
[reinvent 2024] Data on AWS: 3명의 AI Innovator의 성공의 열쇠
Summary
조직은 데이터를 사용하여 의사 결정을 내리는 방식을 혁신하고 있습니다. 이 고객 세션에서 Anthropic, Bria AI, Canva가 AWS에서 생성형 AI 모델을 훈련하기 위해 확장 가능하고 비용 효율적인 데이터 기반을 구축하고 관리하는 방법에 대해 알아보세요. 높은 수준의 집계 처리량을 확장하고, 대규모 데이터 에스테이트에서 메타데이터 카탈로그를 관리하고, AI에서 생성된 콘텐츠를 책임감 있게 저장하기 위해 성능을 최적화하는 아키텍처 접근 방식, 디자인 패턴 및 모범 사례를 살펴보세요. 컨테이너화된 애플리케이션과 데이터 환경을 통합하고, 대규모로 데이터를 준비하고, 데이터 로딩 및 체크포인팅 기술을 사용하고, 생성형 AI를 책임감 있게 구축하는 방법에 대한 통찰력을 얻으세요.
리인벤트 2024 테크 블로그의 더 많은 글이 보고 싶다면?

Overview
들어가며
이번 세션에서는 최근 많은 기업들이 해결하려고 노력중인 세 가지 주요 주제에 대해 알아보았습니다.
데이터 품질 및 방대한 데이터에서 원하는 고품질 데이터셋을 선별하는 방법, 스토리지 성능을 극대화 해 컴퓨팅의 장점을 최대한 활용하는 방법, 마지막으로 대규모 스토리지를 구성할 때 장기적인 관점에서 탄력적으로 확장할 수 있도록 하는 방법에 대해 살펴보겠습니다.

Data Curation
다양한 데이터 소스에서 막대한 양의 데이터가 수집되고 있는 요즘 핵심은 이 데이터를 어떻게 다룰것인가 입니다. 대부분의 경우 비즈니스적인 결론을 내기 위해 이 모든 데이터가 필요하지 않을겁니다. 특정 분야에 대한 답을 위해선 특정 분야에 대한 데이터만 필요합니다. 이 부분에서 Data Curation의 개념이 나오게 됩니다. Data Curation이란 특정 목적을 위해 데이터를 정제하고 정리하는 것을 말합니다.

이러한 Curation이 중요한 이유는 또 있습니다. Data가 수집되는 것 부터 실제 사용되어 어떤 결과가 나오기까지의 End-to-End Pipeline을 생각해보면, Data가 내가 원하는 목적에 맞게 잘 정돈 되어있지 않으면 필요한 데이터를 찾기 위해 병목현상이 발생하게 됩니다. 그로 인해 GPU 시간단위로 비용이 발생하는 다음 프로세스는 의미 없는 idle 시간이 추가되고 이는 곧 의미 없는 리소스 사용으로 이어집니다. 전체 프로세스가 느려지는 것은 물론 추가적인 비용까지 발생합니다.
Canva 케이스
Canva는 그래픽 디자인 플랫폼으로, 사용자가 본인의 데이터로 손쉽게 디자인 콘텐츠를 생성할 수 있도록 돕는 도구입니다. 사용자의 데이터를 사용할 수 있기 때문에 항상 기업에서 원하는 데이터만 활용되지 않습니다. 정책에 맞지 않는 데이터가 사용될 수 있고, Canva에서는 이를 막을 방법을 찾아야 했습니다.

그래서 Content Moderation을 도입했습니다. Canva에 업로드되는 모든 컨텐츠들은 다음 아키텍쳐를 따라 처리되도록 되어있습니다. Amazon Rekognition 및 Model을 활용하여 컨텐츠가 안전한지, 그렇지 않은지, 아니면 Human check가 필요한지 여부를 따지게 됩니다.

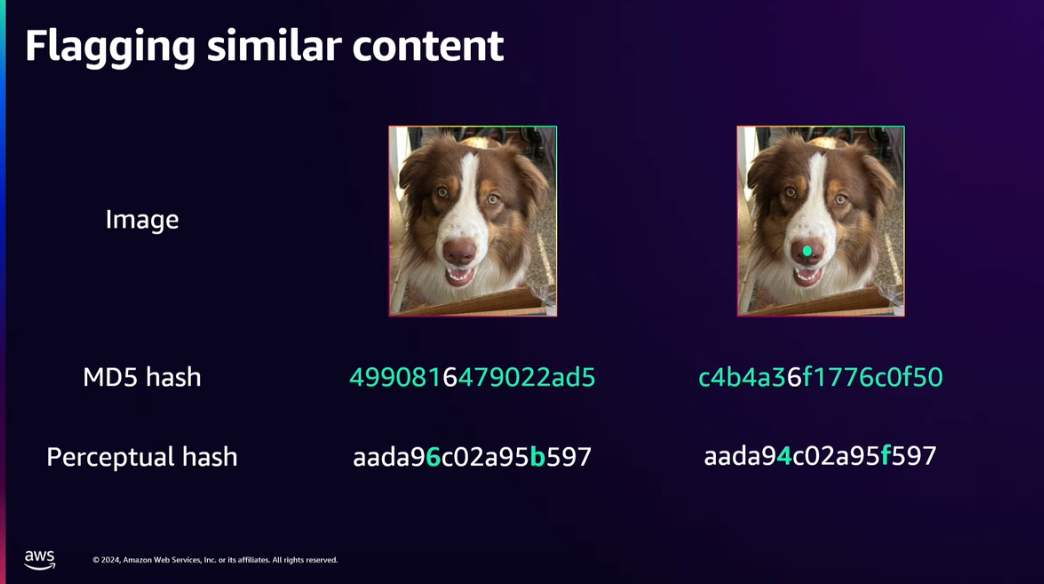
또한, Perceptual hash를 통해 유사 콘텐츠를 감지하고 특정 문제가 발생하면 그와 유사한 콘텐츠를 함께 찾아내 조치할 수 있습니다.
Bria AI 케이스
Bria는 모델을 훈련시키기 위해 다음과 같은 아키텍쳐 및 비즈니스 모델을 활용하여 서비스를 운영합니다.

1) Data Onboarding
데이터 파트너로부터 제공받은 데이터를 ETL과정을 통해 Amazon S3, EKS data pipelines 등으로 수집, 적재합니다.

2) Data Catalog
적재된 데이터는 Data Catalog에 색인되어 추가되고 이는 이후 모델 훈련 데이터로 활용합니다.

3) 모델이 Inference 되면 Attribution Engine을 통해 활용된 이미지를 추적하고 해당 데이터를 제공한 파트너에게 적절한 수익을 배분합니다.

Anthropic 케이스
Anthropic은 과거에 비해 훨씬 많은 양의 데이터를 훨씬 빠른 시간 내에 처리하고 있습니다. 어떻게 데이터를 처리하고 있는지 알아보겠습니다.

Anthropic은 기본적으로 S3의 다양한 서비스를 통해 탄력적인 스토리지를 구성하고 있습니다.
고성능 작업, 특히 shuffle을 많이 사용하는 작업에서는 S3 Express One Zone을 활용합니다. 이 서비스는 하둡, EBS 등 기타 파일시스템을 대신하며 필요한 만큼 IOPS를 처리할 수 있도록 합니다.
대역폭을 많이 필요로 하는 작업에서는 Cross-bucket replication을 활용합니다. 이를 통해 데이터를 컴퓨팅 리소스와 동일한 곳에 저장할 수 있지만 그곳에서 처리할 필요는 없습니다.
마지막으로 S3 Intelligent-Tiering을 통해 한번 모델훈련에 사용하면 다시 사용되지 않는 90%의 데이터를 자동으로 데이터를 계층화하여 비용을 절감합니다.

결론
별도의 모델과 파이프라인을 구성하여 서비스에 적합한 데이터만 걸러내는 Canva, 필요한 데이터만 파트너로부터 제공받아 수익을 공유하는 Bria AI, S3 스토리지를 적극적으로 활용하여 계층적인 분류를 통해 Curation을 하는 Anthropic의 사례까지 살펴봤습니다. 실제로 생성형 AI 관련 업무를 진행하다 보면 Data Curation이 반영되지 않아 의미 없는 데이터가 포함되는 등 다양한 문제를 경험할 수 있는데 이러한 다양한 케이스를 통해 Data Curation이 무엇을 의미하고 어떤 식으로 달성할 수 있는지 적절한 인사이트를 발굴할 수 있을 것으로 생각됩니다.
