
[AWS SUMMIT 2025] Amazon SageMaker로 LLM 배포, 개발은 간편하게 응답은 빠르게!

들어가며
Amazon SageMaker로 LLM 배포, 개발은 간편하게 응답은 빠르게!
🎙️전현상 솔루션즈 아키텍트, AWS
🎙️이광우 솔루션즈 아키텍트, AWS
🗂️ 세션 토픽: 생성형 AI 및 머신러닝 응요
2025년 현재, LLM(Large Language Model, 대규모 언어 모델)은 기업 환경에 빠르게 도입되고 있습니다. 챗봇, 문서 요약, 코드 생성 등 다양한 분야에서 LLM이 활용되고 있지만, 성능과 비용 효율성 측면에서 그만큼 기업들의 고민도 커져가고 있습니다.
해당 세션에서는 이러한 문제를 해결하기 위한 아마존의 접근 방식을 소개합니다. LLM 기반 서비스 운영에 있어 SageMaker라는 서비스가 어떤 기술적 유연성과 운영 편의성을 제공하는지, 그리고 대규모 운영 환경에서 어떻게 실질적인 가치로 이어질 수 있는지를 알아보겠습니다.
SageMaker: LLM 배포를 위한 올인원 플랫폼

Amazon SageMaker는 ML 모델의 학습부터 추론까지 전 과정을 관리할 수 있는 완전관리형 플랫폼입니다. 해당 세션에서는 특히 SageMaker가 LLM에 특화된 기능들을 어떻게 제공하는지 소개했는데요, 대표적으로 다음과 같은 이점이 있습니다.
– 단일 플랫폼에서 개발, 학습, 배포 관리
– 자동 확장(Auto Scaling) 및 엔드포인트 기반 추론 서비스
– 모델 모니터링, A/B 테스트, 버전 관리 등 배포 편의성
이러한 특징은 특히 실시간 응답이 중요한 LLM 기반 서비스에서 큰 가치를 발휘합니다. 사용자가 질문을 입력하고 몇 초 이상 기다려야 한다면, 아무리 정확한 답변이라도 사용자 경험은 크게 저하되기 때문입니다.
성능을 위한 하드웨어 최적화 전략

LLM은 수십억 개 이상의 파라미터를 가지고 있기 때문에, 실시간 응답을 위해선 매우 빠르고 효율적인 하드웨어가 필요합니다. 따라서 LLM의 성능을 최적화하기 위해선 다방면의 전략이 필요합니다.
AWS에서는 ‘컴파일(Compilation)’이라는 과정을 통해 모델을 실행할 하드웨어에 맞게 최적화합니다. 이 과정을 거치면 동일한 모델도 훨씬 더 빠르게, 효율적으로 작동할 수 있습니다. 더 나아가 AWS는 AI 워크로드에 특화된 자체 개발 칩을 제공합니다
– ‘Trainium’: 모델 학습에 최적화된 칩으로, 일반 GPU보다 더 저렴한 비용으로 대규모 학습 작업 수행 가능합니다.
– ‘Inferentia’: 추론(실제 서비스) 단계에 최적화된 칩으로, 빠른 응답 속도가 필요한 실시간 서비스에 적합합니다.

하드웨어 최적화와 더불어, 소프트웨어 차원의 최적화도 중요합니다. 그 중 하나가 ‘롤링 배치(Rolling Batch)’ 기법입니다. 이는 여러 사용자의 요청을 한꺼번에 처리함으로써 GPU의 유휴 시간을 최소화하는 방식입니다.
이러한 하드웨어와 소프트웨어 최적화 기술을 함께 활용하면, 비용은 절감하면서도 사용자에게 빠른 응답을 제공하는 LLM 서비스를 구축할 수 있습니다.
LLM 기반 챗봇 운영을 위한 세션 관리 기법
LLM 기반 챗봇에서 가장 중요한 것 중 하나는 ‘대화의 맥락(context)’을 유지하는 것입니다. 예를 들어, “어제 왔던 그 사람은 누구였어?”라는 질문에 올바르게 답하려면 이전 대화 내용을 기억하고 있어야 합니다.
이를 위해 SageMaker에서는 세션 기반 라우팅(Sticky Session) 기능을 제공하는데요, 이 기술은 다음과 같이 작동합니다.
– 같은 사용자, 같은 서버: 동일한 사용자의 모든 요청을 항상 같은 모델 인스턴스로 보내 대화 맥락을 유지
– 인메모리 캐싱: 이전 대화 내용을 메모리에 저장해 빠르게 접근
– 세션 ID 기반 라우팅: 사용자마다 고유한 세션 ID를 부여하여 요청을 적절히 분배
이 기능을 활용하면 사용자는 마치 한 사람과 계속 대화하는 것 같은 자연스러운 경험을 얻을 수 있습니다. 또한 맥락 정보를 매번 전송하지 않아도 되기 때문에 네트워크 부하도 줄일 수 있습니다.
실제 사례: Capital One의 SageMaker 기반 LLM 서비스
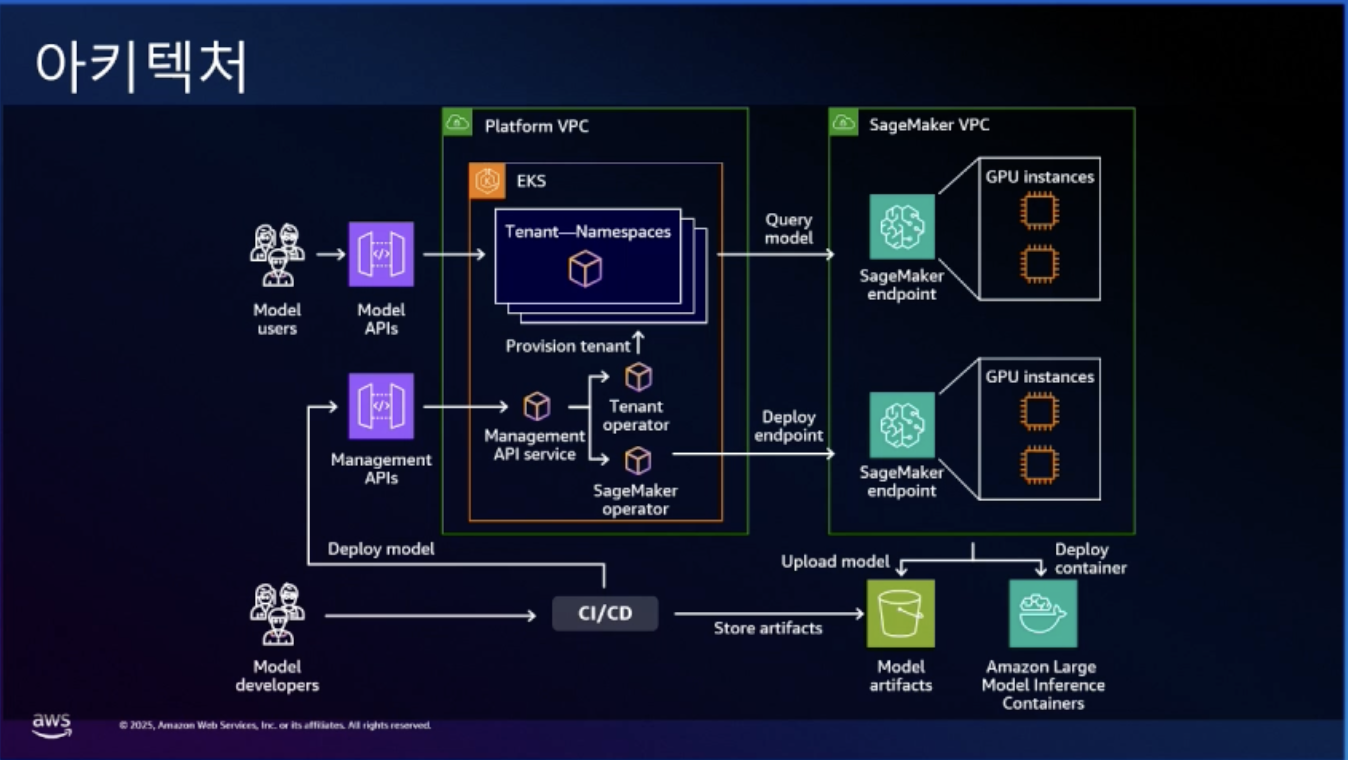
고객 서비스와 내부 업무 효율화를 위해 LLM 기반 서비스를 도입한 미국의 금융 기업 Capital One의 사례를 살펴보겠습니다.
모델 사용자는 외부 또는 내부에서 Model APIs를 통해 LLM에 접근합니다. 이 요청은 EKS 기반의 플랫폼 환경 안에 있는 Tenant별 네임스페이스 구조로 관리되며, Tenant별 네임스페이스 구조를 통해 각 서비스나 부서별로 독립된 환경을 제공합니다.
모델 배포 과정은 CI/CD 파이프라인을 통해 자동화되어 있습니다. 개발팀이 새 모델을 개발하면, 자동으로 테스트되고 승인 절차를 거쳐 프로덕션 환경에 배포됩니다. 이때 모델 파일은 Amazon S3에 저장되고, SageMaker가 이를 불러와 서비스로 제공합니다.
SageMaker 내부에서는 학습(Training)과 추론(Inference) 작업이 각각 분리된 GPU 인스턴스에서 실행됩니다. 이를 통해 각 작업에 최적화된 환경을 구성하고 자원을 효율적으로 활용할 수 있습니다.
실제 서비스 단계에서는 SageMaker Endpoint를 통해 추론 요청이 처리되며, 트래픽 증가에 따라 자동 스케일링 기능이 작동합니다. 또한 대용량 데이터 처리를 위해 Amazon EFS와 같은 공유 스토리지가 연동되어, 모델 로딩과 결과 저장의 효율성을 높입니다.
이러한 구조 덕분에 Capital One은 개발자에게는 쉽고 빠른 모델 배포 환경을, 사용자에게는 지연 없는 응답 경험을 제공할 수 있었습니다.
마무리하며: 솔루션 아키텍트로서의 시사점
해당 세션에서 인상 깊었던 점은, 단순히 최신 AI 기술을 소개하는 것이 아니라 실제 비즈니스 환경에서 LLM을 어떻게 효과적으로 운영할 것인가에 초점을 맞췄다는 것입니다.
1. 운영 효율과 성능 최적화의 균형
Capital One 사례에서 보았듯, 성능 좋은 모델을 쓰는 것만큼이나 중요한 것은 이를 얼마나 안정적으로 배포하고, 운영 상에서 병목을 최소화하느냐입니다. . Trainium, Inferentia와 같은 특화된 하드웨어와 롤링 배치 같은 소프트웨어 최적화 기술은 응답 속도와 비용 효율성 사이의 균형을 맞추는 핵심이었습니다.
2. 사용자 경험을 위한 인프라 설계의 중요성
세션 기반 라우팅(Sticky Session)과 같은 기능은 모델 자체의 성능이 아니라, 사용자 관점에서 더 자연스럽고 맥락 있는 대화를 가능하게 하는 중요한 설계 포인트입니다. 이는 모델을 단순히 돌리는 데 그치지 않고, 서비스 전반의 UX까지 고려한 운영 전략이라 볼 수 있습니다.
LLM을 도입하고자 고민하는 기업이나 팀에게 해당 세션은 매우 실질적인 가이드를 제시해주며, AI 시스템의 도입과 운영 사이에서 균형을 찾으려는 분들에게 유용한 인사이트가 되었으리라 생각합니다. 이 글을 읽고 계신 여러분도 SageMaker와 같은 플랫폼을 통해 기술 도입을 넘어 운영 최적화까지 고려한 LLM 전략을 구상해보시길 권합니다.
글 │ 메가존클라우드, Cloud Technology Unit, AWS Delivery SA 4팀, 최세민 SA
AWS SUMMIT 2025
전문가의 시선으로 정리된 테크 블로그를 통해
2025년 IT 트렌드의 현재와 미래를 살펴보세요.
테크 블로그 목차 (바로 가기→)
![[유럽 이야기] 소버린 클라우드(Sovereign Cloud)](https://img.iting.co.kr/wp-content/uploads/2026/02/GettyImages-a13565934.jpg)
![[미국 이야기] 골든 돔(Golden Dome)이 한국 AI시장에 미치는 영향에 대하여](https://img.iting.co.kr/wp-content/uploads/2025/01/USA_thumbnail_GettyImagesEdge_Editor_Cut_1454217037.png)
