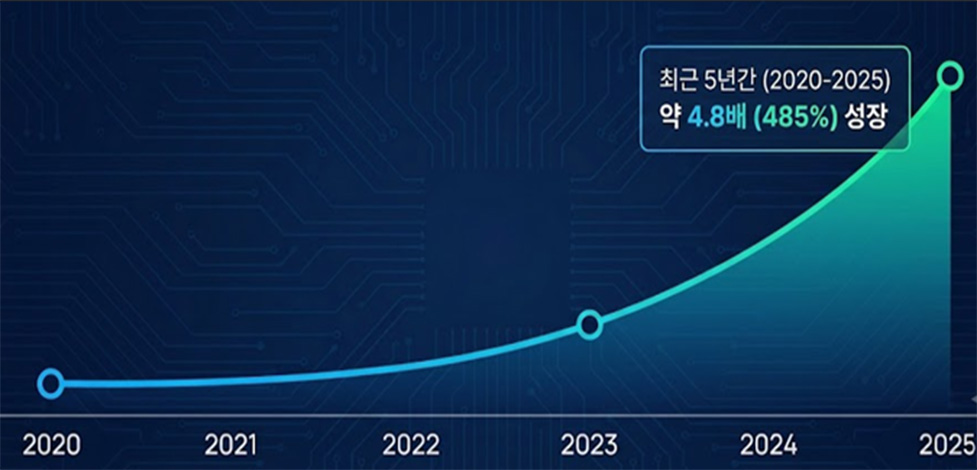
RAG(Retrieval Augmented Generation), 생성형 AI의 한계를 극복하다!
💫간추린 이야기
- 환각효과 멈춰!
- LLM을 구원하러 온 RAG
- RAG를 더 쉽게, Amazon Bedrock!
환각 효과 멈춰!🖐
2024년 가장 주목해야 할 AI 트렌드는 여전히 ‘생성형 AI’입니다. 특히 작년 11월 CahtGPT 가 출시된 이후 LLM(대규모언어모델) 분야의 눈부신 약진이 있었습니다. LLM은 방대한 양의 데이터를 학습하여 인간 수준의 언어 이해 및 텍스트 생성 능력을 갖추었습니다.
그러나 아직 우려의 목소리가 높은 것도 사실인데요, 그 이유는 LLM이 사실이 아니거나 근거가 없는 내용을 생성하기도 하기 때문입니다. 이는 환각 효과(Hallucination)라고 불리는 문제로, 생성형 AI를 상용화하는데 큰 걸림돌로 작용합니다. 비즈니스에서 정보의 정확성은 이루 말할 수 없이 중요하기 때문입니다.
LLM을 구원하러 온 RAG😇

이러한 한계를 극복하기 위한 중요한 기술이 있습니다. 바로 RAG(Retrieval Augmented Generation), 검색 증강 생성입니다. 검색 엔진을 활용하여 LLM이 생성하는 텍스트의 사실 여부를 검증하고, 검증된 정보를 바탕으로 텍스트를 생성하기 때문에 정확도가 매우 높아지게 됩니다.
지금 당신이 알아야 할 RAG 기술💻
RAG에 대한 이해를 돕기 위해 많이 사용되는 기술인 Embedding Model과 Vector Database에 대해 설명해 드리려고 합니다. Embedding Model은 단어, 문장, 이미지, 그래프 등의 데이터를 벡터로 변환하는 기술입니다. 벡터는 숫자의 배열로 표현되는데요, 이렇게 해야 이진법을 기반으로 하는 컴퓨터가 문장이나 단어의 의미를 잘 파악할 수 있습니다.
Vector Database는 앞서 벡터 Embedding Model로 변환한 데이터를 저장하고 검색하는 데이터베이스입니다. RAG는 이 데이터베이스에 저장된 정보를 바탕으로 데이터 간의 유사성을 효율적으로 계산하고 검색하여 LLM이 더욱 정확한 답변을 만들어내도록 돕는 것입니다.
Vector Database는 앞서 벡터 Embedding Model로 변환한 데이터를 저장하고 검색하는 데이터베이스입니다. RAG는 이 데이터베이스에 저장된 정보를 바탕으로 데이터 간의 유사성을 효율적으로 계산하고 검색하여 LLM이 더욱 정확한 답변을 만들어내도록 돕는 것입니다.

RAG를 더 쉽게, Amazon Bedrock!
RAG를 더욱 쉽게 수행할 수 있는 기술이 이번 re:Invent 2023에서 발표되었습니다. 바로 Knowledge Bases for Amazon Bedrock인데요, Amazon Bedrock의 Embedding Model과 연결하여 더욱 쉽게 다양한 데이터베이스를 Vector Database로 활용할 수 있는 기능입니다. 아직 Amazon Bedrock이 있는 리전에서만 이용이 가능해서 서울 리전에서는 사용을 할 수 없습니다.
그러나 PostgreSQL, OpenSearch 등에서도 Vector Store를 지원하므로 해당 데이터베이스는 서울 리전에서 이용 가능합니다. Amazon bedrock에서 Titan Text Embeddings와 Cohere의 Embed-v3 다국어 모델 또한 공식적으로 한국어를 지원합니다. 따라서 RAG 방식의 구현을 할 때 필요한 임베딩 모델을 손쉽게 Amazon Bedrock의 API 호출로 이용할 수 있습니다.
또한, 다국어 임베딩 모델이 아닌 한국어에 특화된 임베딩 모델 혹은 커스텀한 모델을 사용하는 것도 가능합니다. 이는 AWS 기술 블로그에 생성형 AI를 위한 Amazon SageMaker Endpoint 기반 임베딩 모델 배포에 관련된 자세한 글이 있으니 참고해보시면 좋을 것 같습니다.
마지막으로 RAG에 대해 자세하게 알고싶은 분들을 위해서 좋은 내용을 담고 있는 파이토치 한국 사용자 그룹의 글을 소개해 드립니다.
– 대규모 언어 모델을 위한 검색-증강 생성(RAG) 기술 현황 – 1/2편
– 대규모 언어 모델을 위한 검색-증강 생성(RAG) 기술 현황 – 2/2편
그러나 PostgreSQL, OpenSearch 등에서도 Vector Store를 지원하므로 해당 데이터베이스는 서울 리전에서 이용 가능합니다. Amazon bedrock에서 Titan Text Embeddings와 Cohere의 Embed-v3 다국어 모델 또한 공식적으로 한국어를 지원합니다. 따라서 RAG 방식의 구현을 할 때 필요한 임베딩 모델을 손쉽게 Amazon Bedrock의 API 호출로 이용할 수 있습니다.
또한, 다국어 임베딩 모델이 아닌 한국어에 특화된 임베딩 모델 혹은 커스텀한 모델을 사용하는 것도 가능합니다. 이는 AWS 기술 블로그에 생성형 AI를 위한 Amazon SageMaker Endpoint 기반 임베딩 모델 배포에 관련된 자세한 글이 있으니 참고해보시면 좋을 것 같습니다.
마지막으로 RAG에 대해 자세하게 알고싶은 분들을 위해서 좋은 내용을 담고 있는 파이토치 한국 사용자 그룹의 글을 소개해 드립니다.
– 대규모 언어 모델을 위한 검색-증강 생성(RAG) 기술 현황 – 1/2편
– 대규모 언어 모델을 위한 검색-증강 생성(RAG) 기술 현황 – 2/2편
💡 우리 회사의 데이터를 기반으로 한 ‘맞춤형 생성형 AI’, 어떻게 도입할 수 있을까요?
파인 튜닝 과정 없이 기업 내 데이터의 저장, 연결 만으로 우리 회사를 위한 ‘맞춤형 생성형 AI’를 쉽게 도입할 수 있는 방법, 여기 있습니다! 🖐️🖐️
RAG 파이프라인 구성 및 RAG 연계 프롬프트 엔지니어링을 통해 우리 회사에 최적화된 생성형 AI를 구축할 수 있는 ‘GenAI360’에 대해 확인해 보세요.
‘GenAI360’은 기업의 고유한 데이터를 기반으로 즉각적인 생성형 AI 활용이 가능하도록 대상 서비스 선정부터 모델 학습 및 운영 단계까지 지원하는, 메가존클라우드의 오퍼링 서비스입니다.
👉지금 바로 알아보기
RAG 파이프라인 구성 및 RAG 연계 프롬프트 엔지니어링을 통해 우리 회사에 최적화된 생성형 AI를 구축할 수 있는 ‘GenAI360’에 대해 확인해 보세요.
‘GenAI360’은 기업의 고유한 데이터를 기반으로 즉각적인 생성형 AI 활용이 가능하도록 대상 서비스 선정부터 모델 학습 및 운영 단계까지 지원하는, 메가존클라우드의 오퍼링 서비스입니다.
👉지금 바로 알아보기
본 콘텐츠는 메가존클라우드 Cloud Technology Center AI/ML팀 김현민 SA의 자문을 받아 작성하였습니다.
글 | 메가존클라우드 마케팅그룹 최은영 매니저
글 | 메가존클라우드 마케팅그룹 최은영 매니저
게시물 주소가 복사되었습니다.