[고객사례] 이투데이 | AWS 기반 생성형 AI로 10만 건의 사진 아카이브를 검색 자산으로 전환하다

Customer Story Detail
1. 언론사의 잠든 데이터에 생명력을 불어넣다
수십 년간 축적된 언론사의 방대한 보도 사진들. 하지만 기존의 단순 키워드 검색 환경에서는 “그때 그 느낌의 사진”을 찾기 위해 기자들이 수백 장의 폴더를 뒤져야만 하는 물리적 한계가 존재합니다.
메가존클라우드 미디어 유닛은 최근 12주간 진행된 ‘AWS Newsroom Jumpstart’ 프로젝트에서 고객사 ‘이투데이’와 함께 10만 건 이상의 레거시 보도 사진을 AI로 분석하고 의미론적 벡터로 변환하는 ‘생성형 AI 기반 하이브리드 검색 파이프라인’을 성공적으로 구축했습니다.
그 결과, 프로젝트 결과물과 기술 접근 방식을 인정받아 AWS Newsroom Jumpstart 최종 발표회에서 공동 2위(우수상)를 수상했습니다.
단순히 AI 모델을 연결하는 수준을 넘어, 10만 건 규모의 레거시 사진 데이터를 AI 검색 자산으로 전환하기 위해 적용한 AWS 기반 아키텍처 설계와 검색 품질 고도화 과정을 공유합니다.
2. 프로젝트 당면 과제: 대규모 데이터와 비용의 압박
이번 프로젝트는 단순히 최신 AI 모델을 도입하는 것을 넘어, 엔터프라이즈 환경에서 직면하는 세 가지 현실적인 허들을 극복해야 했습니다.
- 방대한 데이터 마이그레이션: 샘플 사진 기준, 10만 건에 달하는 레거시 사진 데이터와 파편화된 캡션/메타데이터를 무중단으로 AI 분석 및 재적재해야 하는 과제
- 하이브리드 검색의 딜레마: 단순 문맥 검색(벡터)만으로는 언론사 특유의 ‘정확한 인물명(키워드)’ 매칭이 떨어지므로, 고도화된 검색 엔진 필요
- 인프라 고정 비용의 한계: 보안을 위해 DB를 Private Subnet에 격리할 경우, 외부 AI 서비스(Bedrock 등)와 통신하기 위해 매월 NAT Gateway, VPC Endpoint 고정 비용이 발생한다는 딜레마
3. 비용 최적화를 고려한 클라우드 아키텍처 설계
클라우드 아키텍처의 가치는 성능, 운영성, 비용 효율성을 균형 있게 확보하는 데 있습니다. 본 프로젝트에서는 생성형 AI 서비스와 Private 환경의 OpenSearch를 함께 활용해야 하는 구조적 제약을 해결하기 위해 파이프라인을 역할별로 분리하여 설계했습니다.
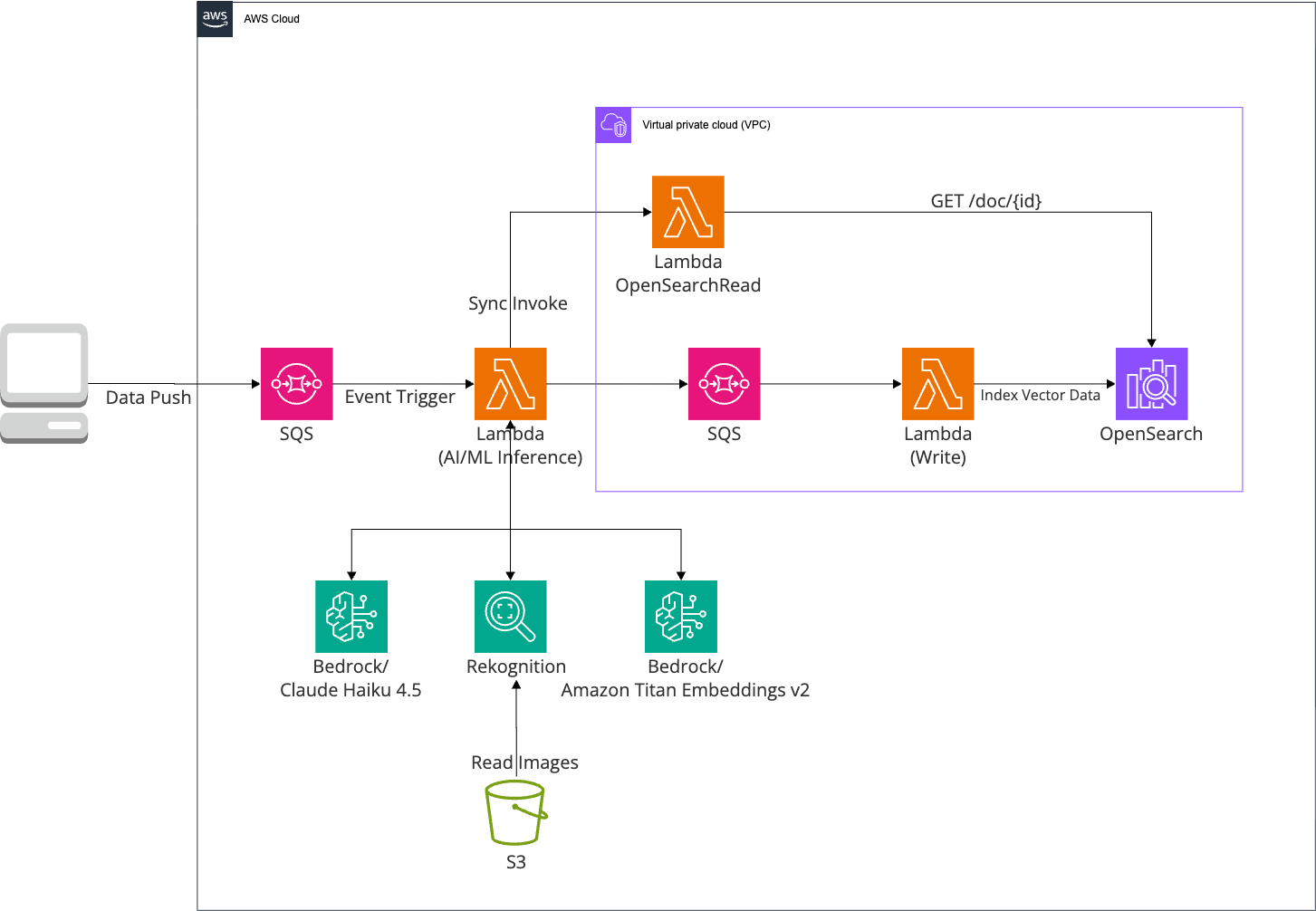
위 아키텍처는 전체 시스템 중 10만 건 레거시 사진 마이그레이션(AI 분석, 벡터화, 적재) 단계만을 나타내며, 인물 도감 구축 및 검색 아키텍처는 별도로 다룹니다.
하이브리드 네트워크 분리를 통한 비용 효율화
보안 요구사항과 AWS AI 서비스 연동을 동시에 충족하기 위해 Lambda 함수를 역할별로 분리했습니다. 외부망에 위치한 Lambda는 Amazon Bedrock, Amazon Rekognition 등 AI 서비스를 호출하고, 내부망(Private Subnet)에 위치한 Lambda는 OpenSearch read 및 적재만 담당하도록 구성했습니다. 두 Lambda 간 통신은 AWS 내부 Invoke 방식으로 처리하여 NAT Gateway 의존도를 제거했고, 추가 네트워크 구성 없이도 안정적인 데이터 처리 구조를 구현할 수 있었습니다.
SQS & DLQ 기반의 대규모 비동기 처리
10만 건 규모의 사진 데이터를 일괄 처리하는 과정에서는 AI 모델 호출에 따른 일시적인 병목 현상이 발생할 수 있습니다. 이를 해결하기 위해 AI 분석 단계와 OpenSearch 적재 단계를 Amazon SQS로 분리하여 비동기 처리 구조를 구성했습니다. 또한 실패한 메시지는 DLQ(Dead Letter Queue)로 자동 분리하여 재처리가 가능하도록 설계함으로써 대량 데이터 처리 과정에서도 안정성을 확보했습니다.
512차원 임베딩을 활용한 저장 공간 최적화
벡터 검색에서는 임베딩 차원이 높을수록 저장 공간과 검색 비용이 증가합니다. 본 프로젝트에서는 Amazon Titan Text Embeddings V2의 가변 차원 기능을 활용하여 512차원 임베딩을 적용했습니다. 내부 테스트 결과, 검색 품질 저하는 최소화하면서도 벡터 데이터 저장 용량을 크게 줄일 수 있었으며, 이를 통해 OpenSearch 운영 비용까지 함께 최적화할 수 있었습니다
실제 10만 건 규모의 사진 마이그레이션 과정에서 Amazon Rekognition, Amazon Bedrock, AWS Lambda 등을 활용한 전체 AI 분석 비용은 약 900~1,000달러 수준으로 확인되었습니다. 이를 통해 대규모 언론사 사진 아카이브를 AI 검색 자산으로 전환하는 작업 역시 충분히 현실적인 비용 범위 내에서 수행 가능함을 검증할 수 있었습니다.
4. 생성형 AI와 검색 엔진의 융합
단순히 이미지를 벡터화하는 것만으로는 언론사 환경에서 만족스러운 검색 품질을 얻기 어려웠습니다. 사진 속 인물, 기사 문맥, 기존 캡션 정보 등 다양한 데이터를 함께 활용해야 실제 기자들이 원하는 결과를 찾을 수 있기 때문입니다. 이번 프로젝트에서는 이투데이 현업 기자들의 업무 방식과 검색 패턴을 분석하여, 이미지 분석부터 요약 생성, 벡터 검색까지 이어지는 End-to-End AI 파이프라인을 구축했습니다.
Amazon Rekognition 기반 시각 정보 추출
보도 사진에는 기존 캡션만으로 설명되지 않는 다양한 시각 정보가 포함되어 있습니다. 먼저 Amazon Rekognition DetectLabels를 활용하여 사진 속 객체, 장소, 활동 정보 등을 자동으로 추출하고, 이를 검색 가능한 메타데이터로 변환했습니다.
인물 인식의 경우, “누가 사진에 등장했는가”까지 정확하게 매칭할 수 있는 구조가 필요했습니다. 이를 위해 이투데이가 보유한 주요 인물 데이터를 기반으로 Rekognition Collection을 구성하고, IndexFaces와 CreateUser, AssociateFaces를 통해 인물별 얼굴 정보를 등록한 ‘인물 도감’을 사전에 구축했습니다. 이후 10만 건의 사진 데이터에 SearchUsersByImage를 적용하여, 사진 속 인물이 도감에 등록된 누구인지 자동으로 식별하고 이를 검색 메타데이터로 변환했습니다.
특히 프로젝트 진행 과정에서 이투데이 실무진은 “군중 사진의 경우 모든 인물을 나열하기보다 사진의 핵심 인물을 중심으로 검색되는 것이 실제 업무에 더 유용하다”는 요구사항을 제시했습니다. 이를 반영하여 DetectFaces 기반으로 사진 속 인물 수와 구성에 따라 주요 인물을 선별하는 로직을 설계했고, 해당 결과를 이후 검색 파이프라인의 핵심 데이터로 활용했습니다.
Amazon Bedrock 기반 검색 요약문 생성
레거시 사진 데이터에는 수년간 축적된 캡션과 기사 정보가 존재하지만, 데이터 품질과 표현 방식은 사진마다 크게 달랐습니다. 이를 보완하기 위해 Amazon Bedrock에서 제공하는 Claude Haiku 4.5 모델을 활용했습니다. 기존 캡션, 키워드, Rekognition 분석 결과를 하나의 프롬프트로 결합하여 검색에 최적화된 통합 요약문을 생성했습니다. 이를 통해 단순 키워드 검색뿐 아니라 문맥 기반 검색과 의미 기반 검색에서도 활용할 수 있는 고품질 텍스트 데이터를 확보할 수 있었습니다.
Titan Embeddings 기반 벡터 변환
생성된 검색 요약문은 Amazon Titan Text Embeddings v2를 활용하여 벡터로 변환했습니다. 기존 키워드 검색은 정확히 일치하는 단어를 찾아야 하지만, 벡터 검색은 문장의 의미 자체를 수치화하기 때문에 유사한 문맥까지 함께 탐색할 수 있습니다. 예를 들어 기자가 “경제 정책 발표”를 검색했을 때, 실제 데이터에는 “경제 활성화 대책 브리핑”으로 저장되어 있더라도 의미적으로 유사한 결과를 찾을 수 있도록 설계했습니다.
Amazon OpenSearch 기반 하이브리드 검색
최종적으로 생성된 텍스트 데이터와 벡터 데이터는 Amazon OpenSearch에 저장됩니다. 검색 시에는 BM25 기반 키워드 검색과 벡터 기반 k-NN 검색을 함께 수행하는 하이브리드 검색 방식을 적용했습니다. 이를 통해 인물명과 같은 정확한 키워드 검색 성능은 유지하면서도, 기사 문맥이나 장면 설명과 같은 의미 기반 검색까지 지원할 수 있었습니다. 또한 벡터 검색 성능 최적화를 위해 HNSW(Hierarchical Navigable Small World) 알고리즘 기반 인덱스를 적용하여, 10만 건 이상의 사진 데이터에서도 밀리초(ms) 단위의 응답 속도를 확보했습니다.
5. 프로젝트 성과 및 비즈니스 임팩트


성공적인 아키텍처 검증 및 우수상 수상
10만 건 규모의 레거시 사진 데이터를 대상으로 AI 기반 분석, 벡터화, 검색 파이프라인을 구축하고 검증했습니다. 프로젝트 결과물과 기술 구현 방식은 AWS Newsroom Jumpstart 심사 과정에서 긍정적인 평가를 받았으며, 최종적으로 공동 2위(우수상)를 수상했습니다.
현업 기자와 함께 검증한 검색 품질
프로젝트 기간 동안 이투데이 현업 기자들과 함께 실제 업무 환경을 기반으로 검색 품질을 지속적으로 검증했습니다. 단순 키워드 검색을 넘어 인물 검색, 행사 검색, 기사 문맥 검색 등 다양한 시나리오를 함께 테스트하며 검색 품질을 개선해 나갔고, 현업 활용 가능성을 확인할 수 있었습니다.
API 기반 확장 구조 확보
검색 기능은 API Gateway와 Lambda 기반으로 설계되어 향후 고객사의 CMS, 웹 서비스, 애플리케이션 등 다양한 채널과 손쉽게 연계할 수 있도록 구성했습니다. 이를 통해 AI 검색 기능을 특정 플랫폼에 종속되지 않는 형태로 제공할 수 있는 기반을 마련했습니다.
AI 기반 미디어 서비스로의 확장 가능성 확보
이번 프로젝트를 통해 사진 아카이브를 단순 보관 데이터가 아닌 검색 가능한 AI 자산으로 전환할 수 있음을 확인했습니다. 또한 향후 AI 기반 사진 추천, 자동 메타데이터 생성, 유사 이미지 검색 등 다양한 미디어 서비스로 확장할 수 있는 기술적 기반도 함께 확보했습니다.
메가존클라우드 미디어 유닛은 고객사의 현업 경험과 AWS 클라우드 기술을 결합하여 실제 업무에 활용 가능한 AI 서비스를 함께 만들어가고 있습니다. 특히 이번 프로젝트는 고객사 실무진과 메가존클라우드가 함께 검색 품질을 개선하고 비즈니스 요구사항을 시스템에 반영하며 완성해 나간 협업 사례였습니다.
앞으로도 미디어 고객의 데이터 자산이 새로운 가치를 창출할 수 있도록 기술 파트너로서 지속적인 혁신을 이어가겠습니다.
✍️ 글 ㅣMedia Unit 김지혜 매니저