
[reinvent 2024] Netflix에서 Apache Iceberg를 활용한 효율적인 증분 처리
Summary
Netflix가 Apache Iceberg와 Netflix Maestro를 결합하여 구축한 증분 처리 솔루션(IPS)에 대해 알아봅니다. 이 솔루션은 새로운 데이터나 변경된 데이터를 효율적으로 처리하여 비용과 시간을 절감하면서 데이터 정확성과 최신성을 보장합니다.
리인벤트 2024 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며
이번 칼럼에서 다룰 세션은 Neflix가 지연데이터의 증분처리를 어떻게 효율적으로 하고 있는지에 대한 세션입니다.
이 세션에서 Netflix는 증분처리에 따라오는 많은 문제들을 해결하기 위해 Apache Iceberg와 Mestro를 활용했다고 하는데요, Netflix에서 개발한 오픈소스 테이블 포맷인 Iceberg를 활용한 솔루션을 직접 Netflix 엔지니어가 나와서 설명하는 세션이라 얼마나 효율적으로 사용하는지 기대가 되어 신청하게 되었습니다.

문제점 소개
넷플릭스를 사용해보면 개인화추천 시스템을 잘 구축해 놓았는데 이 개인화추천시스템은 다양한 머신러닝 파이프라인과 데이터 파이프라인에서 도출된 데이터 인사이트를 기반으로 합니다.

또한 넷플릭스의 여러 분야의 엔지니어들과, 엔지니어가 아닌 분야의 직원들까지 모두 데이터파이프라인을 통해 인사이트를 얻습니다. (ex. 첫 페이지 색상, 다음 시즌 제작여부 등)
다양한 데이터 수요가 증가되고 이 데이터를 다루는 과정에서 세 가지 공통적인 문제가 발생합니다.
- 정확성: 모든 비즈니스 결정은 고품질 데이터에 기반해야 함
- 신선도: 데이터를 빠르게 처리해 신속한 의사결정을 지원해야 함
- 비용 효율성: Netflix는 연간 컴퓨팅 및 저장 비용으로 1억 5천만 달러 이상을 지출함

문제를 해결하는 과정에서 여러 가지 과제가 있는데, 그중 하나가 지연 데이터입니다. 예를 들어, 휴대전화 배터리가 부족해서 이벤트가 서버로 바로 전송되지 못하고 지연되는 상황이 발생할 수 있습니다.
여기서 중요한 건 비즈니스 관점에서는 처리 시점보다 데이터가 실제로 발생한 시점이 더 중요하다는 점입니다. 하지만 스트리밍 파이프라인에서는 보통 처리 시간을 기준으로 테이블을 파티션하는데, 이 방식은 파이프라인 구조를 단순화할 수 있는 장점이 있습니다. 다만, 그 결과로 분석 배치 파이프라인에서 지연 데이터를 추가로 처리해야 하는 부담이 생길 수 있습니다.
Iceberg와 Maestro를 활용한 솔루션

그래서 넷플릭스는 데이터 실무자들이 데이터 인사이트 얻고 사용자 경험을 개선하기 위해 빅데이터 분석 플랫폼을 자체적으로 구축했습니다.
해당 분석플랫폼에서 사용된 Maestro로 워크플로우 개발과 비즈니스 로직 작성을 지원하고 최종 데이터를 Iceberg Table로 효율적으로 저장하고 분석할 수 있도록 지원합니다. 결과적으로 데이터 문제점들을 해결하기 위해 이 둘을 결합해서 증분처리를 지원하는 솔루션인 IPS를 구축했습니다.

Iceberg는 넷플릭스에서 시작된 고성능 분석 테이블 포맷으로 현재 인기 있는 Apache 오픈 테이블 포맷 중 하나입니다. Iceberg를 통해 백만 개 이상의 테이블 및 테이블에서 데이터를 쓰고, 읽고, 변환하기 위해 수십만 개의 워크플로우를 생성했습니다.

이 워크플로우를 운영하고 관리하기 위해 Maestro를 활용했습니다. Maestro는 수평 확장이 가능한 워크플로우 오케스트레이터로, 워크플로우의 전체 수명 주기를 관리하며 서버리스 환경을 제공합니다. 또한 Iceberg와 통합해 데이터 관리와 분석도 효과적으로 지원합니다.
넷플릭스는 Airflow 같은 인기 있는 도구 대신 Maestro를 자체 개발해 사용하고 있습니다. 이는 넷플릭스가 겪고 있던 확장성(scalability), 사용성(usability), 확장성(extensibility) 문제를 해결하기 위해서였습니다.
아키텍처 및 패턴

이 솔루션 아키텍처 디자인에 두 개의 목표를 정했습니다.
- 데이터를 읽지 않고 변경 사항 캡처 (효율성, 보안, 개인정보 보호 준수).
- 최소한의 코드 변경으로 사용자들에게 최적의 경험 제공.

우선 증분데이터 처리 아키텍처에 대해서 설명하겠습니다.
초기에는 t1 시점에 s0 스냅샷이 있고 5개의 데이터파일이 있습니다. 이후 t2 시점에 변경사항을 반영하기 위해 s1
스냅샷을 생성합니다. 이 때 파티션정보 기반으로 데이터를 소비하려면 p0,p1,p2 를 재처리 해야합니다. 이는 s0 스냅샷의 데이터 파일을 다시 처리한다는 의미입니다. 이렇게 하는 대신 변경데이터만 포함하는 ibp라는 새로운 테이블을 생성하고, 원본 테이블 s1 스냅샷을 읽은 새로운 s2 스냅샷을 추가합니다. S1의 데이터파일 링크를 s2의 매니페스트 파일에 추가합니다. 이 아키텍처는 zero data copy 방식으로 기존 데이터를 복사하지 않아 효율적 입니다.
이 아키텍처를 바탕으로 세가지 패턴으로 다시 아래에 설명하겠습니다.

패턴 1
변경 테이블에는 실제 데이터 파일에 대한 참조만 포함됩니다.
원본 테이블의 전체 파티션(P0, P1, P2)을 다시 처리할 필요가 없습니다.

패턴 2
변경 데이터를 필터로 활용하여 불필요한 변환을 제거합니다.
이 예시에서는 변경 데이터를 읽어 원형과 다이아몬드와 같은 변경된 키만 찾습니다.
그런 다음 ETL은 원본 테이블에서 다이아몬드와 원형 키에 해당하는 데이터만 읽고, 이를 재처리하고 재집계한 후 타겟 테이블에 덮어씁니다.
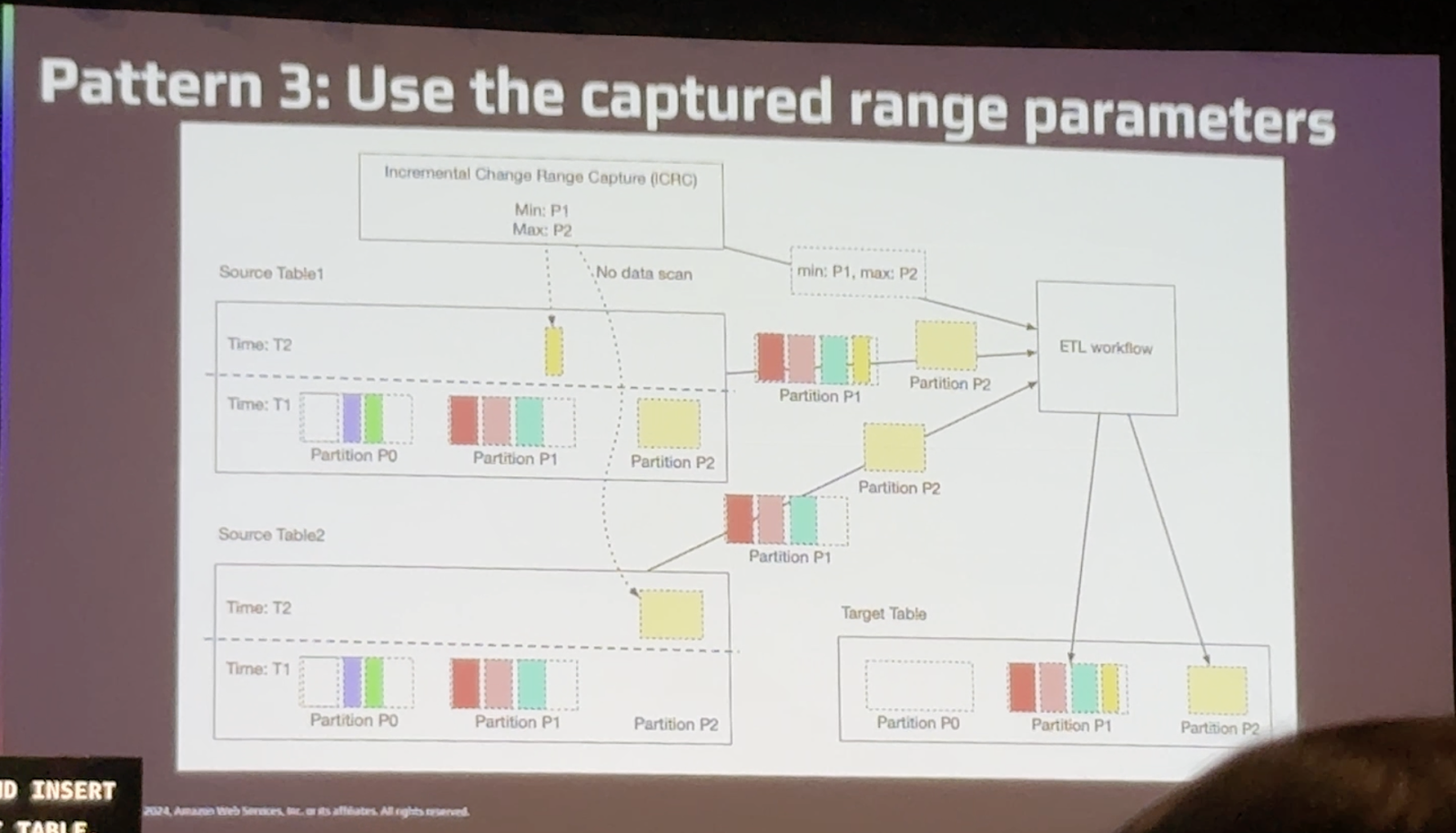
패턴3
범위 파라미터를 사용하는 것 입니다.
데이터 파일을 읽어 사용자가 관심 있는 특정 열 또는 열들의 최소, 최대값을 가져오고 테이블을 조인할 때 이 값을 기반으로 복잡한 처리를 수행합니다.

아직 비용문제가 남아있는데
넷플릭스에 있는 수많은 파이프라인을 한 번에 변경하기에는 어렵기 때문에 최소한의 코드 변경으로 마이그레이션 할 수 있는 솔루션이 필요합니다.
솔루션인 Maestro로 IP 캡처 단계,IP 커밋 단계를 수행합니다.
마지막 체크포인트부터의 변경 사항을 캡처하고 변경 사항을 범위 파라미터 또는 테이블 파라미터로 묶어 사용자 워크플로우에 전달합니다. 이후 IP 캡처 단계에서 수집한 정보를 기반으로 변경 사항을 커밋합니다.
결론

마지막으로 요약하자면 IPS 를 통해 데이터 정확성, 데이터 최신성, 비용 효율성을 달성할 수 있으며, 이는 많은 문제를 해결하고 배치작업을 사용했을 때 할 수 없었던 많은 작업을 가능하게 합니다.
Iceberg 메타데이터를 사용하여 사용자 데이터를 읽지 않고 효율적으로 변경 사항을 캡처할 수 있습니다.
세션이 생각보다 Iceberg와 Maestro를 활용한 아키텍처 및 예시를 상세히 보여줘서 어려웠지만 해당 내용을 실시간으로 들을 기회를 얻어서 참석하기 잘 했다는 생각이 들었습니다.
Iceberg를 통해 스트리밍 데이터를 처리할 수 있는 여러 패턴이 많다는 인사이트를 얻었고 워크플로 솔루션인 Maestro 에 대한 활용법을 들을 수 있어서 얻을 수 있는 게 많았던 세션이었습니다.
