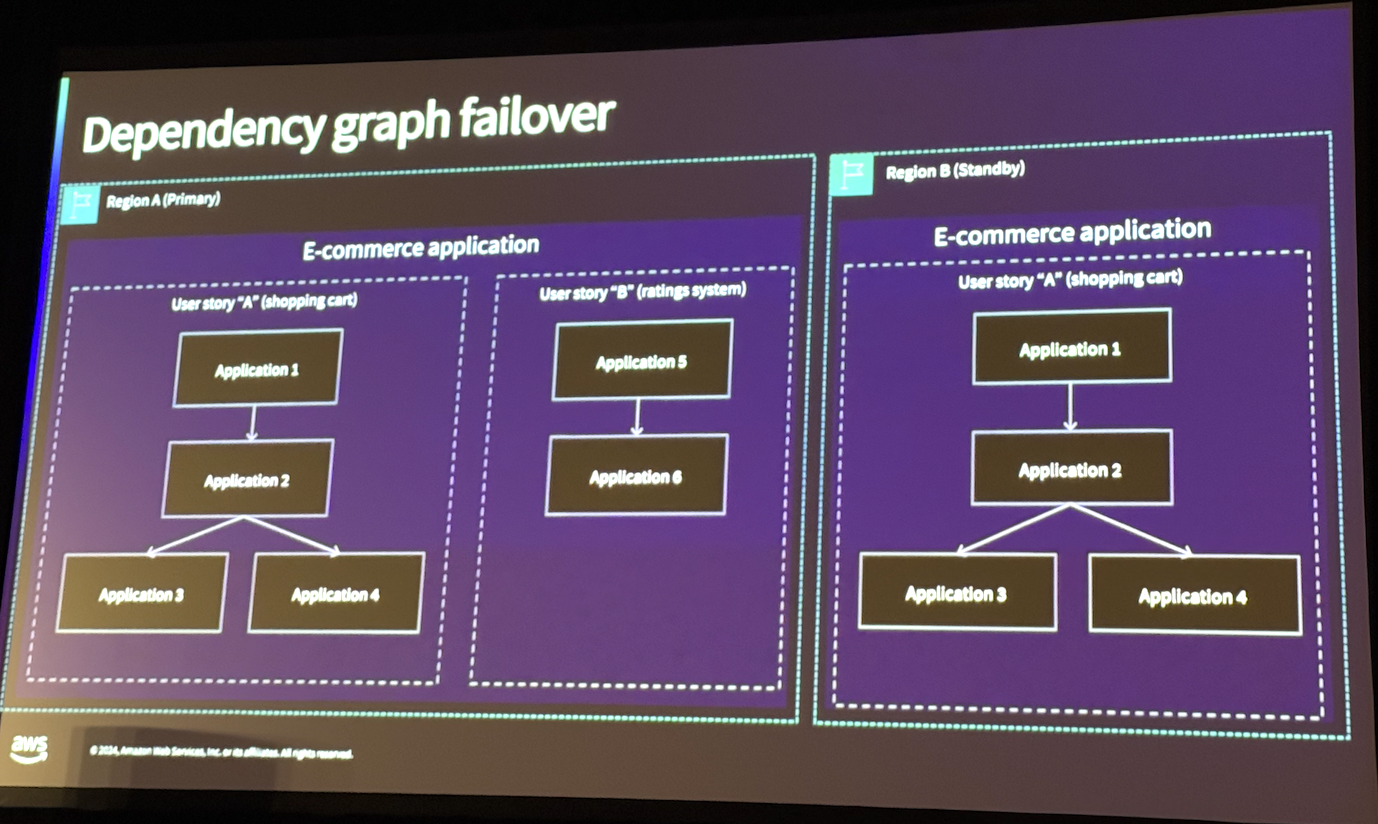
기본 원칙 3 : 종속성을 이해해라
멀리 리전 설계에서 종속성을 이해하는 것도 매우 중요합니다. 장애 발생 시 한 리전이 다른 리전과 독립적으로 운영될 수 있어야 하며, 복구 워크로드는 복구 리전 내에서만 실행되어야 합니다. 이를 통해 한 리전에서 발생한 문제가 다른 리전에 영향을 미치는 것을 방지할 수 있습니다. 또한, 주요 사용자 스토리를 기반으로 종속성을 분석하고 우선순위를 결정해야하며, 복구 리전 내에서만 복구 워크로드를 실행할 수 있도록 구성해야합니다.

기본 원칙 4 : 운영 준비 상태 및 지속적 개선
운영 준비 상태와 지속적 개선도 중요한 원칙입니다. 멀티 리전 애플리케이션의 운영 개선은 명확한 목표에서 시작되며, 테스트를 통해 페일오버 프로세스를 검증하고 개선해야 합니다. 테스트는 제어된 환경에서 이루어지며, 이를 통해 스케일링 특성, 구성 드리프트, 서비스 제한 등 다양한 문제를 확인할 수 있습니다. 또한, 관측 가능성을 개선하여 애플리케이션의 상태를 다양한 관점에서 모니터링해야 합니다. 서버 상태뿐만 아니라 타임아웃, 예상치 못한 오류를 포함한 차별화된 모니터링은 멀티 리전 애플리케이션 운영 상태를 최적화하고 장애 시 복구를 보다 효과적으로 수행할 수 있도록 돕습니다.
조직 Failover 전략 및 Failover 시점 결정
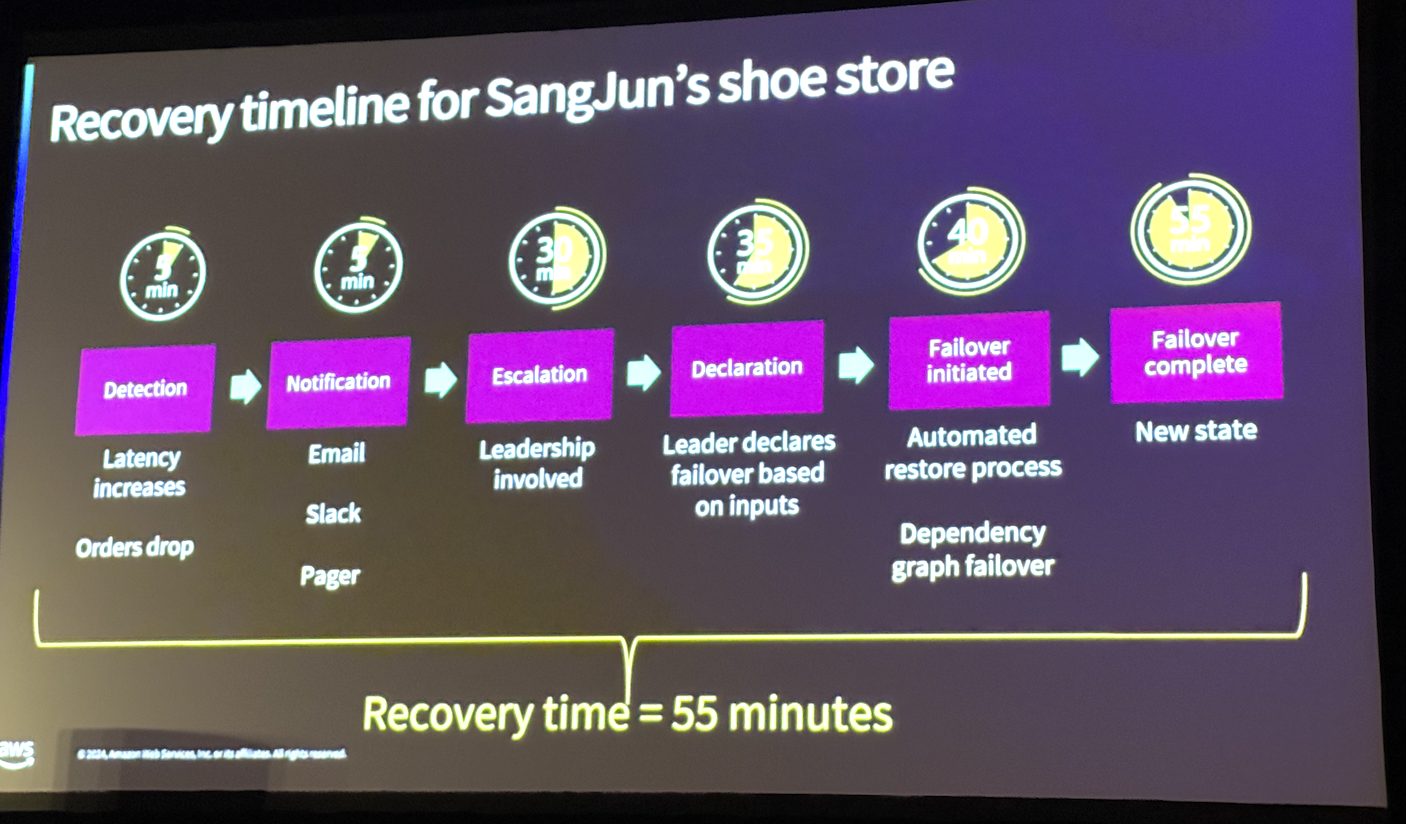
장애 조치는 비즈니스 연속성을 위한 핵심 전략으로, 장애 발생 시 최소한의 중단으로 시스템을 복구하는 것을 목표로 합니다. 장애 조치를 설계할 때 조직은 워크로드의 중요성과 복잡성, 예상 비용 등을 동시에 고려하여 적합한 전략 선택이 필요합니다.
- Active-Active 구성 : 두 리전이 동시에 활성 상태를 유지하며 트래픽을 처리합니다.
- Active-Passive 구성 : 하나의 리전이 활성 상태로 동작하고 다른 리전은 대기 상태로 유지되다가 장애 시 활성화 됩니다.
- Pilot Light 구성 : 필수 구성 요소만 복제하여 유지하다가 필요 시 전체 워크로드를 활성화 합니다.
- Warm Standby 구성 : 축소된 버전의 워크로드를 유지하며, 장애 시 확장 가능합니다.
장애 조치를 실행할 시점을 결정하는 것은 아키텍처 설계의 핵심입니다. AWS는 다양한 도구를 제공하여 실시간 모니터링과 자동화된 장애조치를 지원하는데, AWS CloudWatch, AWS Route 53 헬스체크 기능이 대표적입니다. AWS CloudWatch를 통해 애플리케이션 상태를 실시간으로 모니터링하고 AWS Route53 헬스체크 기능을 활용해 장애를 신속하게 탐지하고 자동으로 트래픽을 다른 리전으로 전환합니다. 또한, 사전 정의된 임계값을 설정하여 성능 문제 발생 시 자동으로 장애 조치를 트리거하여 다운 타임을 최소화하고 신속한 복구를 지원합니다.
위의 모든 내용을 종합하여 장애 조치의 중요한 몇 가지 체크포인트는 아래와 같습니다 :
첫째, AWS 인프라는 멀티 리전 요구를 충족할 수 있도록 설계되어야 합니다. 멀리 리전 설계는 장애상황에서도 시스템의 연속성을 보장하는데 필수이며, 성공적인 운영을 위한 기본 사항임을 항상 염두해야 합니다.
둘째, 사고가 발생하기 전에 페일오버 기준을 명확히 정의하는 것이 중요합니다. 이러한 기준은 장애상황에서 신속하고 이성적인 의사결정을 가능하게 합니다.
셋째, 비즈니스 요구사항, 기술적 역량, 조직 구조에 적합한 페일오버 전략을 선택해야 합니다.
마지막으로, 정기적으로 실제 상황을 시뮬레이션하여 페인오버 계획을 철저히 테스트해야 합니다.
이러한 체크포인트를 철저히 준비하고 실행하다면, 장애 조치 과정에서 효율성과 성공률을 향상시킬 수 있을 것입니다.
삼성 계정의 Multi-Region 여정
삼성전자는 단일 리전에서 다중 리전으로 전환하는 과정에서 아래의 단계를 거쳐 진행한 것을 발표하였습니다. 이 과정은 기업이 다중 리전 아키텍처를 효과적으로 구현하는데 실질적인 인사이트를 제공하였습니다.
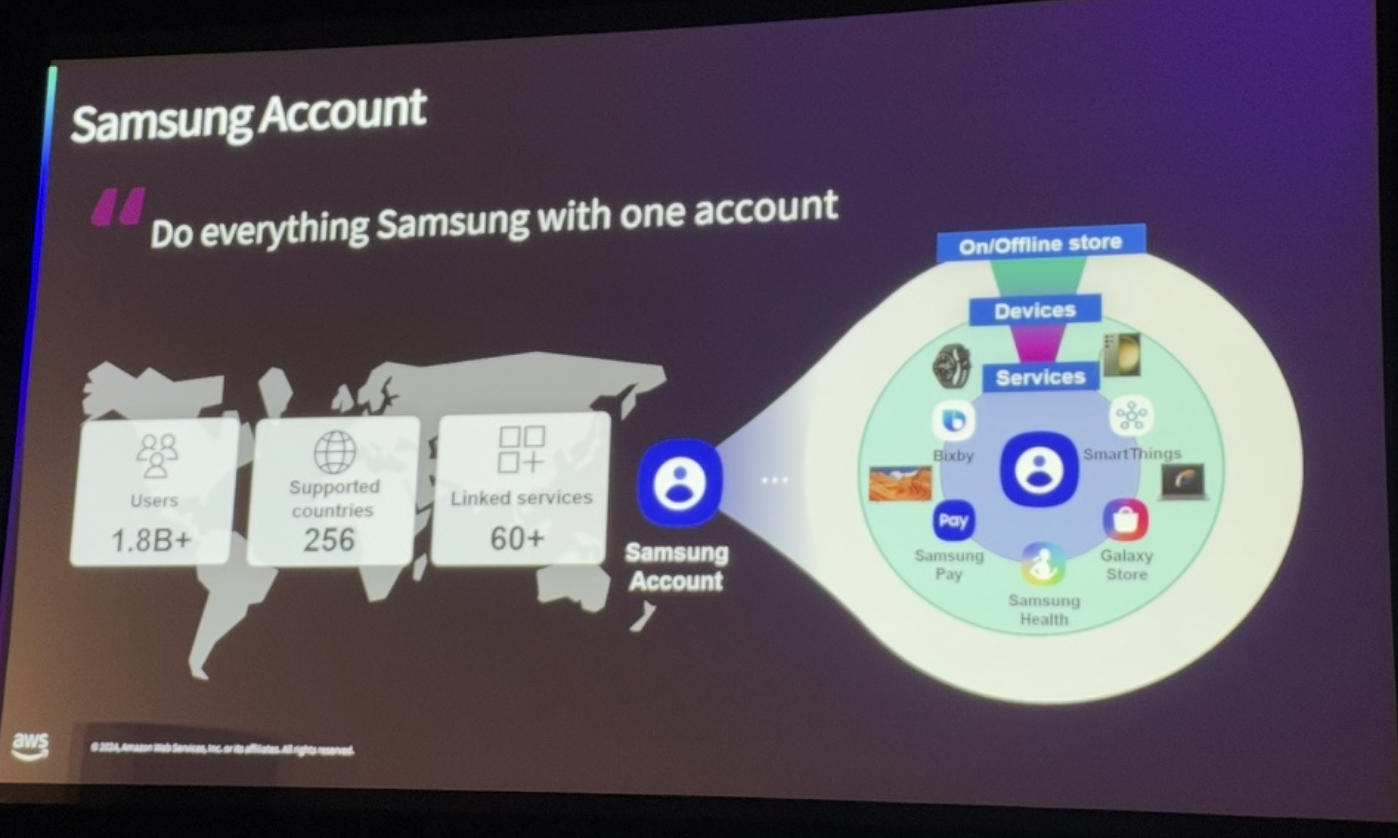
“하나의 계정으로 모든 삼성 서비스를” 이라는 슬로건처럼, 삼성 계정은 전 세계 18억 사용자를 하나의 생태계로 연결하며, 모든 삼성 기기와 60개 이상의 서비스를 지원하는 핵심 시스템입니다. 높은 트래픽을 처리하고 안정성을 유지하기 위해 세 개 리전(EU, US, AP)에 걸친 글로벌 재해 복구 아키텍처를 구현하였으며, 초당 270만 건 이상의 트래픽을 안정적으로 처리하였습니다.
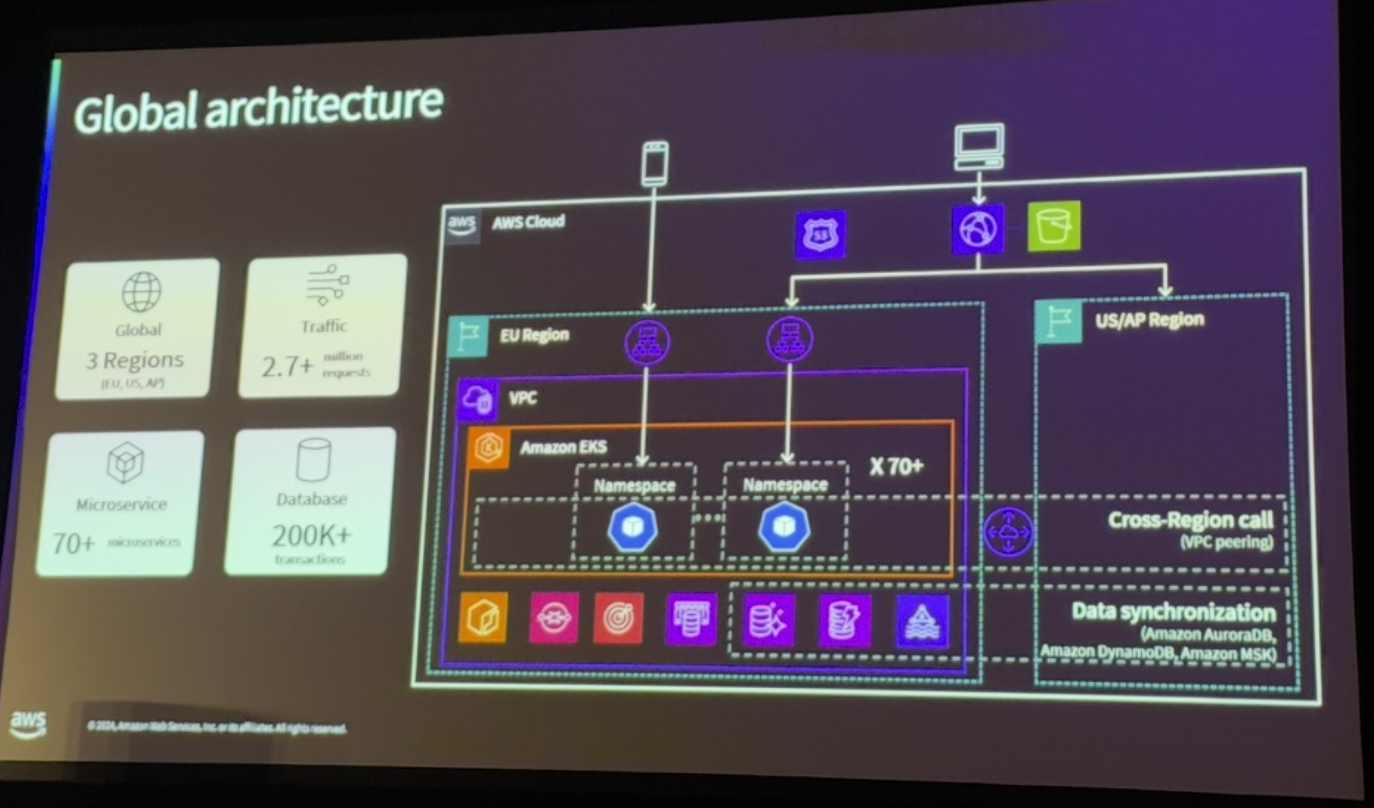
삼성 계정은 70개 이상의 마이크로서비스로 구성된 마이크로서비스 아키텍처를 도입하고, Amazon EKS, Aurora DB, DynamoDB, ElastiCache 등을 활용하여 높은 가용성과 성능을 지원하였습니다. 새 AP 리전 구축과 서비스 통합으로 세 리전 모두 모든 기능을 지원하며, Active-Active 아키텍처로 전환해 리전 장애에도 안정적인 서비스 운영이 가능하도록 설계하였습니다. 데이터 동기화는 Aurora DB 기반 자체 파이프라인과 Dynamo DB의 Global Table을 활용하였습니다.

삼성은 트래픽 라우팅을 효율적으로 관리하기 위해 두 가지 방안을 고려하였습니다. 첫번째는 Global Load Balancer를 사용한 방법으로, 리전 간 트래픽을 즉시 재라우팅할 수 있지만 비용이 비싼것이 단점이었습니다. 두번째는 DNS 기반 트래픽 라우팅으로, Amazon Route 53을 활용하여 장애 발생 시 DNS 레코드를 수정하여 비용을 절감하면서도 간단한 장애 대응이 가능하여, 비용 절감과 운영 복잡성 감소를 고려하여 삼성 계정의 글로벌 디지털 복구 아키텍처는 “DNS 기반 트래픽 라우팅”으로 선택하였습니다.
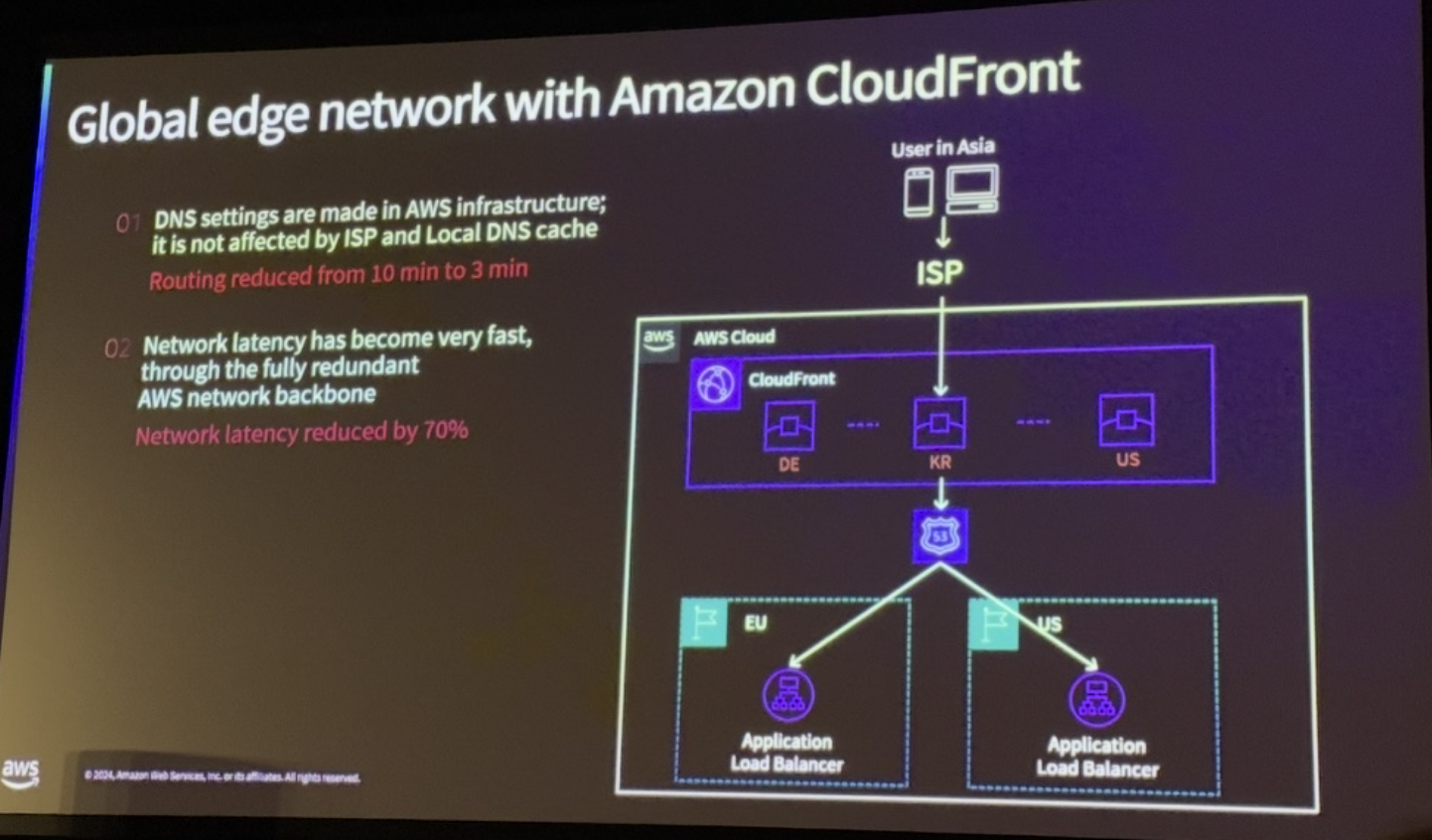
삼성 계정은 DNS 기반 트래픽 라우팅에서 10분 이상의 지연을 확인하고, 이로 인해 발생하는 문제를 해결하기 위해 CloudFront를 모든 API에 적용하였습니다. AWS 엣지 네트워크를 활용하여 DNS를 전환을 AWS 내부에서 처리하고 이를 통해 3분 이내에 대규모 트래픽 전환을 달성하였고 600개 이상의 경로를 통해 API 전송 지연 시간을 70% 감소시켰습니다. 그러나 AWS Route53의 제어 플레인이 US-EAST-1에 위치해 있어 이를 개선해야할 필요성이 있었습니다.
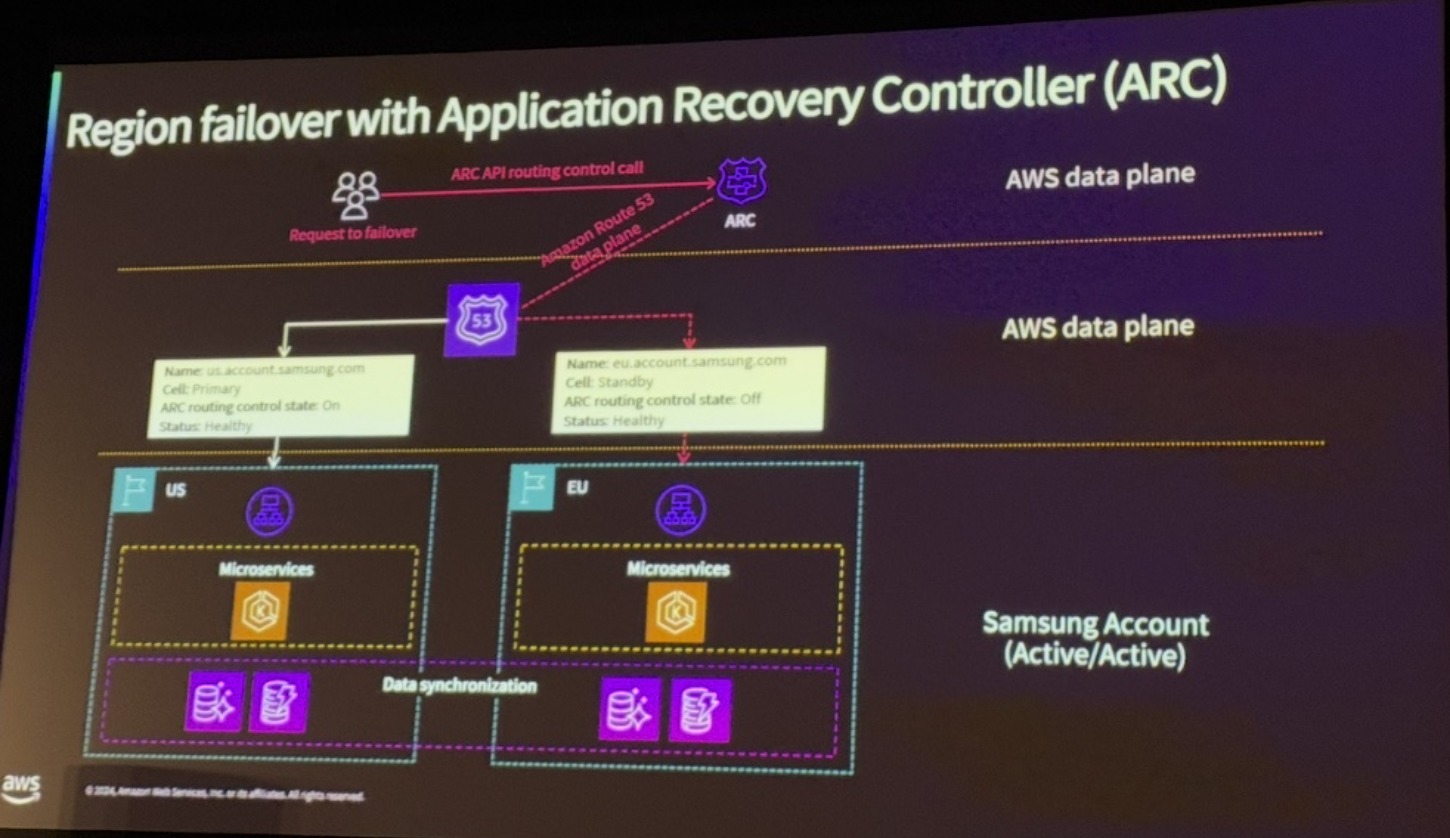
AWS Application Recovery Controller(ARC)는 Route53 제어플레인에 문제가 발생해도 트래픽을 정상적으로 전환할 수 있도록 지원하는 기능입니다. ARC는 미리 구성된 라우팅 세트를 활용하여 헬스 체크를 통해 트래픽을 자동으로 전환합니다. 정상 상태에서는 트래픽이 US 리전으로 라우팅되며, 장애 발생 시에는 EU 리전으로 트래픽을 전환하여 리전 장애 복구를 보장합니다. 이로 인해 삼성 계정은 높은 가용성과 견고한 재해 복구 아키텍처를 유지할 수 있습니다.
결론
이번 세션은 AWS 다중 리전 아키텍처 설계와 장애 조치 전략을 이해하는데 중요한 내용을 제공하였습니다. 특히 삼성전자의 사례를 통해 다중 리전 아키텍처 전환의 실질적이고 성공적인 방법을 배울 수 있었습니다.
세션을 통해 가장 인상 깊었던 점은 장애 조치의 중요성을 현실적인 사례와 함께 설명한 점이었습니다. 단순한 이론적인 지식에 그치지 않고, AWS의 구체적인 도구와 전략을 활용하여 실제 비즈니스 환경에서 어떻게 적용될 수 있는지 이해할 수 있었습니다. 또한, 삼성전자의 경험을 통해 글로벌 워크로드 관리와 고가용성 실현에 있어 발생할 수 있는 문제와 그 해결방안을 배울 수 있었습니다.
이번 세션을 통해 얻은 지식은 앞으로의 프로젝트에 큰 도움이 될 것이라 자부합니다. 특히, 장애 조치 전략과 다중 리전 아키텍처의 설계의 필요성을 다시한번 느끼며, 이를 통해 더 나은 비즈니스 연속성을 제공할 수 있을 것이라 확신합니다. 앞으로도 이러한 모범 사례를 기반으로 AWS 인프라를 최적화하고 클라우드 환경에서의 혁신을 지속적으로 추구할 것입니다.
